 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to rewrite the stars: Mapping your orchard over time through constellations of fruits
Feb 04, 2026Following crop growth through the vegetative cycle allows farmers to predict fruit setting and yield in early stages, but it is a laborious and non-scalable task if performed by a human who has to manually measure fruit sizes with a caliper or dendrometers. In recent years, computer vision has been used to automate several tasks in precision agriculture, such as detecting and counting fruits, and estimating their size. However, the fundamental problem of matching the exact same fruits from one video, collected on a given date, to the fruits visible in another video, collected on a later date, which is needed to track fruits' growth through time, remains to be solved. Few attempts were made, but they either assume that the camera always starts from the same known position and that there are sufficiently distinct features to match, or they used other sources of data like GPS. Here we propose a new paradigm to tackle this problem, based on constellations of 3D centroids, and introduce a descriptor for very sparse 3D point clouds that can be used to match fruits across videos. Matching constellations instead of individual fruits is key to deal with non-rigidity, occlusions and challenging imagery with few distinct visual features to track. The results show that the proposed method can be successfully used to match fruits across videos and through time, and also to build an orchard map and later use it to locate the camera pose in 6DoF, thus providing a method for autonomous navigation of robots in the orchard and for selective fruit picking, for example.
Pose Guided Attention for Multi-label Fashion Image Classification
Nov 12, 2019
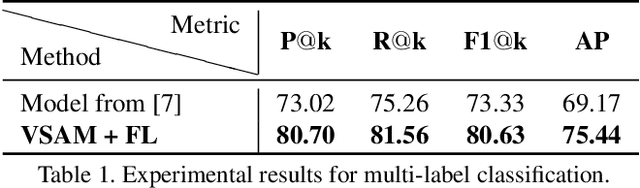

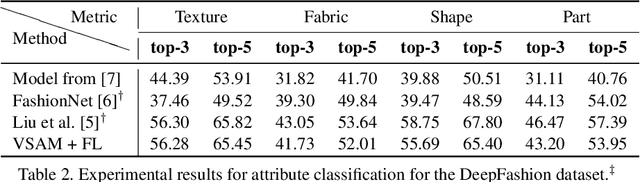
We propose a compact framework with guided attention for multi-label classification in the fashion domain. Our visual semantic attention model (VSAM) is supervised by automatic pose extraction creating a discriminative feature space. VSAM outperforms the state of the art for an in-house dataset and performs on par with previous works on the DeepFashion dataset, even without using any landmark annotations. Additionally, we show that our semantic attention module brings robustness to large quantities of wrong annotations and provides more interpretable results.
Multiple Source Domain Adaptation with Adversarial Training of Neural Networks
Oct 27, 2017
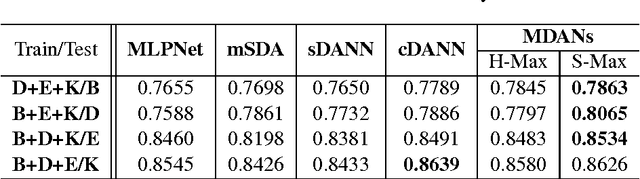
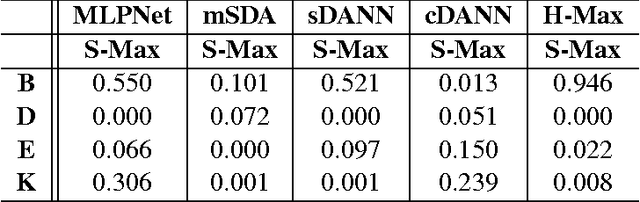
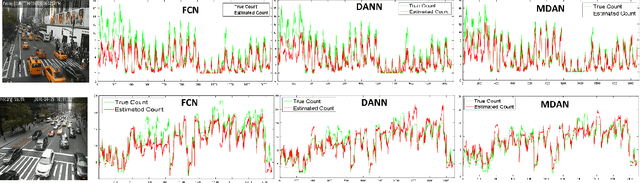
While domain adaptation has been actively researched in recent years, most theoretical results and algorithms focus on the single-source-single-target adaptation setting. Naive application of such algorithms on multiple source domain adaptation problem may lead to suboptimal solutions. As a step toward bridging the gap, we propose a new generalization bound for domain adaptation when there are multiple source domains with labeled instances and one target domain with unlabeled instances. Compared with existing bounds, the new bound does not require expert knowledge about the target distribution, nor the optimal combination rule for multisource domains. Interestingly, our theory also leads to an efficient learning strategy using adversarial neural networks: we show how to interpret it as learning feature representations that are invariant to the multiple domain shifts while still being discriminative for the learning task. To this end, we propose two models, both of which we call multisource domain adversarial networks (MDANs): the first model optimizes directly our bound, while the second model is a smoothed approximation of the first one, leading to a more data-efficient and task-adaptive model. The optimization tasks of both models are minimax saddle point problems that can be optimized by adversarial training. To demonstrate the effectiveness of MDANs, we conduct extensive experiments showing superior adaptation performance on three real-world datasets: sentiment analysis, digit classification, and vehicle counting.
