 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Framework for Real-world Multiple Sound Source 2D Localization
Dec 10, 2020
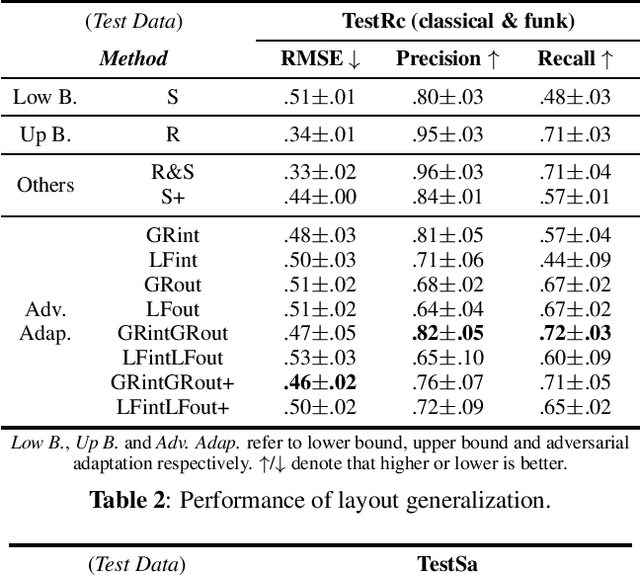
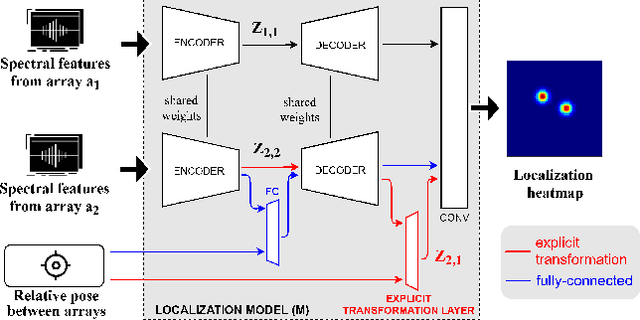
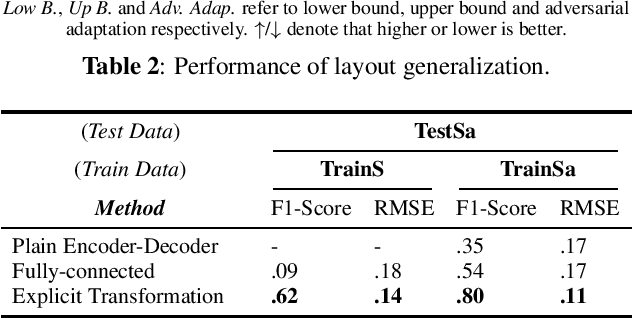
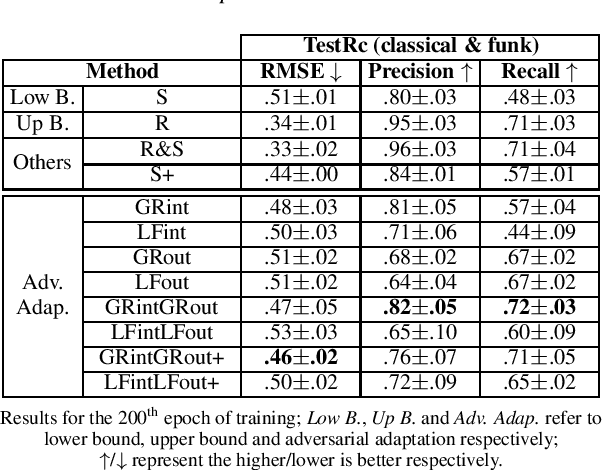
Deep neural networks have recently led to promising results for the task of multiple sound source localization. Yet, they require a lot of training data to cover a variety of acoustic conditions and microphone array layouts. One can leverage acoustic simulators to inexpensively generate labeled training data. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. Moreover, learning for different microphone array layouts makes the task more complicated due to the infinite number of possible layouts. We propose to use adversarial learning methods to close the gap between synthetic and real domains. Our novel ensemble-discrimination method significantly improves the localization performance without requiring any label from the real data. Furthermore, we propose a novel explicit transformation layer to be embedded in the localization architecture. It enables the model to be trained with data from specific microphone array layouts while generalizing well to unseen layouts during inference.
