 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Block RNN-based Trajectory Prediction from Incomplete Trajectory
Mar 16, 2022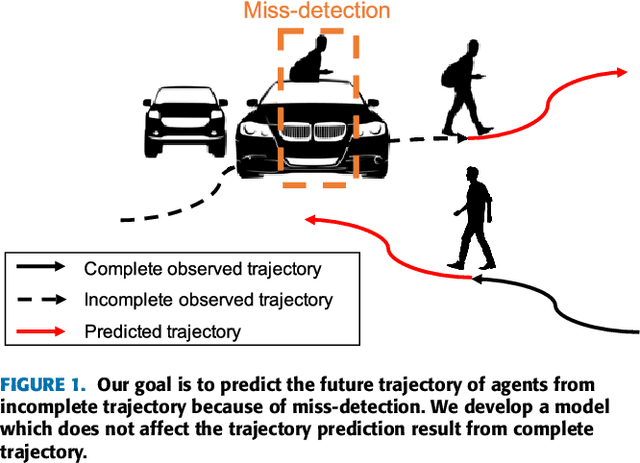
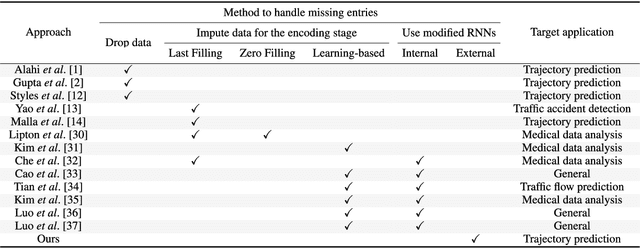

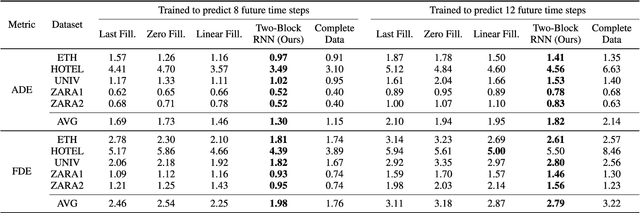
Trajectory prediction has gained great attention and significant progress has been made in recent years. However, most works rely on a key assumption that each video is successfully preprocessed by detection and tracking algorithms and the complete observed trajectory is always available. However, in complex real-world environments, we often encounter miss-detection of target agents (e.g., pedestrian, vehicles) caused by the bad image conditions, such as the occlusion by other agents. In this paper, we address the problem of trajectory prediction from incomplete observed trajectory due to miss-detection, where the observed trajectory includes several missing data points. We introduce a two-block RNN model that approximates the inference steps of the Bayesian filtering framework and seeks the optimal estimation of the hidden state when miss-detection occurs. The model uses two RNNs depending on the detection result. One RNN approximates the inference step of the Bayesian filter with the new measurement when the detection succeeds, while the other does the approximation when the detection fails. Our experiments show that the proposed model improves the prediction accuracy compared to the three baseline imputation methods on publicly available datasets: ETH and UCY ($9\%$ and $7\%$ improvement on the ADE and FDE metrics). We also show that our proposed method can achieve better prediction compared to the baselines when there is no miss-detection.
