 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear-Time and Constant-Memory Text Embeddings Based on Recurrent Language Models
Apr 20, 2026Transformer-based embedding models suffer from quadratic computational and linear memory complexity, limiting their utility for long sequences. We propose recurrent architectures as an efficient alternative, introducing a vertically chunked inference strategy that enables fast embedding generation with memory usage that becomes constant in the input length once it exceeds the vertical chunk size. By fine-tuning Mamba2 models, we demonstrate their viability as general-purpose text embedders, achieving competitive performance across a range of benchmarks while maintaining a substantially smaller memory footprint compared to transformer-based counterparts. We empirically validate the applicability of our inference strategy to Mamba2, RWKV, and xLSTM models, confirming consistent runtime-memory trade-offs across architectures and establishing recurrent models as a compelling alternative to transformers for efficient embedding generation.
Differentiable Reasoning about Knowledge Graphs with Region-based Graph Neural Networks
Jun 13, 2024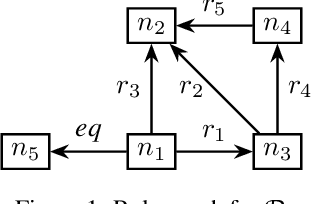

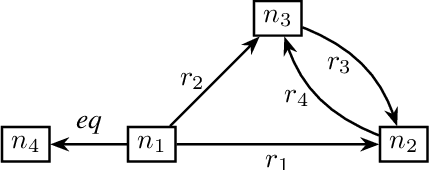

Methods for knowledge graph (KG) completion need to capture semantic regularities and use these regularities to infer plausible knowledge that is not explicitly stated. Most embedding-based methods are opaque in the kinds of regularities they can capture, although region-based KG embedding models have emerged as a more transparent alternative. By modeling relations as geometric regions in high-dimensional vector spaces, such models can explicitly capture semantic regularities in terms of the spatial arrangement of these regions. Unfortunately, existing region-based approaches are severely limited in the kinds of rules they can capture. We argue that this limitation arises because the considered regions are defined as the Cartesian product of two-dimensional regions. As an alternative, in this paper, we propose RESHUFFLE, a simple model based on ordering constraints that can faithfully capture a much larger class of rule bases than existing approaches. Moreover, the embeddings in our framework can be learned by a monotonic Graph Neural Network (GNN), which effectively acts as a differentiable rule base. This approach has the important advantage that embeddings can be easily updated as new knowledge is added to the KG. At the same time, since the resulting representations can be used similarly to standard KG embeddings, our approach is significantly more efficient than existing approaches to differentiable reasoning.
Ontological Reasoning over Shy and Warded Datalog$+/-$ for Streaming-based Architectures (technical report)
Nov 20, 2023



Recent years witnessed a rising interest towards Datalog-based ontological reasoning systems, both in academia and industry. These systems adopt languages, often shared under the collective name of Datalog$+/-$, that extend Datalog with the essential feature of existential quantification, while introducing syntactic limitations to sustain reasoning decidability and achieve a good trade-off between expressive power and computational complexity. From an implementation perspective, modern reasoners borrow the vast experience of the database community in developing streaming-based data processing systems, such as volcano-iterator architectures, that sustain a limited memory footprint and good scalability. In this paper, we focus on two extremely promising, expressive, and tractable languages, namely, Shy and Warded Datalog$+/-$. We leverage their theoretical underpinnings to introduce novel reasoning techniques, technically, "chase variants", that are particularly fit for efficient reasoning in streaming-based architectures. We then implement them in Vadalog, our reference streaming-based engine, to efficiently solve ontological reasoning tasks over real-world settings.
Fine-tuning Large Enterprise Language Models via Ontological Reasoning
Jun 19, 2023


Large Language Models (LLMs) exploit fine-tuning as a technique to adapt to diverse goals, thanks to task-specific training data. Task specificity should go hand in hand with domain orientation, that is, the specialization of an LLM to accurately address the tasks of a given realm of interest. However, models are usually fine-tuned over publicly available data or, at most, over ground data from databases, ignoring business-level definitions and domain experience. On the other hand, Enterprise Knowledge Graphs (EKGs) are able to capture and augment such domain knowledge via ontological reasoning. With the goal of combining LLM flexibility with the domain orientation of EKGs, we propose a novel neurosymbolic architecture that leverages the power of ontological reasoning to build task- and domain-specific corpora for LLM fine-tuning.
