 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Vision based Sample-Tube Localization for Mars Sample Return
Mar 17, 2021

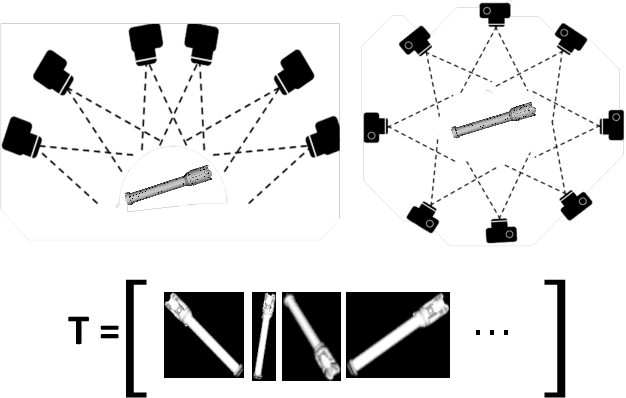
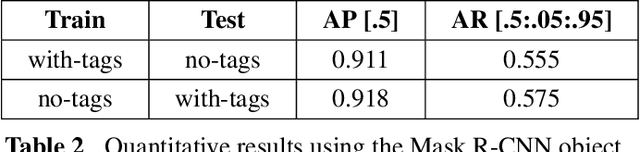
A potential Mars Sample Return (MSR) architecture is being jointly studied by NASA and ESA. As currently envisioned, the MSR campaign consists of a series of 3 missions: sample cache, fetch and return to Earth. In this paper, we focus on the fetch part of the MSR, and more specifically the problem of autonomously detecting and localizing sample tubes deposited on the Martian surface. Towards this end, we study two machine-vision based approaches: First, a geometry-driven approach based on template matching that uses hard-coded filters and a 3D shape model of the tube; and second, a data-driven approach based on convolutional neural networks (CNNs) and learned features. Furthermore, we present a large benchmark dataset of sample-tube images, collected in representative outdoor environments and annotated with ground truth segmentation masks and locations. The dataset was acquired systematically across different terrain, illumination conditions and dust-coverage; and benchmarking was performed to study the feasibility of each approach, their relative strengths and weaknesses, and robustness in the presence of adverse environmental conditions.
Rover Relocalization for Mars Sample Return by Virtual Template Synthesis and Matching
Mar 05, 2021
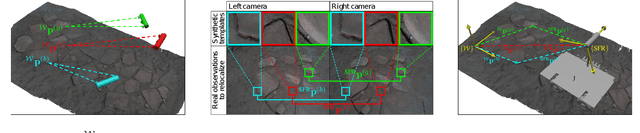

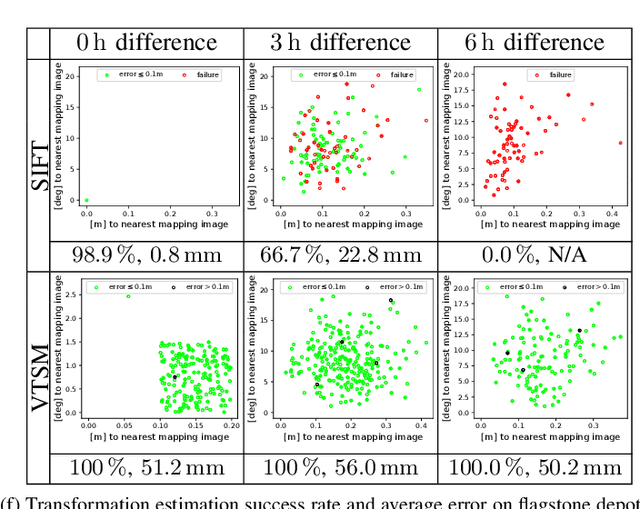
We consider the problem of rover relocalization in the context of the notional Mars Sample Return campaign. In this campaign, a rover (R1) needs to be capable of autonomously navigating and localizing itself within an area of approximately 50 x 50 m using reference images collected years earlier by another rover (R0). We propose a visual localizer that exhibits robustness to the relatively barren terrain that we expect to find in relevant areas, and to large lighting and viewpoint differences between R0 and R1. The localizer synthesizes partial renderings of a mesh built from reference R0 images and matches those to R1 images. We evaluate our method on a dataset totaling 2160 images covering the range of expected environmental conditions (terrain, lighting, approach angle). Experimental results show the effectiveness of our approach. This work informs the Mars Sample Return campaign on the choice of a site where Perseverance (R0) will place a set of sample tubes for future retrieval by another rover (R1).