On Focal Loss for Class-Posterior Probability Estimation: A Theoretical Perspective
Dec 14, 2020
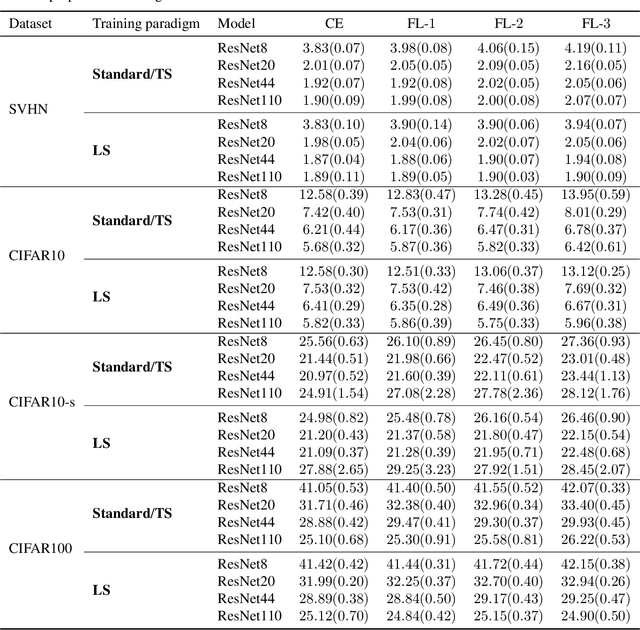
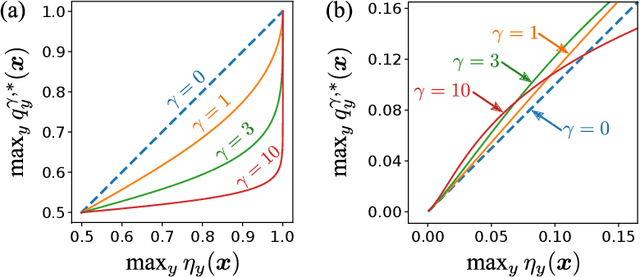
The focal loss has demonstrated its effectiveness in many real-world applications such as object detection and image classification, but its theoretical understanding has been limited so far. In this paper, we first prove that the focal loss is classification-calibrated, i.e., its minimizer surely yields the Bayes-optimal classifier and thus the use of the focal loss in classification can be theoretically justified. However, we also prove a negative fact that the focal loss is not strictly proper, i.e., the confidence score of the classifier obtained by focal loss minimization does not match the true class-posterior probability and thus it is not reliable as a class-posterior probability estimator. To mitigate this problem, we next prove that a particular closed-form transformation of the confidence score allows us to recover the true class-posterior probability. Through experiments on benchmark datasets, we demonstrate that our proposed transformation significantly improves the accuracy of class-posterior probability estimation.
Data-Efficient Framework for Real-world Multiple Sound Source 2D Localization
Dec 10, 2020
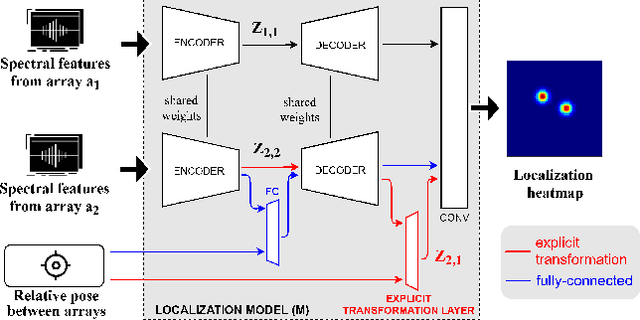
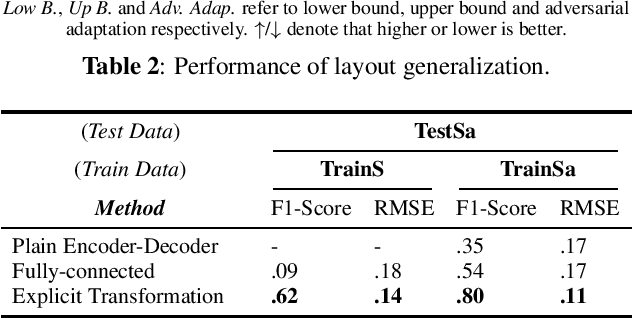
Deep neural networks have recently led to promising results for the task of multiple sound source localization. Yet, they require a lot of training data to cover a variety of acoustic conditions and microphone array layouts. One can leverage acoustic simulators to inexpensively generate labeled training data. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. Moreover, learning for different microphone array layouts makes the task more complicated due to the infinite number of possible layouts. We propose to use adversarial learning methods to close the gap between synthetic and real domains. Our novel ensemble-discrimination method significantly improves the localization performance without requiring any label from the real data. Furthermore, we propose a novel explicit transformation layer to be embedded in the localization architecture. It enables the model to be trained with data from specific microphone array layouts while generalizing well to unseen layouts during inference.