Ensemble of Discriminators for Domain Adaptation in Multiple Sound Source 2D Localization
Dec 10, 2020
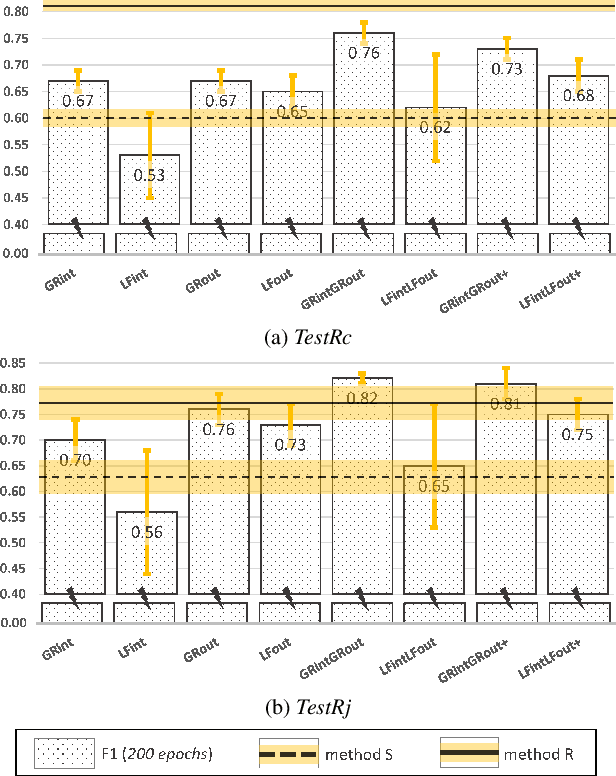
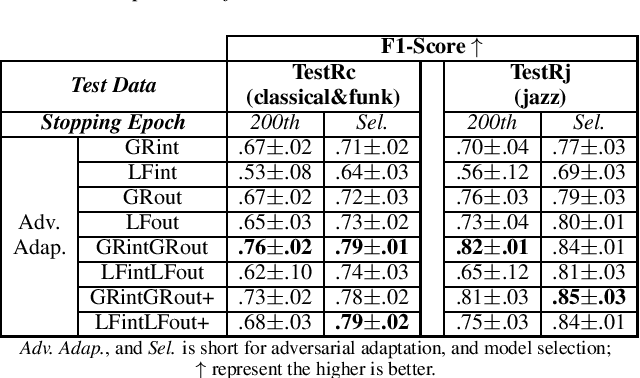
This paper introduces an ensemble of discriminators that improves the accuracy of a domain adaptation technique for the localization of multiple sound sources. Recently, deep neural networks have led to promising results for this task, yet they require a large amount of labeled data for training. Recording and labeling such datasets is very costly, especially because data needs to be diverse enough to cover different acoustic conditions. In this paper, we leverage acoustic simulators to inexpensively generate labeled training samples. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. For this, we explore two domain adaptation methods using adversarial learning for sound source localization which use labeled synthetic data and unlabeled real data. We propose a novel ensemble approach that combines discriminators applied at different feature levels of the localization model. Experiments show that our ensemble discrimination method significantly improves the localization performance without requiring any label from the real data.