Subspace Segmentation by Successive Approximations: A Method for Low-Rank and High-Rank Data with Missing Entries
Sep 05, 2017

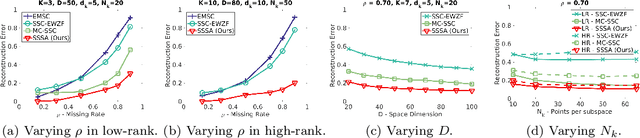
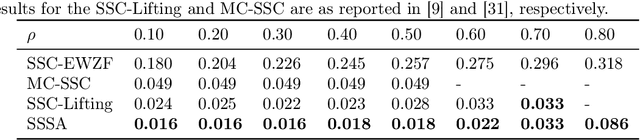
We propose a method to reconstruct and cluster incomplete high-dimensional data lying in a union of low-dimensional subspaces. Exploring the sparse representation model, we jointly estimate the missing data while imposing the intrinsic subspace structure. Since we have a non-convex problem, we propose an iterative method to reconstruct the data and provide a sparse similarity affinity matrix. This method is robust to initialization and achieves greater reconstruction accuracy than current methods, which dramatically improves clustering performance. Extensive experiments with synthetic and real data show that our approach leads to significant improvements in the reconstruction and segmentation, outperforming current state of the art for both low and high-rank data.
FCN-rLSTM: Deep Spatio-Temporal Neural Networks for Vehicle Counting in City Cameras
Aug 01, 2017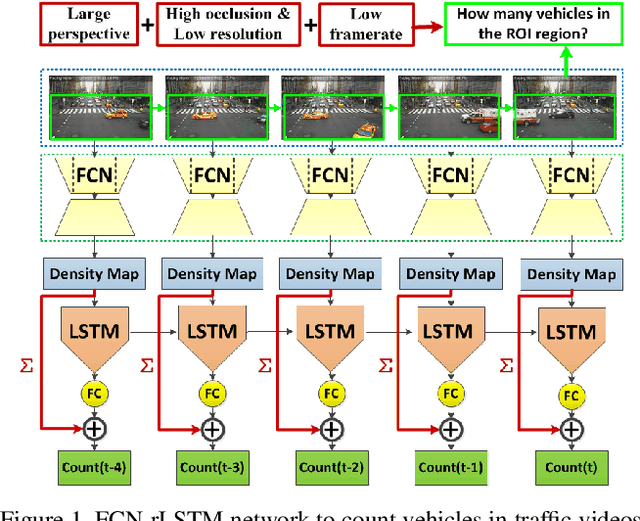


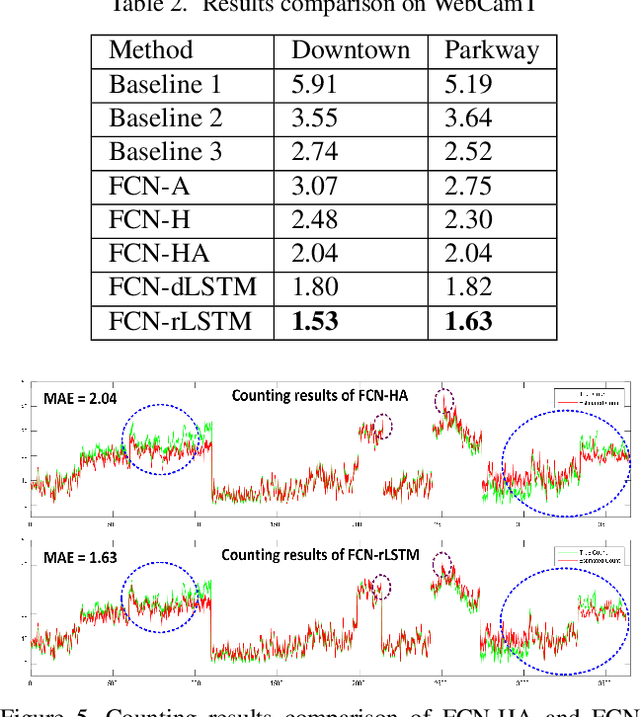
In this paper, we develop deep spatio-temporal neural networks to sequentially count vehicles from low quality videos captured by city cameras (citycams). Citycam videos have low resolution, low frame rate, high occlusion and large perspective, making most existing methods lose their efficacy. To overcome limitations of existing methods and incorporate the temporal information of traffic video, we design a novel FCN-rLSTM network to jointly estimate vehicle density and vehicle count by connecting fully convolutional neural networks (FCN) with long short term memory networks (LSTM) in a residual learning fashion. Such design leverages the strengths of FCN for pixel-level prediction and the strengths of LSTM for learning complex temporal dynamics. The residual learning connection reformulates the vehicle count regression as learning residual functions