Ensemble of Discriminators for Domain Adaptation in Multiple Sound Source 2D Localization
Dec 10, 2020
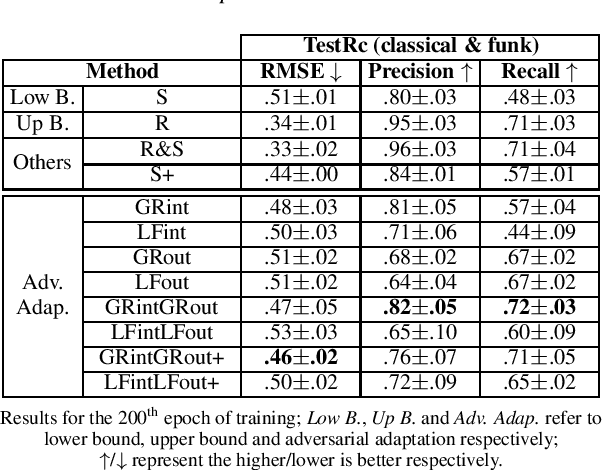
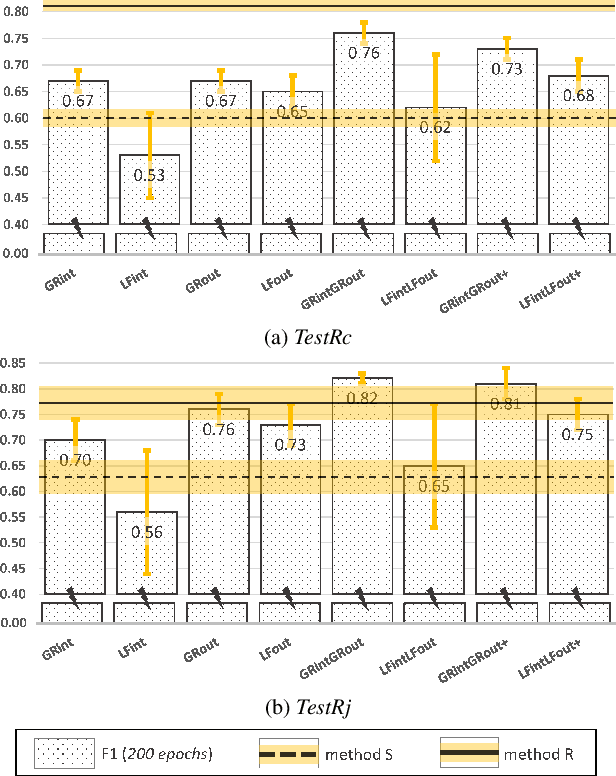
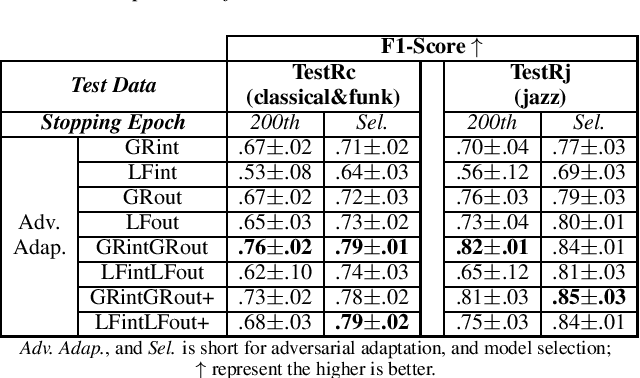
This paper introduces an ensemble of discriminators that improves the accuracy of a domain adaptation technique for the localization of multiple sound sources. Recently, deep neural networks have led to promising results for this task, yet they require a large amount of labeled data for training. Recording and labeling such datasets is very costly, especially because data needs to be diverse enough to cover different acoustic conditions. In this paper, we leverage acoustic simulators to inexpensively generate labeled training samples. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. For this, we explore two domain adaptation methods using adversarial learning for sound source localization which use labeled synthetic data and unlabeled real data. We propose a novel ensemble approach that combines discriminators applied at different feature levels of the localization model. Experiments show that our ensemble discrimination method significantly improves the localization performance without requiring any label from the real data.