Learning Multiple Sound Source 2D Localization
Dec 10, 2020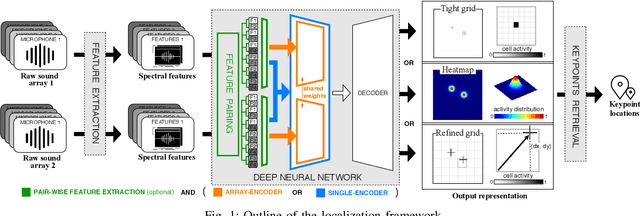
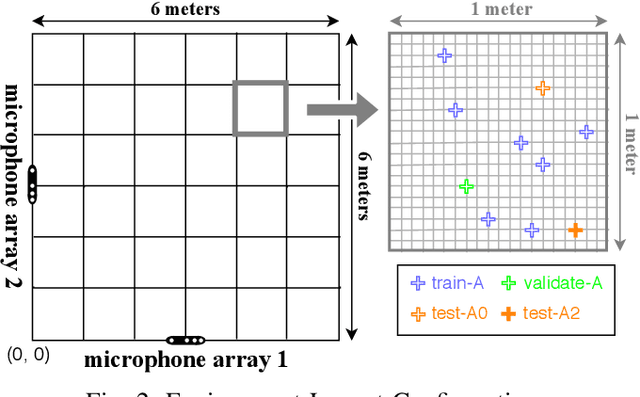
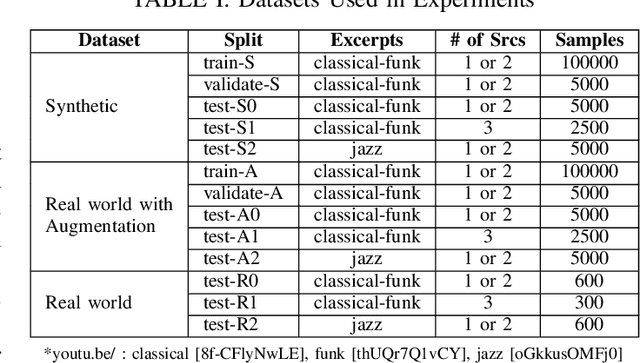
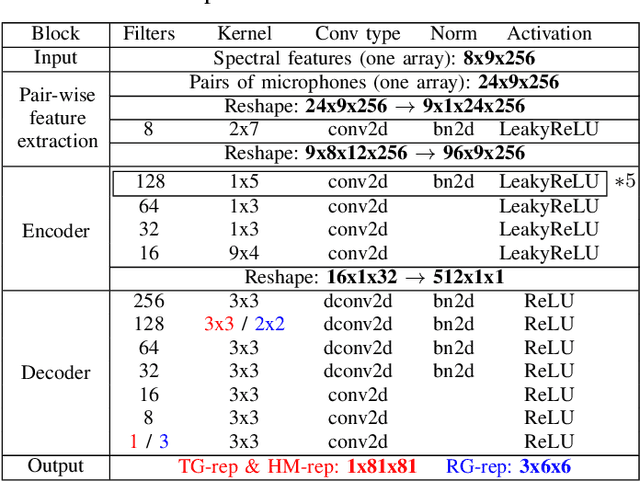
In this paper, we propose novel deep learning based algorithms for multiple sound source localization. Specifically, we aim to find the 2D Cartesian coordinates of multiple sound sources in an enclosed environment by using multiple microphone arrays. To this end, we use an encoding-decoding architecture and propose two improvements on it to accomplish the task. In addition, we also propose two novel localization representations which increase the accuracy. Lastly, new metrics are developed relying on resolution-based multiple source association which enables us to evaluate and compare different localization approaches. We tested our method on both synthetic and real world data. The results show that our method improves upon the previous baseline approach for this problem.
Unsupervised Temporal Feature Aggregation for Event Detection in Unstructured Sports Videos
Feb 19, 2020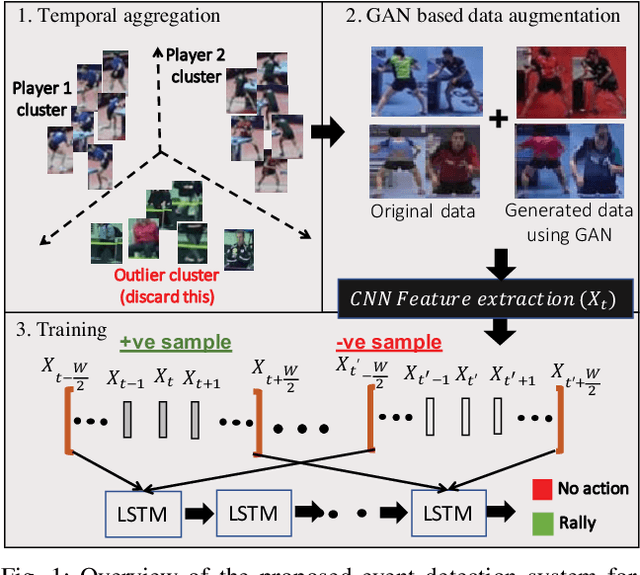



Image-based sports analytics enable automatic retrieval of key events in a game to speed up the analytics process for human experts. However, most existing methods focus on structured television broadcast video datasets with a straight and fixed camera having minimum variability in the capturing pose. In this paper, we study the case of event detection in sports videos for unstructured environments with arbitrary camera angles. The transition from structured to unstructured video analysis produces multiple challenges that we address in our paper. Specifically, we identify and solve two major problems: unsupervised identification of players in an unstructured setting and generalization of the trained models to pose variations due to arbitrary shooting angles. For the first problem, we propose a temporal feature aggregation algorithm using person re-identification features to obtain high player retrieval precision by boosting a weak heuristic scoring method. Additionally, we propose a data augmentation technique, based on multi-modal image translation model, to reduce bias in the appearance of training samples. Experimental evaluations show that our proposed method improves precision for player retrieval from 0.78 to 0.86 for obliquely angled videos. Additionally, we obtain an improvement in F1 score for rally detection in table tennis videos from 0.79 in case of global frame-level features to 0.89 using our proposed player-level features. Please see the supplementary video submission at https://ibm.biz/BdzeZA.