Swift Markov Logic for Probabilistic Reasoning on Knowledge Graphs
Oct 01, 2022
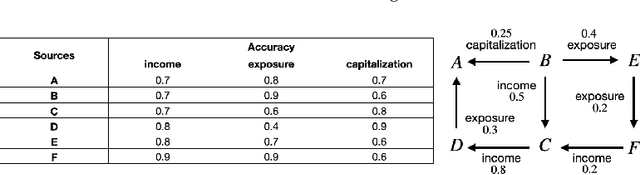

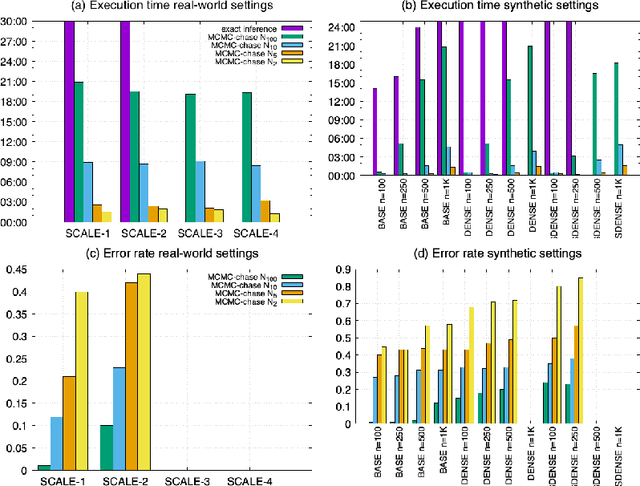
We provide a framework for probabilistic reasoning in Vadalog-based Knowledge Graphs (KGs), satisfying the requirements of ontological reasoning: full recursion, powerful existential quantification, expression of inductive definitions. Vadalog is a Knowledge Representation and Reasoning (KRR) language based on Warded Datalog+/-, a logical core language of existential rules, with a good balance between computational complexity and expressive power. Handling uncertainty is essential for reasoning with KGs. Yet Vadalog and Warded Datalog+/- are not covered by the existing probabilistic logic programming and statistical relational learning approaches for several reasons, including insufficient support for recursion with existential quantification, and the impossibility to express inductive definitions. In this work, we introduce Soft Vadalog, a probabilistic extension to Vadalog, satisfying these desiderata. A Soft Vadalog program induces what we call a Probabilistic Knowledge Graph (PKG), which consists of a probability distribution on a network of chase instances, structures obtained by grounding the rules over a database using the chase procedure. We exploit PKGs for probabilistic marginal inference. We discuss the theory and present MCMC-chase, a Monte Carlo method to use Soft Vadalog in practice. We apply our framework to solve data management and industrial problems, and experimentally evaluate it in the Vadalog system. Under consideration in Theory and Practice of Logic Programming (TPLP).
ExpressivE: A Spatio-Functional Embedding For Knowledge Graph Completion
Jun 08, 2022
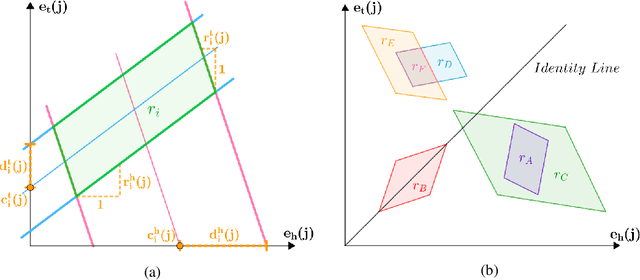
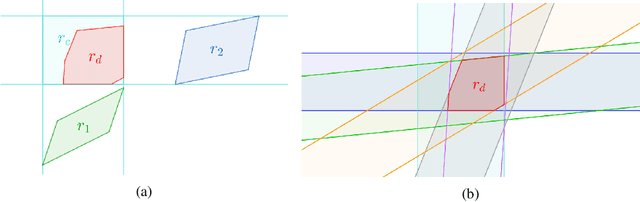

Knowledge graphs are inherently incomplete. Therefore substantial research has been directed towards knowledge graph completion (KGC), i.e., predicting missing triples from the information represented in the knowledge graph (KG). Embedding models have yielded promising results for KGC, yet any current KGC embedding model is incapable of: (1) fully capturing vital inference patterns (e.g., composition), (2) capturing prominent logical rules jointly (e.g., hierarchy and composition), and (3) providing an intuitive interpretation of captured patterns. In this work, we propose ExpressivE, a fully expressive spatio-functional embedding model that solves all these challenges simultaneously. ExpressivE embeds pairs of entities as points and relations as hyper-parallelograms in the virtual triple space $\mathbb{R}^{2d}$. This model design allows ExpressivE not only to capture a rich set of inference patterns jointly but additionally to display any supported inference pattern through the spatial relation of hyper-parallelograms, offering an intuitive and consistent geometric interpretation of ExpressivE embeddings and their captured patterns. Experimental results on standard KGC benchmarks reveal that ExpressivE is competitive with state-of-the-art models and even significantly outperforms them on WN18RR.