Video Imitation GAN: Learning control policies by imitating raw videos using generative adversarial reward estimation
Oct 02, 2018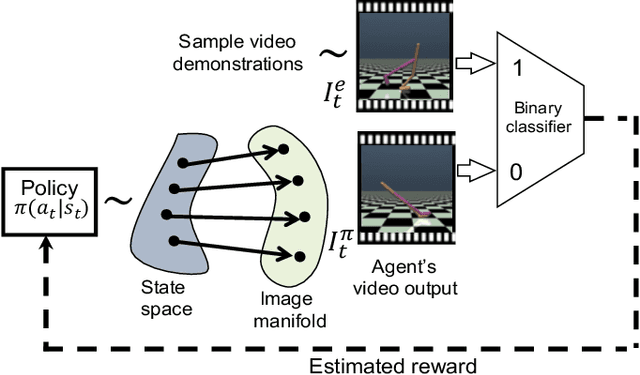
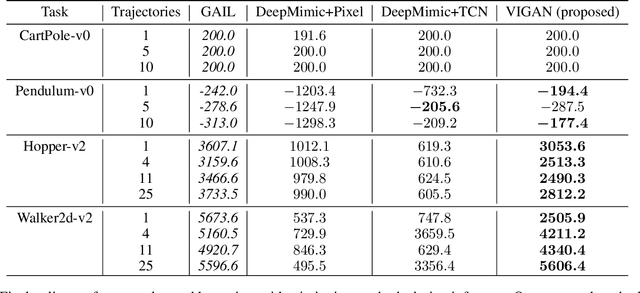
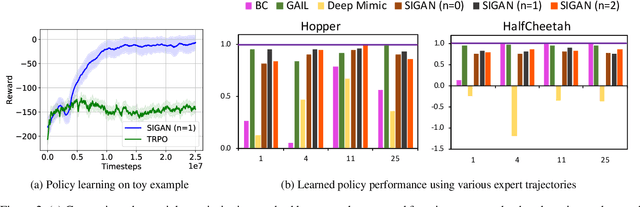
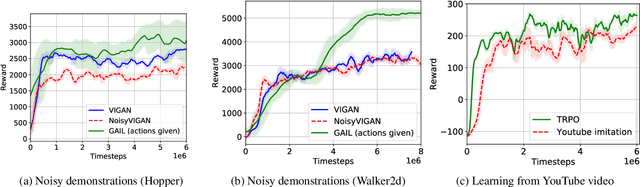
Natural imitation in humans usually consists of mimicking visual demonstrations of another person by continuously refining our skills until our performance is visually akin to the expert demonstrations. In this paper, we are interested in imitation learning of artificial agents in the natural setting - acquiring motor skills by watching raw video demonstrations. Traditional methods for learning from videos rely on extracting meaningful low-dimensional features from the videos followed by a separate hand-crafted reward estimation step based on feature separation between the agent and expert. We propose an imitation learning framework from raw video demonstrations, that reduces the dependence on hand engineered reward functions, by jointly learning the feature extraction and separation estimation steps, using generative adversarial networks. Additionally, we establish the equivalence between adversarial imitation from image manifolds and low-level state distribution matching, under certain conditions. Experimental results show that our proposed imitation learning method from raw videos produces a similar performance to state-of-the-art imitation learning techniques with low-level state and action information available while outperforming existing video imitation methods. Furthermore, we show that our method can learn action policies by imitating video demonstrations available on YouTube with performance comparable to learned agents from true reward signal. Please see the video at https://youtu.be/bvNpV2Q4rOA.