Unifying Heterogeneous Classifiers with Distillation
Apr 12, 2019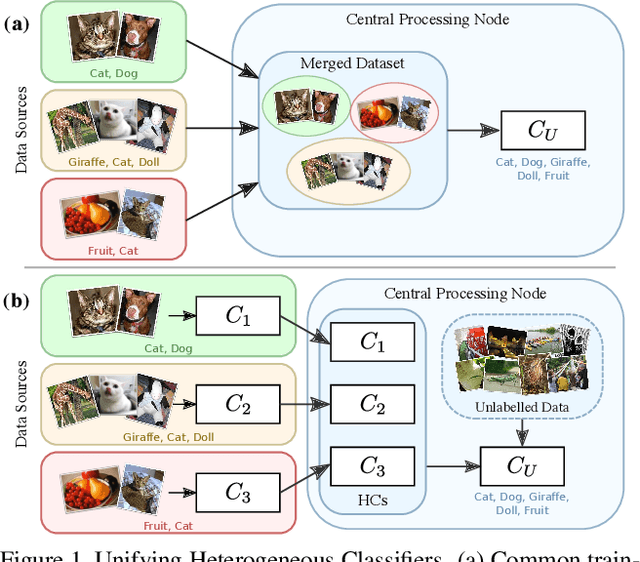

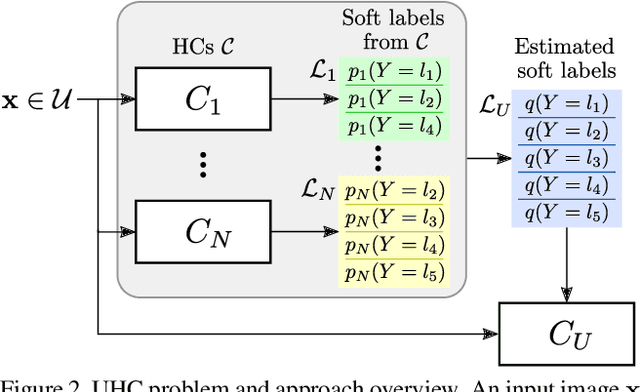
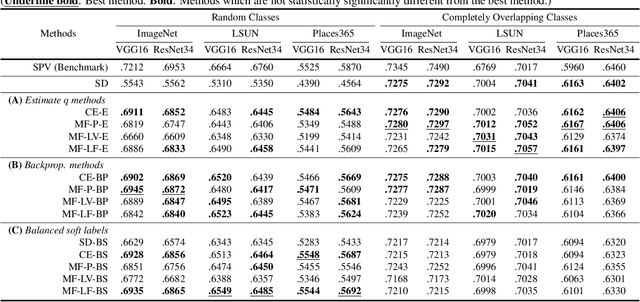
In this paper, we study the problem of unifying knowledge from a set of classifiers with different architectures and target classes into a single classifier, given only a generic set of unlabelled data. We call this problem Unifying Heterogeneous Classifiers (UHC). This problem is motivated by scenarios where data is collected from multiple sources, but the sources cannot share their data, e.g., due to privacy concerns, and only privately trained models can be shared. In addition, each source may not be able to gather data to train all classes due to data availability at each source, and may not be able to train the same classification model due to different computational resources. To tackle this problem, we propose a generalisation of knowledge distillation to merge HCs. We derive a probabilistic relation between the outputs of HCs and the probability over all classes. Based on this relation, we propose two classes of methods based on cross-entropy minimisation and matrix factorisation, which allow us to estimate soft labels over all classes from unlabelled samples and use them in lieu of ground truth labels to train a unified classifier. Our extensive experiments on ImageNet, LSUN, and Places365 datasets show that our approaches significantly outperform a naive extension of distillation and can achieve almost the same accuracy as classifiers that are trained in a centralised, supervised manner.