with reference to the sum of densities in each frame, which significantly accelerates the training of networks. To preserve feature map resolution, we propose a Hyper-Atrous combination to integrate atrous convolution in FCN and combine feature maps of different convolution layers. FCN-rLSTM enables refined feature representation and a novel end-to-end trainable mapping from pixels to vehicle count. We extensively evaluated the proposed method on different counting tasks with three datasets, with experimental results demonstrating their effectiveness and robustness. In particular, FCN-rLSTM reduces the mean absolute error (MAE) from 5.31 to 4.21 on TRANCOS, and reduces the MAE from 2.74 to 1.53 on WebCamT. Training process is accelerated by 5 times on average.
Discriminative Optimization: Theory and Applications to Computer Vision Problems
Jul 13, 2017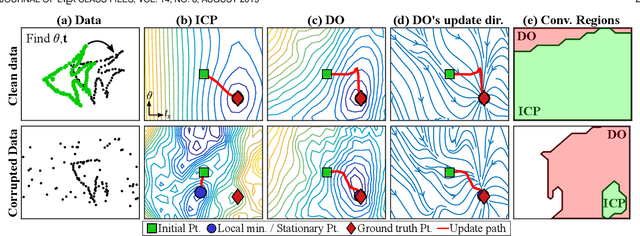
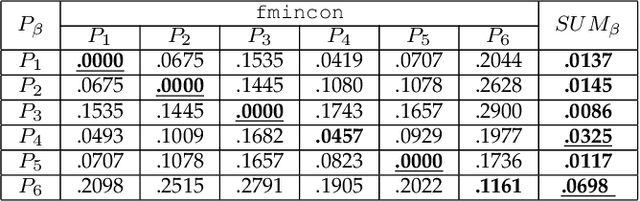
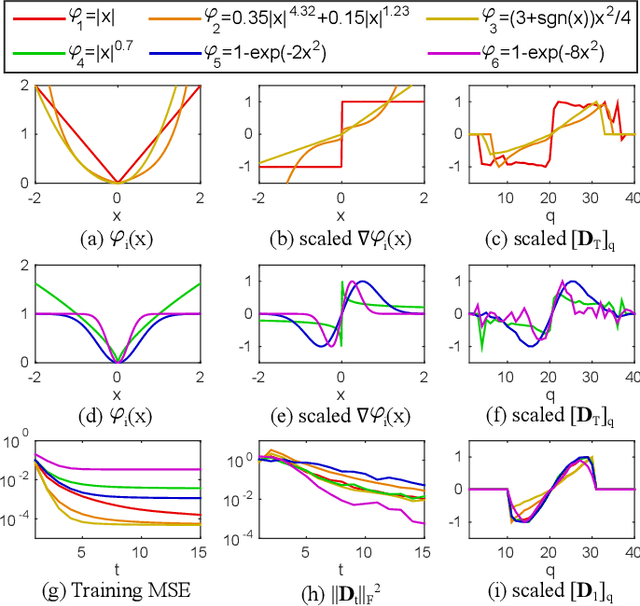
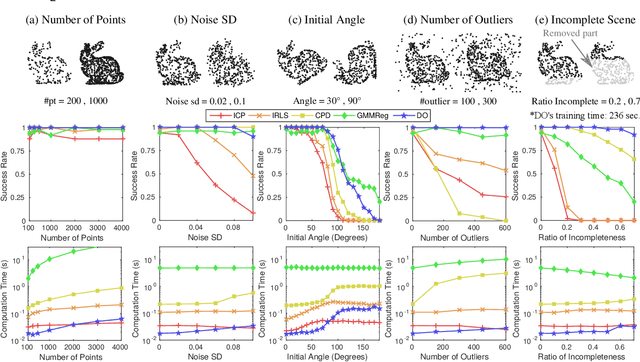
Many computer vision problems are formulated as the optimization of a cost function. This approach faces two main challenges: (i) designing a cost function with a local optimum at an acceptable solution, and (ii) developing an efficient numerical method to search for one (or multiple) of these local optima. While designing such functions is feasible in the noiseless case, the stability and location of local optima are mostly unknown under noise, occlusion, or missing data. In practice, this can result in undesirable local optima or not having a local optimum in the expected place. On the other hand, numerical optimization algorithms in high-dimensional spaces are typically local and often rely on expensive first or second order information to guide the search. To overcome these limitations, this paper proposes Discriminative Optimization (DO), a method that learns search directions from data without the need of a cost function. Specifically, DO explicitly learns a sequence of updates