 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwift Markov Logic for Probabilistic Reasoning on Knowledge Graphs
Oct 01, 2022
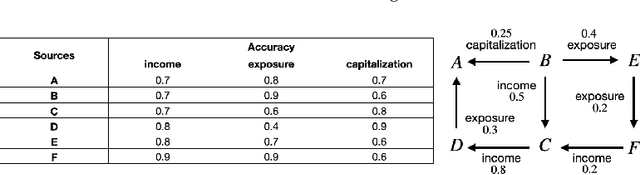

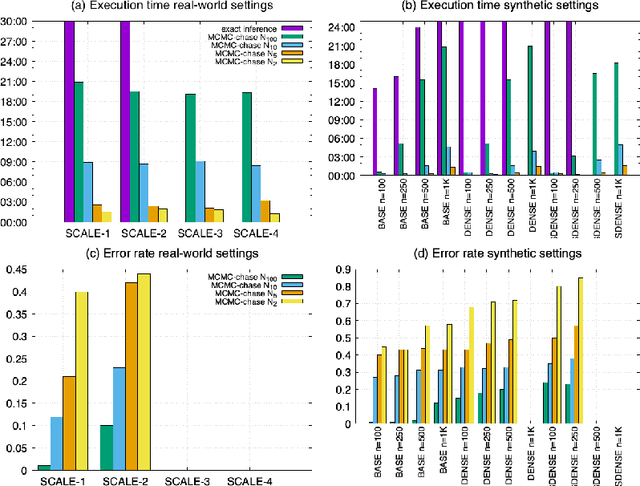
We provide a framework for probabilistic reasoning in Vadalog-based Knowledge Graphs (KGs), satisfying the requirements of ontological reasoning: full recursion, powerful existential quantification, expression of inductive definitions. Vadalog is a Knowledge Representation and Reasoning (KRR) language based on Warded Datalog+/-, a logical core language of existential rules, with a good balance between computational complexity and expressive power. Handling uncertainty is essential for reasoning with KGs. Yet Vadalog and Warded Datalog+/- are not covered by the existing probabilistic logic programming and statistical relational learning approaches for several reasons, including insufficient support for recursion with existential quantification, and the impossibility to express inductive definitions. In this work, we introduce Soft Vadalog, a probabilistic extension to Vadalog, satisfying these desiderata. A Soft Vadalog program induces what we call a Probabilistic Knowledge Graph (PKG), which consists of a probability distribution on a network of chase instances, structures obtained by grounding the rules over a database using the chase procedure. We exploit PKGs for probabilistic marginal inference. We discuss the theory and present MCMC-chase, a Monte Carlo method to use Soft Vadalog in practice. We apply our framework to solve data management and industrial problems, and experimentally evaluate it in the Vadalog system. Under consideration in Theory and Practice of Logic Programming (TPLP).
Enriching a Fashion Knowledge Graph from Product Textual Descriptions
Jun 02, 2022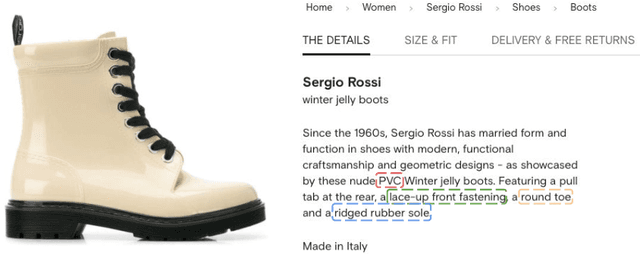
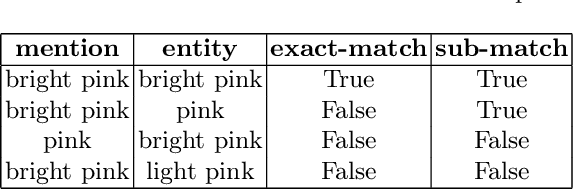

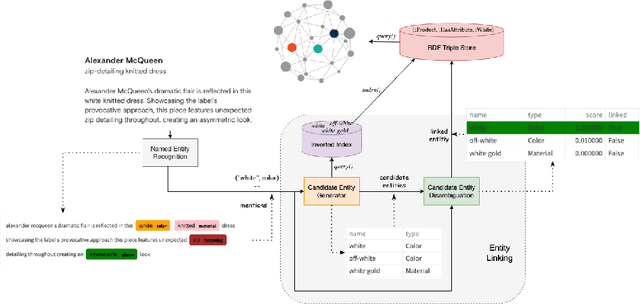
Knowledge Graphs offer a very useful and powerful structure for representing information, consequently, they have been adopted as the backbone for many applications in e-commerce scenarios. In this paper, we describe an application of existing techniques for enriching thelarge-scale Fashion Knowledge Graph (FKG) that we build at Farfetch. In particular, we apply techniques for named entity recognition (NER) and entity linking (EL) in order to extract and link rich metadata from product textual descriptions to entities in the FKG. Having a complete and enriched FKG as an e-commerce backbone can have a highly valuable impact on downstream applications such as search and recommendations. However, enriching a Knowledge Graph in the fashion domain has its own challenges. Data representation is different from a more generic KG, like Wikidata and Yago, as entities (e.g. product attributes) are too specific to the domain, and long textual descriptions are not readily available. Data itself is also scarce, as labelling datasets to train supervised models is a very laborious task. Even more, fashion products display a high variability and require an intricate ontology of attributes to link to. We use a transfer learning based approach to train an NER module on a small amount of manually labeled data, followed by an EL module that links the previously identified named entities to the appropriate entities within the FKG. Experiments using a pre-trained model show that it is possible to achieve 89.75% accuracy in NER even with a small manually labeled dataset. Moreover, the EL module, despite relying on simple rule-based or ML models (due to lack of training data), is able to link relevant attributes to products, thus automatically enriching the FKG.