Learning Multiple Sound Source 2D Localization
Dec 10, 2020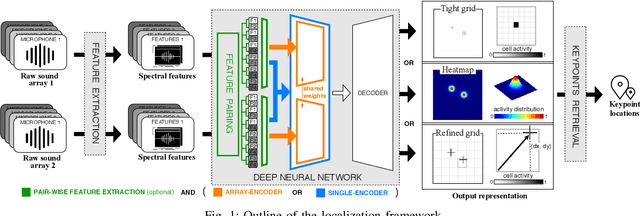
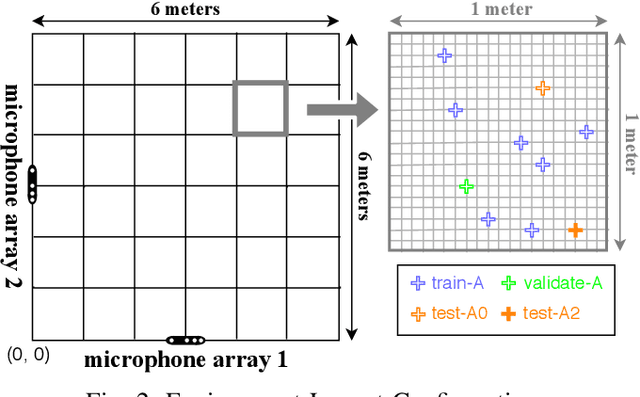
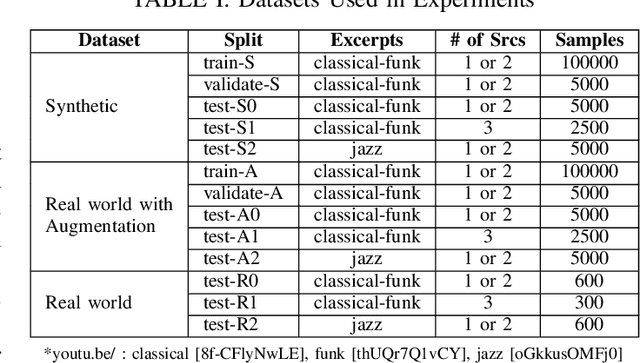
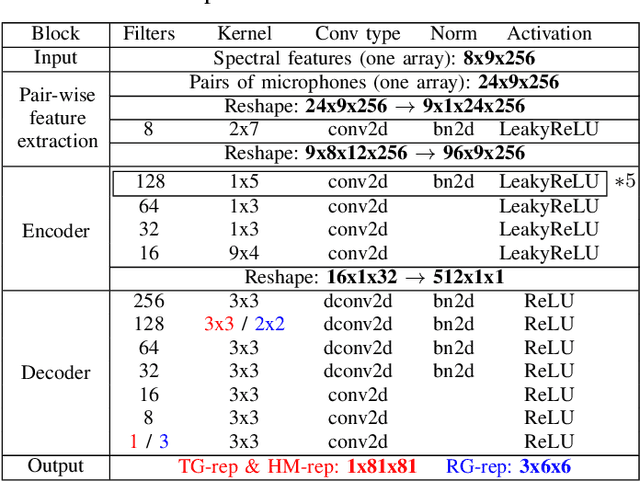
In this paper, we propose novel deep learning based algorithms for multiple sound source localization. Specifically, we aim to find the 2D Cartesian coordinates of multiple sound sources in an enclosed environment by using multiple microphone arrays. To this end, we use an encoding-decoding architecture and propose two improvements on it to accomplish the task. In addition, we also propose two novel localization representations which increase the accuracy. Lastly, new metrics are developed relying on resolution-based multiple source association which enables us to evaluate and compare different localization approaches. We tested our method on both synthetic and real world data. The results show that our method improves upon the previous baseline approach for this problem.