in the search space that leads to stationary points that correspond to desired solutions. We provide a formal analysis of DO and illustrate its benefits in the problem of 3D point cloud registration, camera pose estimation, and image denoising. We show that DO performed comparably or outperformed state-of-the-art algorithms in terms of accuracy, robustness to perturbations, and computational efficiency.
Understanding Traffic Density from Large-Scale Web Camera Data
Jun 30, 2017
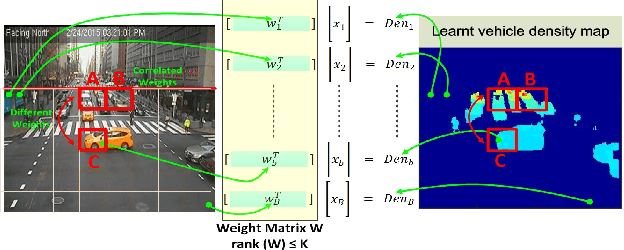
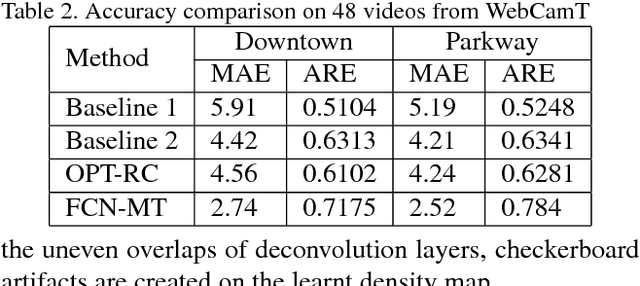
Understanding traffic density from large-scale web camera (webcam) videos is a challenging problem because such videos have low spatial and temporal resolution, high occlusion and large perspective. To deeply understand traffic density, we explore both deep learning based and optimization based methods. To avoid individual vehicle detection and tracking, both methods map the image into vehicle density map, one based on rank constrained regression and the other one based on fully convolution networks (FCN). The regression based method learns different weights for different blocks in the image to increase freedom degrees of weights and embed perspective information. The FCN based method jointly estimates vehicle density map and vehicle count with a residual learning framework to perform end-to-end dense prediction, allowing arbitrary image resolution, and adapting to different vehicle scales and perspectives. We analyze and compare both methods, and get insights from optimization based method to improve deep model. Since existing datasets do not cover all the challenges in our work, we collected and labelled a large-scale traffic video dataset, containing 60 million frames from 212 webcams. Both methods are extensively evaluated and compared on different counting tasks and datasets. FCN based method significantly reduces the mean absolute error from 10.99 to 5.31 on the public dataset TRANCOS compared with the state-of-the-art baseline.
