 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching a Fashion Knowledge Graph from Product Textual Descriptions
Jun 02, 2022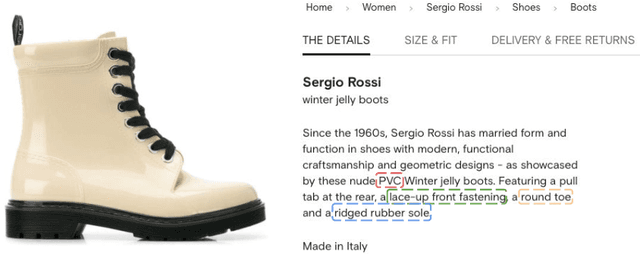
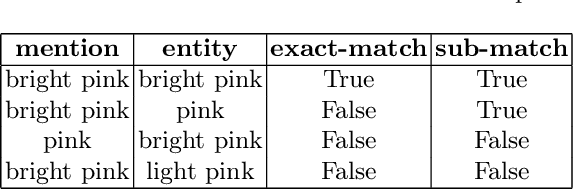

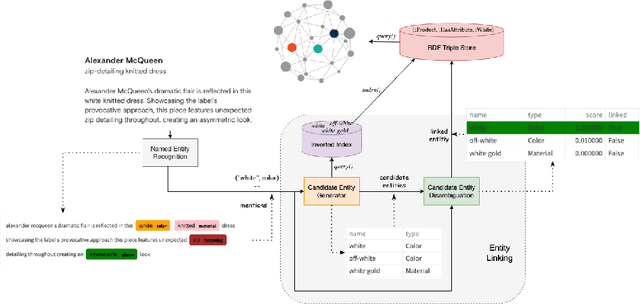
Knowledge Graphs offer a very useful and powerful structure for representing information, consequently, they have been adopted as the backbone for many applications in e-commerce scenarios. In this paper, we describe an application of existing techniques for enriching thelarge-scale Fashion Knowledge Graph (FKG) that we build at Farfetch. In particular, we apply techniques for named entity recognition (NER) and entity linking (EL) in order to extract and link rich metadata from product textual descriptions to entities in the FKG. Having a complete and enriched FKG as an e-commerce backbone can have a highly valuable impact on downstream applications such as search and recommendations. However, enriching a Knowledge Graph in the fashion domain has its own challenges. Data representation is different from a more generic KG, like Wikidata and Yago, as entities (e.g. product attributes) are too specific to the domain, and long textual descriptions are not readily available. Data itself is also scarce, as labelling datasets to train supervised models is a very laborious task. Even more, fashion products display a high variability and require an intricate ontology of attributes to link to. We use a transfer learning based approach to train an NER module on a small amount of manually labeled data, followed by an EL module that links the previously identified named entities to the appropriate entities within the FKG. Experiments using a pre-trained model show that it is possible to achieve 89.75% accuracy in NER even with a small manually labeled dataset. Moreover, the EL module, despite relying on simple rule-based or ML models (due to lack of training data), is able to link relevant attributes to products, thus automatically enriching the FKG.
BlaBla: Linguistic Feature Extraction for Clinical Analysis in Multiple Languages
May 20, 2020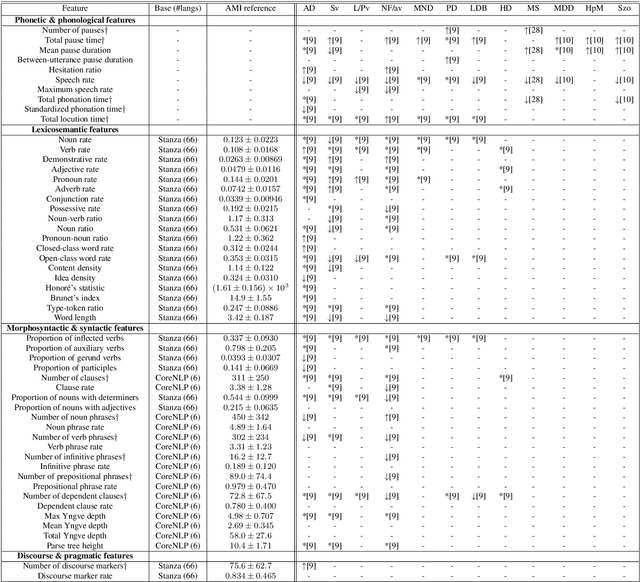


We introduce BlaBla, an open-source Python library for extracting linguistic features with proven clinical relevance to neurological and psychiatric diseases across many languages. BlaBla is a unifying framework for accelerating and simplifying clinical linguistic research. The library is built on state-of-the-art NLP frameworks and supports multithreaded/GPU-enabled feature extraction via both native Python calls and a command line interface. We describe BlaBla's architecture and clinical validation of its features across 12 diseases. We further demonstrate the application of BlaBla to a task visualizing and classifying language disorders in three languages on real clinical data from the AphasiaBank dataset. We make the codebase freely available to researchers with the hope of providing a consistent, well-validated foundation for the next generation of clinical linguistic research.
Surfboard: Audio Feature Extraction for Modern Machine Learning
May 18, 2020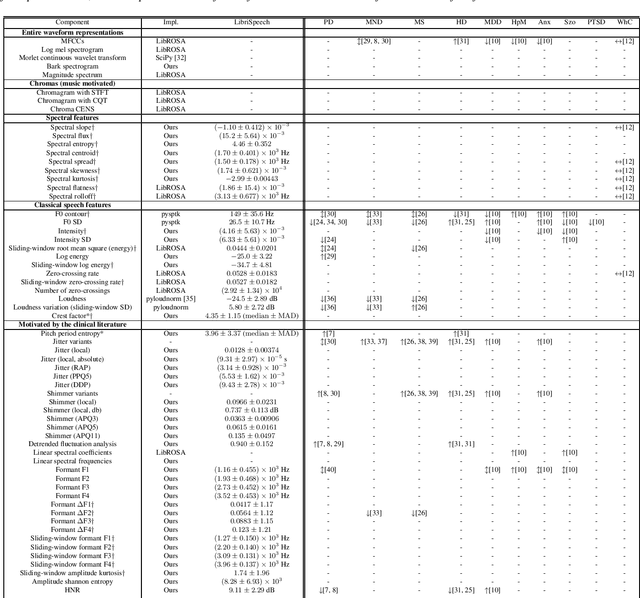
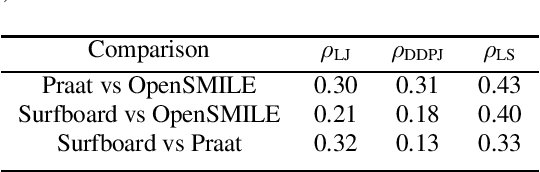
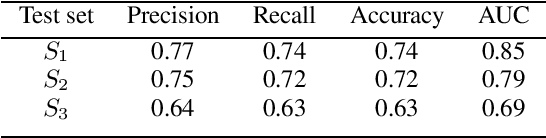
We introduce Surfboard, an open-source Python library for extracting audio features with application to the medical domain. Surfboard is written with the aim of addressing pain points of existing libraries and facilitating joint use with modern machine learning frameworks. The package can be accessed both programmatically in Python and via its command line interface, allowing it to be easily integrated within machine learning workflows. It builds on state-of-the-art audio analysis packages and offers multiprocessing support for processing large workloads. We review similar frameworks and describe Surfboard's architecture, including the clinical motivation for its features. Using the mPower dataset, we illustrate Surfboard's application to a Parkinson's disease classification task, highlighting common pitfalls in existing research. The source code is opened up to the research community to facilitate future audio research in the clinical domain.