Constrained Exploration and Recovery from Experience Shaping
Sep 21, 2018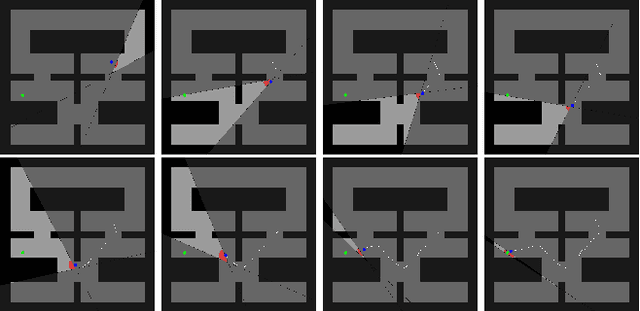
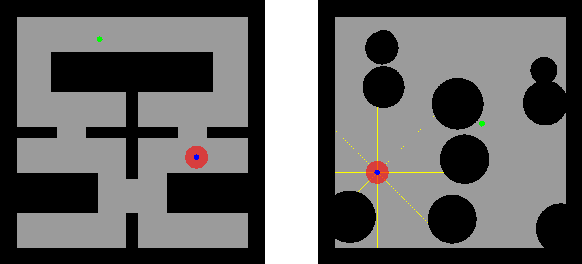
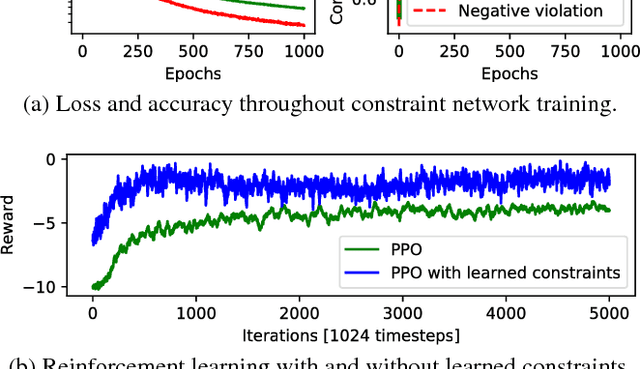

We consider the problem of reinforcement learning under safety requirements, in which an agent is trained to complete a given task, typically formalized as the maximization of a reward signal over time, while concurrently avoiding undesirable actions or states, associated to lower rewards, or penalties. The construction and balancing of different reward components can be difficult in the presence of multiple objectives, yet is crucial for producing a satisfying policy. For example, in reaching a target while avoiding obstacles, low collision penalties can lead to reckless movements while high penalties can discourage exploration. To circumvent this limitation, we examine the effect of past actions in terms of safety to estimate which are acceptable or should be avoided in the future. We then actively reshape the action space of the agent during reinforcement learning, so that reward-driven exploration is constrained within safety limits. We propose an algorithm enabling the learning of such safety constraints in parallel with reinforcement learning and demonstrate its effectiveness in terms of both task completion and training time.