Understanding People Flow in Transportation Hubs
Apr 28, 2017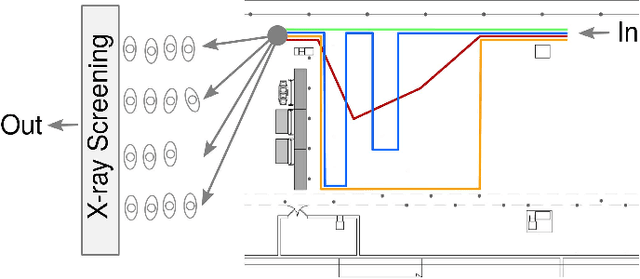
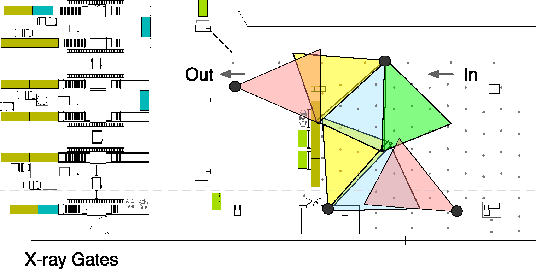
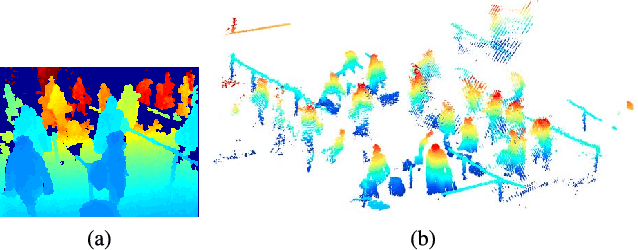
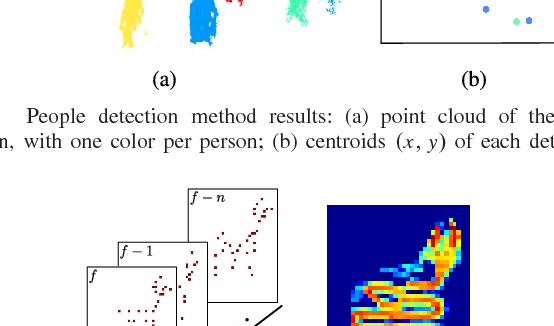
In this paper, we aim to monitor the flow of people in large public infrastructures. We propose an unsupervised methodology to cluster people flow patterns into the most typical and meaningful configurations. By processing 3D images from a network of depth cameras, we built a descriptor for the flow pattern. We define a data-irregularity measure that assesses how well each descriptor fits a data model. This allows us to rank the flow patterns from highly distinctive (outliers) to very common ones and, discarding outliers, obtain more reliable key configurations (classes). We applied this methodology in an operational scenario during 18 days in the X-ray screening area of an international airport. Results show that our methodology is able to summarize the representative patterns, a relevant information for airport management. Beyond regular flows our method identifies a set of rare events corresponding to uncommon activities (cleaning,special security and circulating staff). We demonstrate that for such a long observation period our methodology encapsulates the relevant "states" of the infrastructure in a very compact way.