 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching a Fashion Knowledge Graph from Product Textual Descriptions
Jun 02, 2022

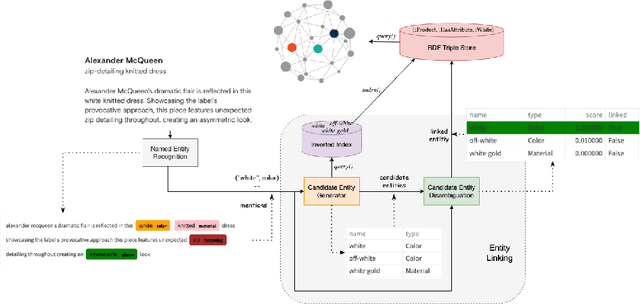
Knowledge Graphs offer a very useful and powerful structure for representing information, consequently, they have been adopted as the backbone for many applications in e-commerce scenarios. In this paper, we describe an application of existing techniques for enriching thelarge-scale Fashion Knowledge Graph (FKG) that we build at Farfetch. In particular, we apply techniques for named entity recognition (NER) and entity linking (EL) in order to extract and link rich metadata from product textual descriptions to entities in the FKG. Having a complete and enriched FKG as an e-commerce backbone can have a highly valuable impact on downstream applications such as search and recommendations. However, enriching a Knowledge Graph in the fashion domain has its own challenges. Data representation is different from a more generic KG, like Wikidata and Yago, as entities (e.g. product attributes) are too specific to the domain, and long textual descriptions are not readily available. Data itself is also scarce, as labelling datasets to train supervised models is a very laborious task. Even more, fashion products display a high variability and require an intricate ontology of attributes to link to. We use a transfer learning based approach to train an NER module on a small amount of manually labeled data, followed by an EL module that links the previously identified named entities to the appropriate entities within the FKG. Experiments using a pre-trained model show that it is possible to achieve 89.75% accuracy in NER even with a small manually labeled dataset. Moreover, the EL module, despite relying on simple rule-based or ML models (due to lack of training data), is able to link relevant attributes to products, thus automatically enriching the FKG.
Pose Guided Attention for Multi-label Fashion Image Classification
Nov 12, 2019
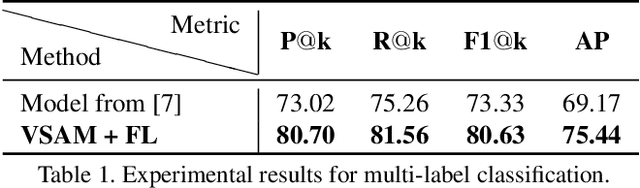