Experimental Force-Torque Dataset for Robot Learning of Multi-Shape Insertion
Jul 25, 2018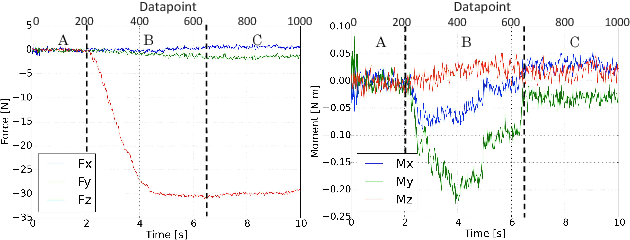
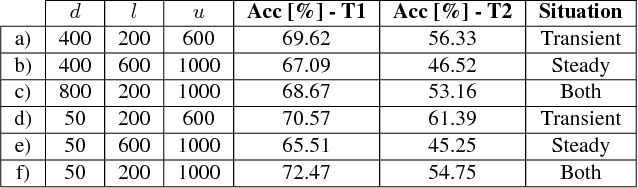

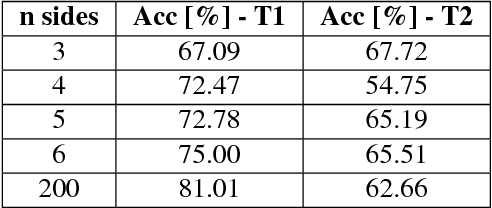
The accurate modeling of real-world systems and physical interactions is a common challenge towards the resolution of robotics tasks. Machine learning approaches have demonstrated significant results in the modeling of complex systems (e.g., articulated robot structures, cable stretch, fluid dynamics), or to learn robotics tasks (e.g., grasping, reaching) from raw sensor measurements without explicit programming, using reinforcement learning. However, a common bottleneck in machine learning techniques resides in the availability of suitable data. While many vision-based datasets have been released in the recent years, ones involving physical interactions, of particular interest for the robotic community, have been scarcer. In this paper, we present a public dataset on peg-in-hole insertion tasks containing force-torque and pose information for multiple variations of convex-shaped pegs. We demonstrate how this dataset can be used to train a robot to insert polyhedral pegs into holes using only 6-axis force/torque sensor measurements as inputs, as well as other tasks involving contact such as shape recognition.
MaestROB: A Robotics Framework for Integrated Orchestration of Low-Level Control and High-Level Reasoning
Jun 03, 2018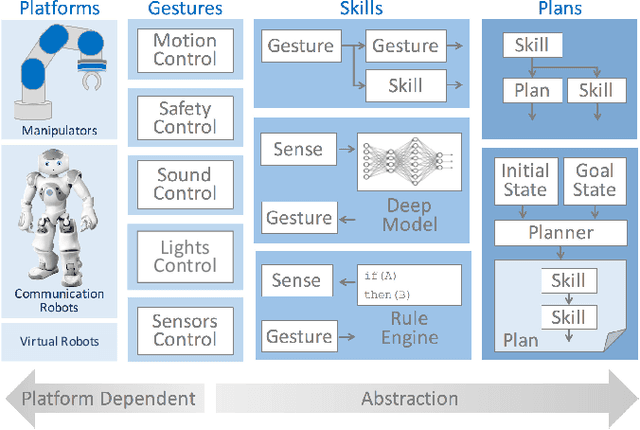
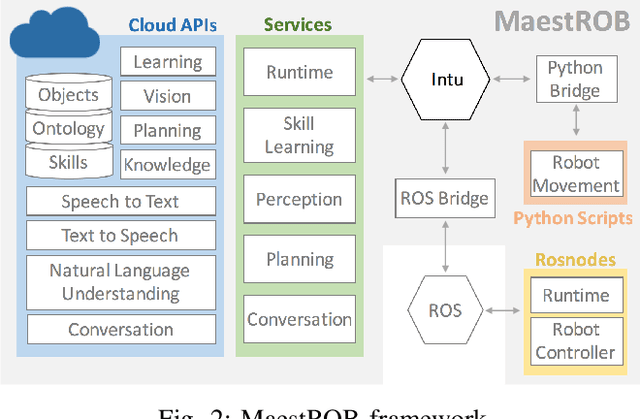
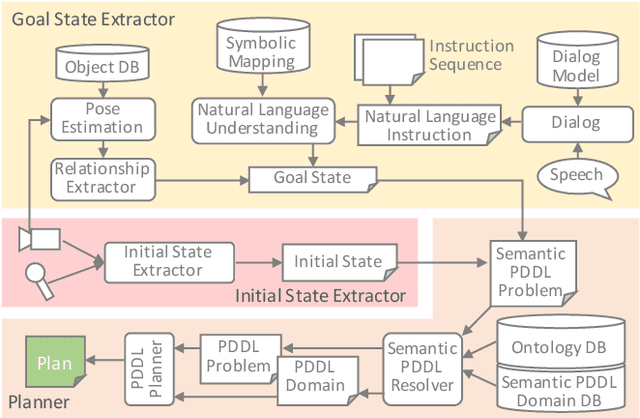
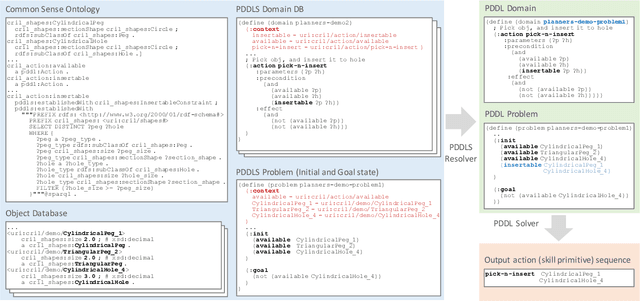
This paper describes a framework called MaestROB. It is designed to make the robots perform complex tasks with high precision by simple high-level instructions given by natural language or demonstration. To realize this, it handles a hierarchical structure by using the knowledge stored in the forms of ontology and rules for bridging among different levels of instructions. Accordingly, the