Deep Learning with Predictive Control for Human Motion Tracking
Aug 07, 2018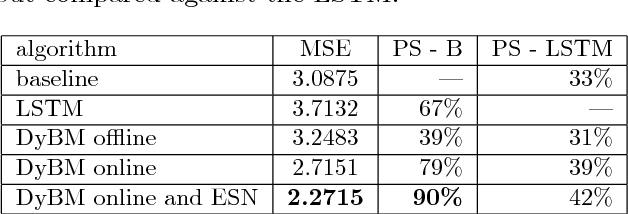
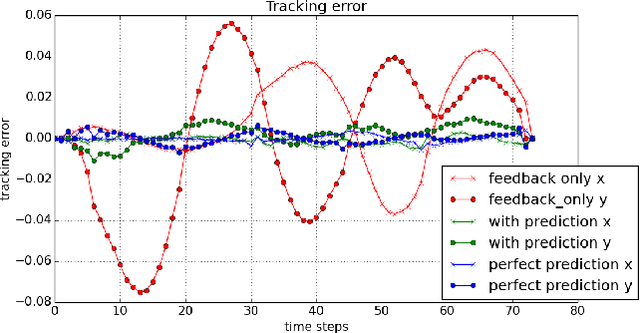
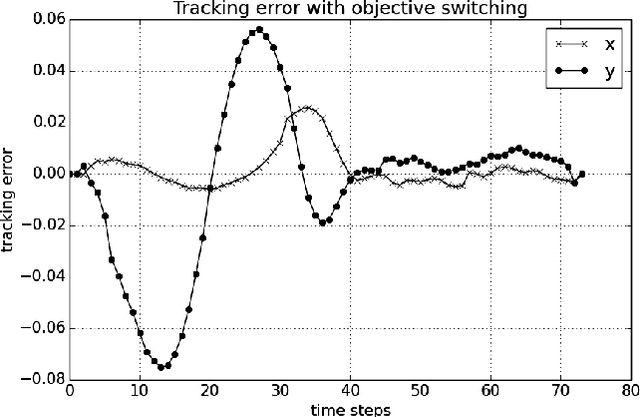
We propose to combine model predictive control with deep learning for the task of accurate human motion tracking with a robot. We design the MPC to allow switching between the learned and a conservative prediction. We also explored online learning with a DyBM model. We applied this method to human handwriting motion tracking with a UR-5 robot. The results show that the framework significantly improves tracking performance.
Experimental Force-Torque Dataset for Robot Learning of Multi-Shape Insertion
Jul 25, 2018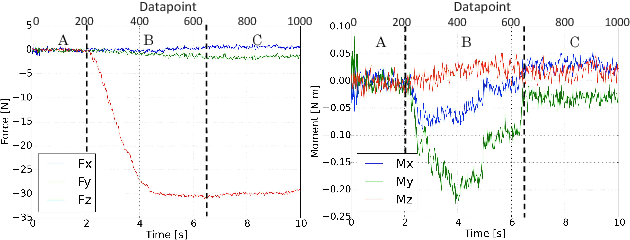

The accurate modeling of real-world systems and physical interactions is a common challenge towards the resolution of robotics tasks. Machine learning approaches have demonstrated significant results in the modeling of complex systems (e.g., articulated robot structures, cable stretch, fluid dynamics), or to learn robotics tasks (e.g., grasping, reaching) from raw sensor measurements without explicit programming, using reinforcement learning. However, a common bottleneck in machine learning techniques resides in the availability of suitable data. While many vision-based datasets have been released in the recent years, ones involving physical interactions, of particular interest for the robotic community, have been scarcer. In this paper, we present a public dataset on peg-in-hole insertion tasks containing force-torque and pose information for multiple variations of convex-shaped pegs. We demonstrate how this dataset can be used to train a robot to insert polyhedral pegs into holes using only 6-axis force/torque sensor measurements as inputs, as well as other tasks involving contact such as shape recognition.