Unifying Heterogeneous Classifiers with Distillation
Apr 12, 2019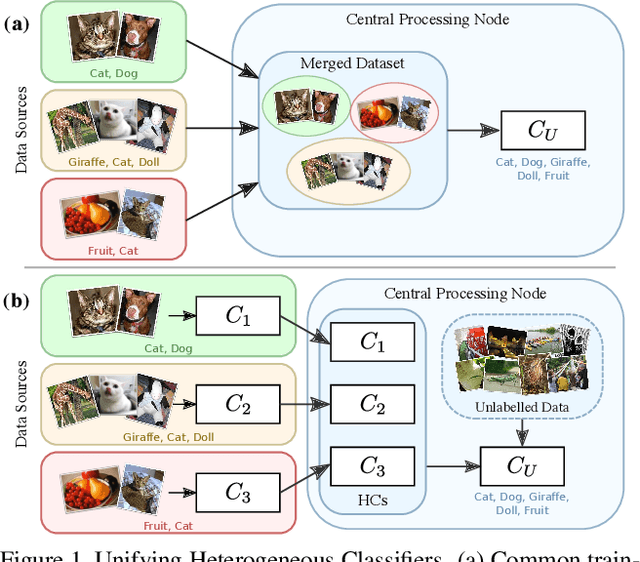

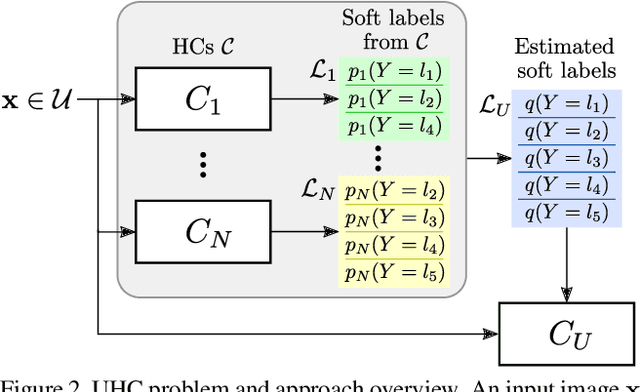
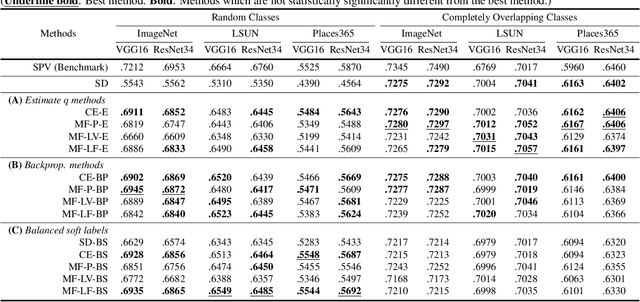
In this paper, we study the problem of unifying knowledge from a set of classifiers with different architectures and target classes into a single classifier, given only a generic set of unlabelled data. We call this problem Unifying Heterogeneous Classifiers (UHC). This problem is motivated by scenarios where data is collected from multiple sources, but the sources cannot share their data, e.g., due to privacy concerns, and only privately trained models can be shared. In addition, each source may not be able to gather data to train all classes due to data availability at each source, and may not be able to train the same classification model due to different computational resources. To tackle this problem, we propose a generalisation of knowledge distillation to merge HCs. We derive a probabilistic relation between the outputs of HCs and the probability over all classes. Based on this relation, we propose two classes of methods based on cross-entropy minimisation and matrix factorisation, which allow us to estimate soft labels over all classes from unlabelled samples and use them in lieu of ground truth labels to train a unified classifier. Our extensive experiments on ImageNet, LSUN, and Places365 datasets show that our approaches significantly outperform a naive extension of distillation and can achieve almost the same accuracy as classifiers that are trained in a centralised, supervised manner.