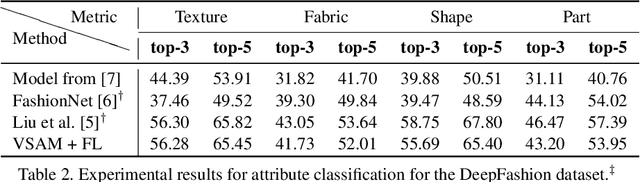
We propose a compact framework with guided attention for multi-label classification in the fashion domain. Our visual semantic attention model (VSAM) is supervised by automatic pose extraction creating a discriminative feature space. VSAM outperforms the state of the art for an in-house dataset and performs on par with previous works on the DeepFashion dataset, even without using any landmark annotations. Additionally, we show that our semantic attention module brings robustness to large quantities of wrong annotations and provides more interpretable results.
A Unified Model with Structured Output for Fashion Images Classification
Jun 25, 2018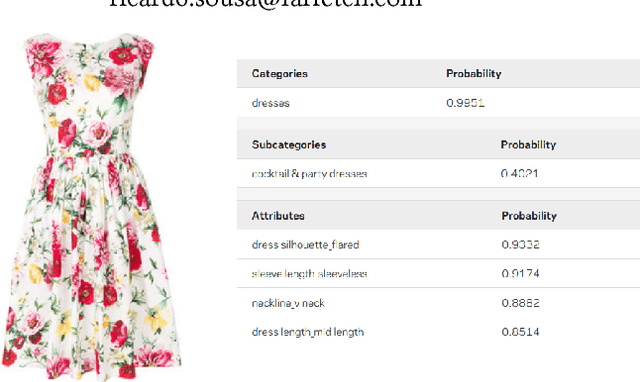
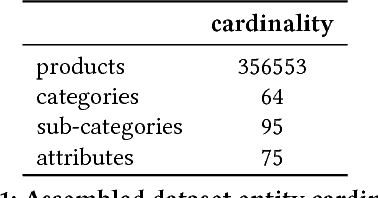
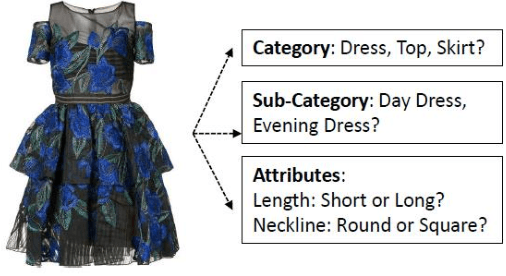
A picture is worth a thousand words. Albeit a clich\'e, for the fashion industry, an image of a clothing piece allows one to perceive its category (e.g., dress), sub-category (e.g., day dress) and properties (e.g., white colour with floral patterns). The seasonal nature of the fashion industry creates a highly dynamic and creative domain with evermore data, making it unpractical to manually describe a large set of images (of products). In this paper, we explore the concept of visual recognition for fashion images through an end-to-end architecture embedding the hierarchical nature of the annotations directly into the model. Towards that goal, and inspired by the work of [7], we have modified and adapted the original architecture proposal. Namely, we have removed the message passing layer symmetry to cope with Farfetch category tree, added extra layers for hierarchy level specificity, and moved the message passing layer into an enriched latent space. We compare the proposed unified architecture against state-of-the-art models and demonstrate the performance advantage of our model for structured multi-level categorization on a dataset of about 350k fashion product images.
A Context Aware and Video-Based Risk Descriptor for Cyclists
Apr 24, 2017


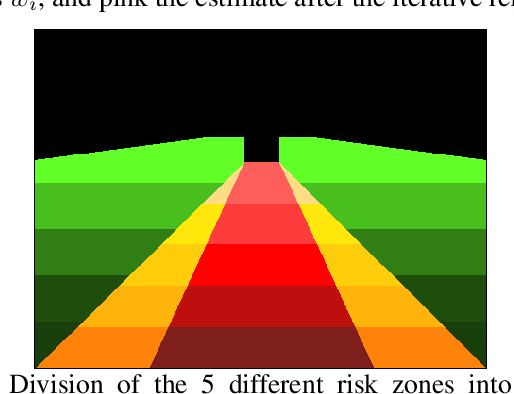
Aiming to reduce pollutant emissions, bicycles are regaining popularity specially in urban areas. However, the number of cyclists' fatalities is not showing the same decreasing trend as the other traffic groups. Hence, monitoring cyclists' data appears as a keystone to foster urban cyclists' safety by helping urban planners to design safer cyclist routes. In this work, we propose a fully image-based framework to assess the rout risk from the cyclist perspective. From smartphone sequences of images, this generic framework is able to automatically identify events considering different risk criteria based on the cyclist's motion and object detection. Moreover, since it is entirely based on images, our method provides context on the situation and is independent from the expertise level of the cyclist. Additionally, we build on an existing platform and introduce several improvements on its mobile app to acquire smartphone sensor data, including video. From the inertial sensor data, we automatically detect the route segments performed by bicycle, applying behavior analysis techniques. We test our methods on real data, attaining very promising results in terms of risk classification, according to two different criteria, and behavior analysis accuracy.