framework has multiple layers of processing components; perception and actuation control at the low level, symbolic planner and Watson APIs for cognitive capabilities and semantic understanding, and orchestration of these components by a new open source robot middleware called Project Intu at its core. We show how this framework can be used in a complex scenario where multiple actors (human, a communication robot, and an industrial robot) collaborate to perform a common industrial task. Human teaches an assembly task to Pepper (a humanoid robot from SoftBank Robotics) using natural language conversation and demonstration. Our framework helps Pepper perceive the human demonstration and generate a sequence of actions for UR5 (collaborative robot arm from Universal Robots), which ultimately performs the assembly (e.g. insertion) task.
OptLayer - Practical Constrained Optimization for Deep Reinforcement Learning in the Real World
Feb 23, 2018
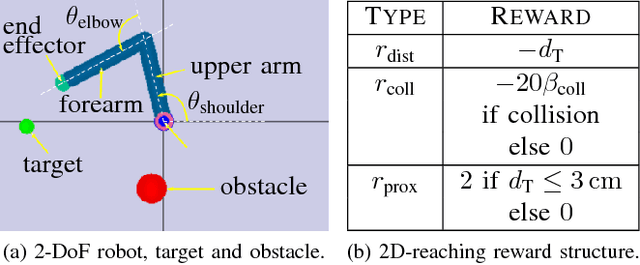

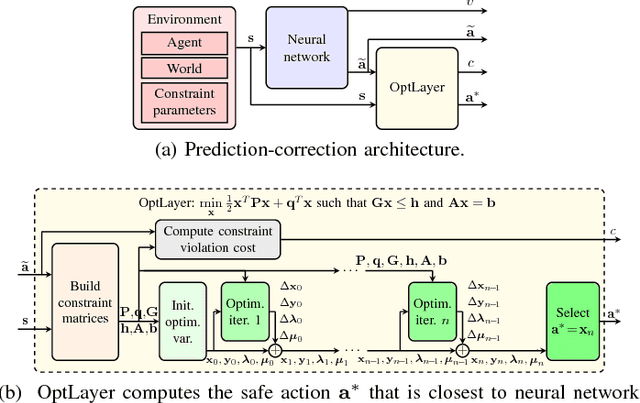
While deep reinforcement learning techniques have recently produced considerable achievements on many decision-making problems, their use in robotics has largely been limited to simulated worlds or restricted motions, since unconstrained trial-and-error interactions in the real world can have undesirable consequences for the robot or its environment. To overcome such limitations, we propose a novel reinforcement learning architecture, OptLayer, that takes as inputs possibly unsafe actions predicted by a neural network and outputs the closest actions that satisfy chosen constraints. While learning control policies often requires carefully crafted rewards and penalties while exploring the range of possible actions, OptLayer ensures that only safe actions are actually executed and unsafe predictions are penalized during training. We demonstrate the effectiveness of our approach on robot reaching tasks, both simulated and in the real world.