Discriminative Optimization: Theory and Applications to Computer Vision Problems
Jul 13, 2017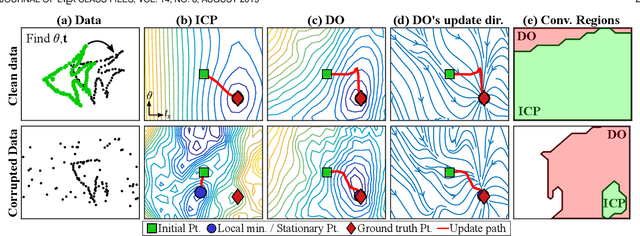
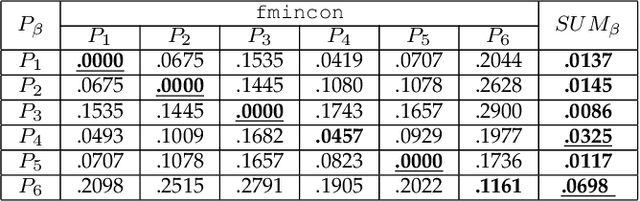
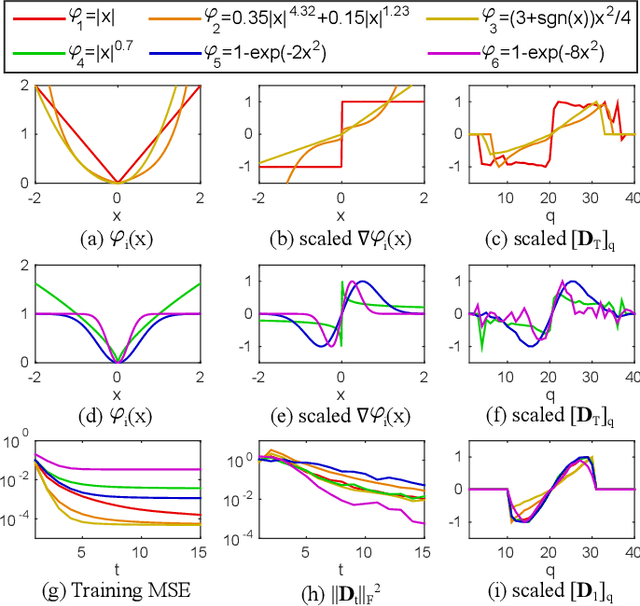
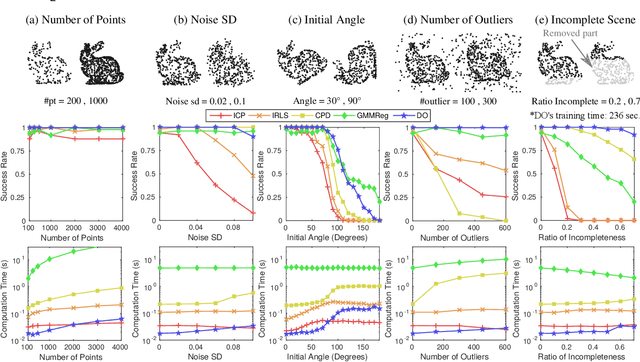
Many computer vision problems are formulated as the optimization of a cost function. This approach faces two main challenges: (i) designing a cost function with a local optimum at an acceptable solution, and (ii) developing an efficient numerical method to search for one (or multiple) of these local optima. While designing such functions is feasible in the noiseless case, the stability and location of local optima are mostly unknown under noise, occlusion, or missing data. In practice, this can result in undesirable local optima or not having a local optimum in the expected place. On the other hand, numerical optimization algorithms in high-dimensional spaces are typically local and often rely on expensive first or second order information to guide the search. To overcome these limitations, this paper proposes Discriminative Optimization (DO), a method that learns search directions from data without the need of a cost function. Specifically, DO explicitly learns a sequence of updates in the search space that leads to stationary points that correspond to desired solutions. We provide a formal analysis of DO and illustrate its benefits in the problem of 3D point cloud registration, camera pose estimation, and image denoising. We show that DO performed comparably or outperformed state-of-the-art algorithms in terms of accuracy, robustness to perturbations, and computational efficiency.