Focusing on What is Relevant: Time-Series Learning and Understanding using Attention
Jun 22, 2018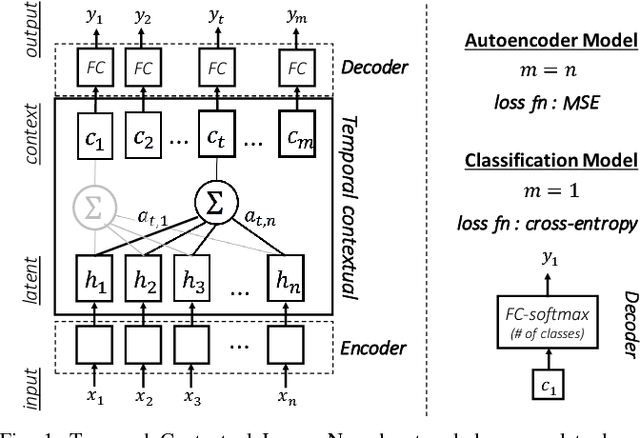
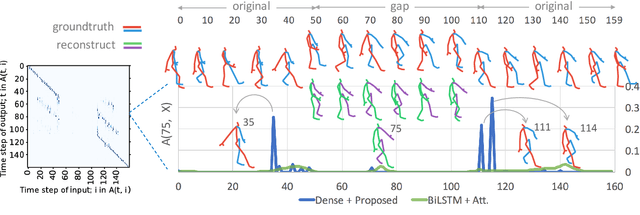

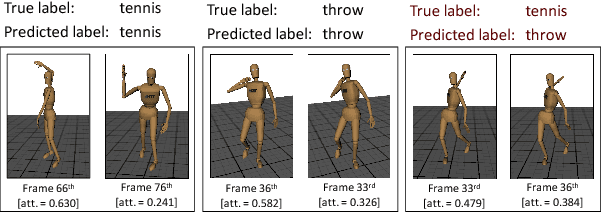
This paper is a contribution towards interpretability of the deep learning models in different applications of time-series. We propose a temporal attention layer that is capable of selecting the relevant information to perform various tasks, including data completion, key-frame detection and classification. The method uses the whole input sequence to calculate an attention value for each time step. This results in more focused attention values and more plausible visualisation than previous methods. We apply the proposed method to three different tasks. Experimental results show that the proposed network produces comparable results to a state of the art. In addition, the network provides better interpretability of the decision, that is, it generates more significant attention weight to related frames compared to similar techniques attempted in the past.
Limiting the Reconstruction Capability of Generative Neural Network using Negative Learning
Aug 16, 2017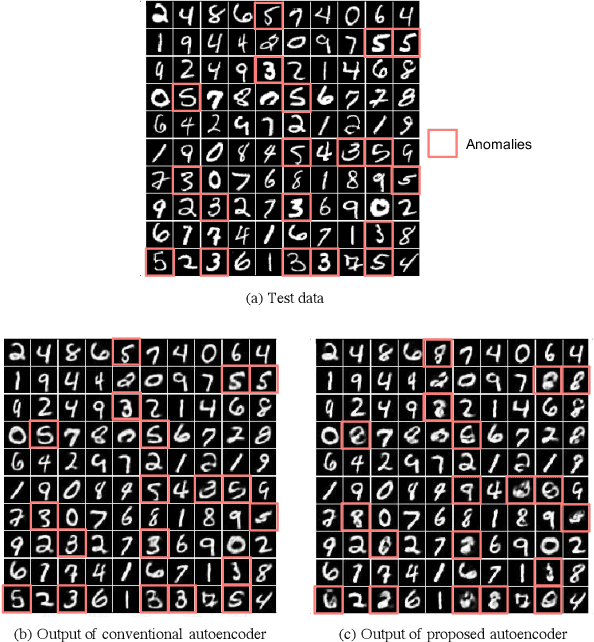
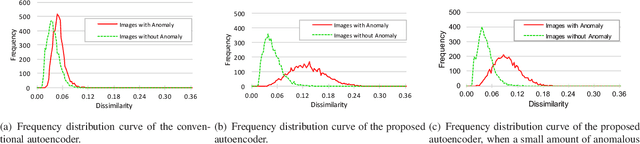


Generative models are widely used for unsupervised learning with various applications, including data compression and signal restoration. Training methods for such systems focus on the generality of the network given limited amount of training data. A less researched type of techniques concerns generation of only a single type of input. This is useful for applications such as constraint handling, noise reduction and anomaly detection. In this paper we present a technique to limit the generative capability of the network using negative learning. The proposed method searches the solution in the gradient direction for the desired input and in the opposite direction for the undesired input. One of the application can be anomaly detection where the undesired inputs are the anomalous data. In the results section we demonstrate the features of the algorithm using MNIST handwritten digit dataset and latter apply the technique to a real-world obstacle detection problem. The results clearly show that the proposed learning technique can significantly improve the performance for anomaly detection.