On the Relationship between Shy and Warded Datalog+/-
Feb 13, 2022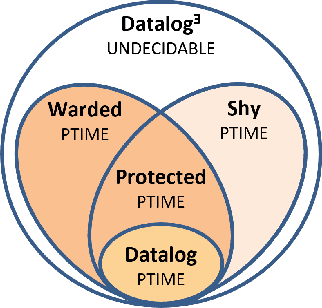
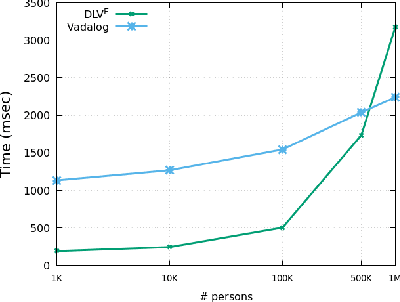
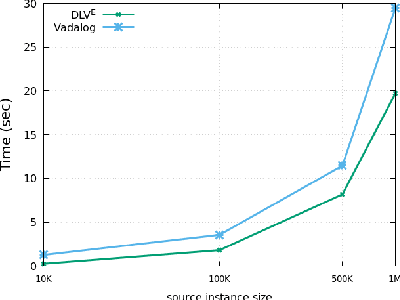
Datalog^E is the extension of Datalog with existential quantification. While its high expressive power, underpinned by a simple syntax and the support for full recursion, renders it particularly suitable for modern applications on knowledge graphs, query answering (QA) over such language is known to be undecidable in general. For this reason, different fragments have emerged, introducing syntactic limitations to Datalog^E that strike a balance between its expressive power and the computational complexity of QA, to achieve decidability. In this short paper, we focus on two promising tractable candidates, namely Shy and Warded Datalog+/-. Reacting to an explicit interest from the community, we shed light on the relationship between these fragments. Moreover, we carry out an experimental analysis of the systems implementing Shy and Warded, respectively DLV^E and Vadalog.
Complexity of Arithmetic in Warded Datalog+-
Feb 10, 2022Warded Datalog+- extends the logic-based language Datalog with existential quantifiers in rule heads. Existential rules are needed for advanced reasoning tasks, e.g., ontological reasoning. The theoretical efficiency guarantees of Warded Datalog+- do not cover extensions crucial for data analytics, such as arithmetic. Moreover, despite the significance of arithmetic for common data analytic scenarios, no decidable fragment of any Datalog+- language extended with arithmetic has been identified. We close this gap by defining a new language that extends Warded Datalog+- with arithmetic and prove its P-completeness. Furthermore, we present an efficient reasoning algorithm for our newly defined language and prove descriptive complexity results for a recently introduced Datalog fragment with integer arithmetic, thereby closing an open question. We lay the theoretical foundation for highly expressive Datalog+- languages that combine the power of advanced recursive rules and arithmetic while guaranteeing efficient reasoning algorithms for applications in modern AI systems, such as Knowledge Graphs.