Data Science with Vadalog: Bridging Machine Learning and Reasoning
Jul 23, 2018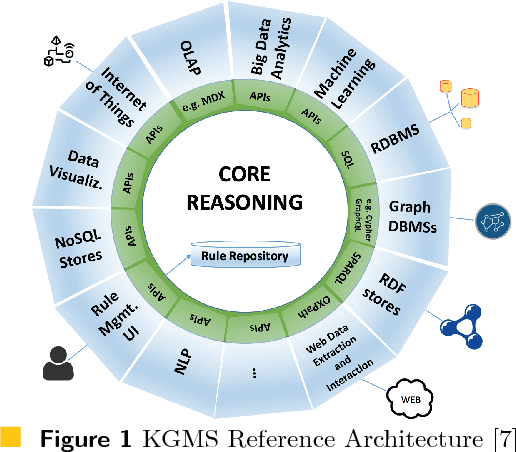
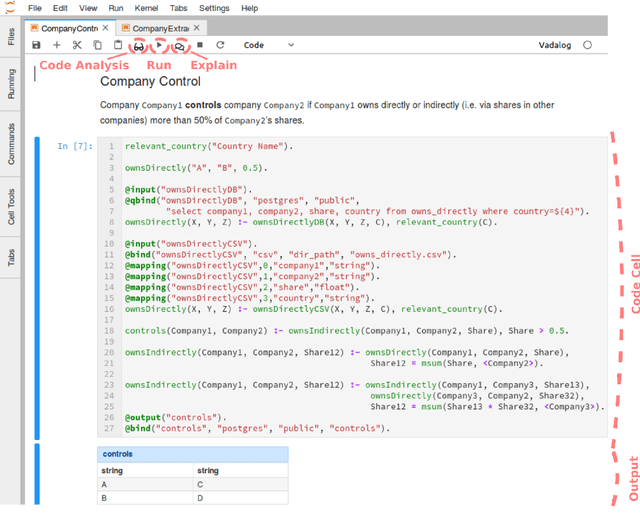
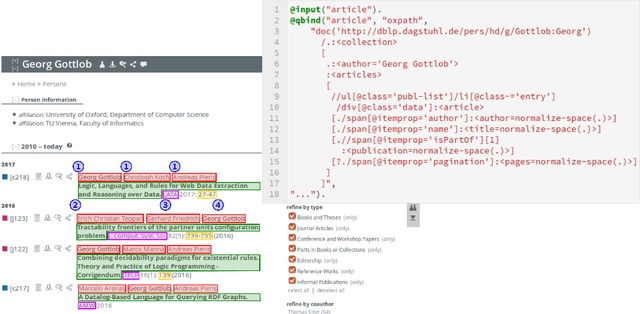
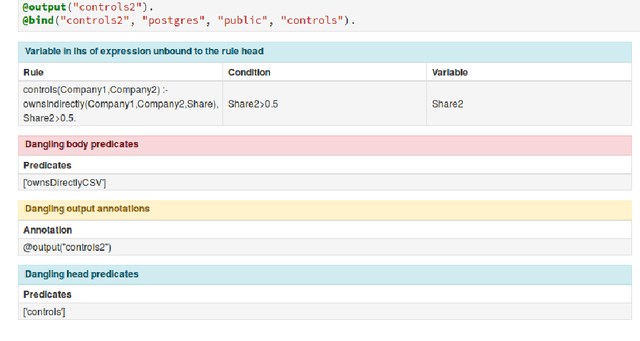
Following the recent successful examples of large technology companies, many modern enterprises seek to build knowledge graphs to provide a unified view of corporate knowledge and to draw deep insights using machine learning and logical reasoning. There is currently a perceived disconnect between the traditional approaches for data science, typically based on machine learning and statistical modelling, and systems for reasoning with domain knowledge. In this paper we present a state-of-the-art Knowledge Graph Management System, Vadalog, which delivers highly expressive and efficient logical reasoning and provides seamless integration with modern data science toolkits, such as the Jupyter platform. We demonstrate how to use Vadalog to perform traditional data wrangling tasks, as well as complex logical and probabilistic reasoning. We argue that this is a significant step forward towards combining machine learning and reasoning in data science.