Query Evaluation in DatalogMTL -- Taming Infinite Query Results
Sep 21, 2021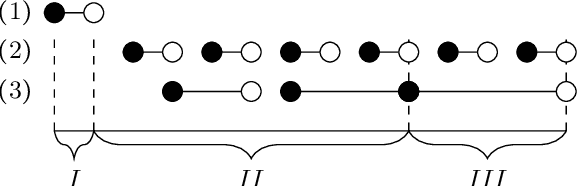
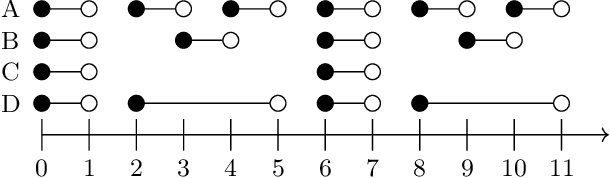
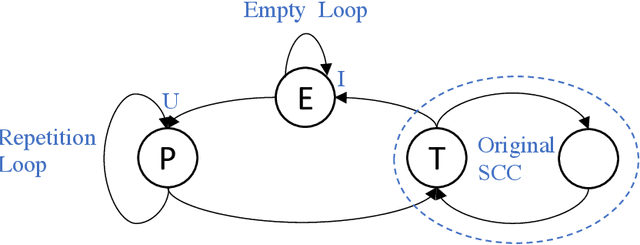
In this paper, we investigate finite representations of DatalogMTL. First, we introduce programs that have finite models and propose a toolkit for structuring the execution of DatalogMTL rules into sequential phases. Then, we study infinite models that eventually become constant and introduce sufficient criteria for programs that allow for such representation. We proceed by considering infinite models that are eventually periodic and show that such a representation encompasses all DatalogMTLFP programs, a widely discussed fragment. Finally, we provide a novel algorithm for reasoning over finite representable DatalogMTL programs that incorporates all of the previously discussed representations.
Harmless but Useful: Beyond Separable Equality Constraints in Datalog+/-
May 24, 2021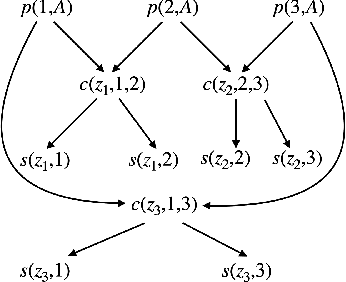
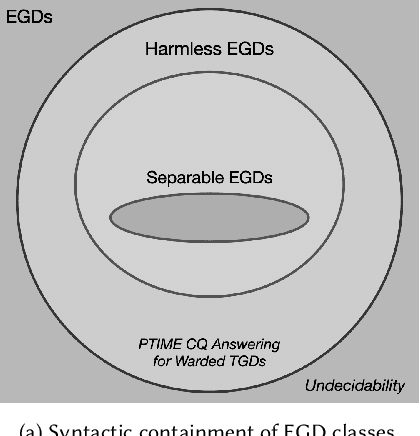
Ontological query answering is the problem of answering queries in the presence of schema constraints representing the domain of interest. Datalog+/- is a common family of languages for schema constraints, including tuple-generating dependencies (TGDs) and equality-generating dependencies (EGDs). The interplay of TGDs and EGDs leads to undecidability or intractability of query answering when adding EGDs to tractable Datalog+/- fragments, like Warded Datalog+/-, for which, in the sole presence of TGDs, query answering is PTIME in data complexity. There have been attempts to limit the interaction of TGDs and EGDs and guarantee tractability, in particular with the introduction of separable EGDs, to make EGDs irrelevant for query answering as long as the set of constraints is satisfied. While being tractable, separable EGDs have limited expressive power. We propose a more general class of EGDs, which we call ``harmless'', that subsume separable EGDs and allow to model a much broader class of problems. Unlike separable EGDs, harmless EGDs, besides enforcing ground equality constraints, specialize the query answer by grounding or renaming the labelled nulls introduced by existential quantification in the TGDs. Harmless EGDs capture the cases when the answer obtained in the presence of EGDs is less general than the one obtained with TGDs only. We conclude that the theoretical problem of deciding whether a set of constraints contains harmless EGDs is undecidable. We contribute a sufficient syntactic condition characterizing harmless EGDs, broad and useful in practice. We focus on Warded Datalog+/- with harmless EGDs and argue that, in such fragment, query answering is decidable and PTIME in data complexity. We study chase-based techniques for query answering in Warded Datalog+/- with harmless EGDs, conducive to an efficient algorithm to be implemented in state-of-the-art reasoners.