 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Vision based Sample-Tube Localization for Mars Sample Return
Mar 17, 2021

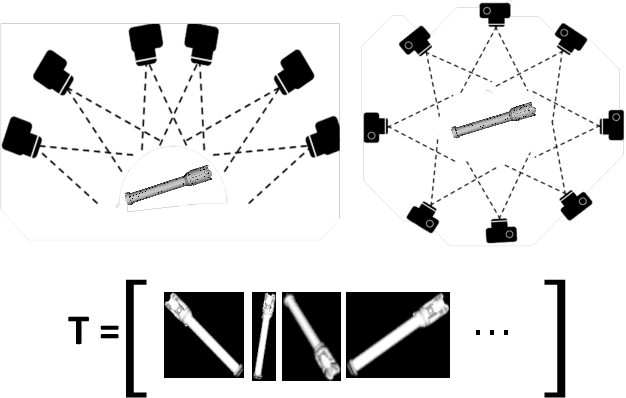
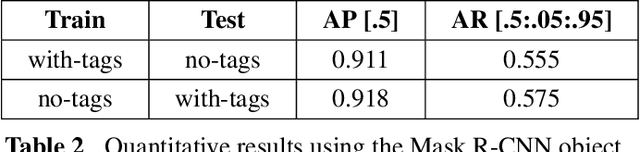
A potential Mars Sample Return (MSR) architecture is being jointly studied by NASA and ESA. As currently envisioned, the MSR campaign consists of a series of 3 missions: sample cache, fetch and return to Earth. In this paper, we focus on the fetch part of the MSR, and more specifically the problem of autonomously detecting and localizing sample tubes deposited on the Martian surface. Towards this end, we study two machine-vision based approaches: First, a geometry-driven approach based on template matching that uses hard-coded filters and a 3D shape model of the tube; and second, a data-driven approach based on convolutional neural networks (CNNs) and learned features. Furthermore, we present a large benchmark dataset of sample-tube images, collected in representative outdoor environments and annotated with ground truth segmentation masks and locations. The dataset was acquired systematically across different terrain, illumination conditions and dust-coverage; and benchmarking was performed to study the feasibility of each approach, their relative strengths and weaknesses, and robustness in the presence of adverse environmental conditions.
Rover Relocalization for Mars Sample Return by Virtual Template Synthesis and Matching
Mar 05, 2021
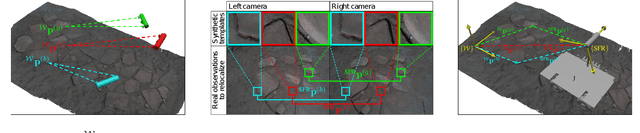

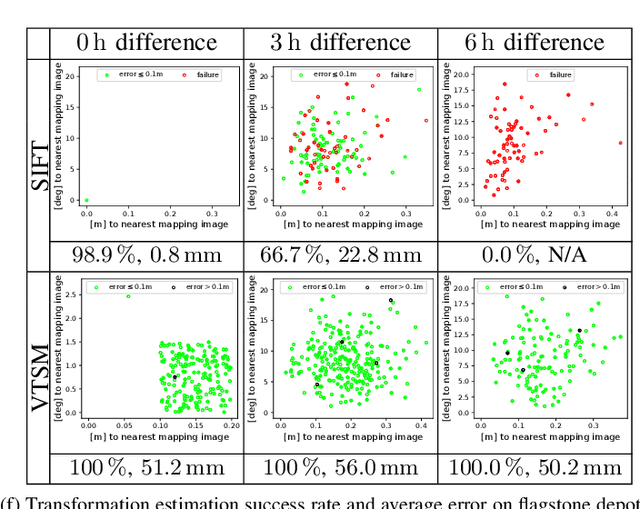
We consider the problem of rover relocalization in the context of the notional Mars Sample Return campaign. In this campaign, a rover (R1) needs to be capable of autonomously navigating and localizing itself within an area of approximately 50 x 50 m using reference images collected years earlier by another rover (R0). We propose a visual localizer that exhibits robustness to the relatively barren terrain that we expect to find in relevant areas, and to large lighting and viewpoint differences between R0 and R1. The localizer synthesizes partial renderings of a mesh built from reference R0 images and matches those to R1 images. We evaluate our method on a dataset totaling 2160 images covering the range of expected environmental conditions (terrain, lighting, approach angle). Experimental results show the effectiveness of our approach. This work informs the Mars Sample Return campaign on the choice of a site where Perseverance (R0) will place a set of sample tubes for future retrieval by another rover (R1).
Adversarial Inverse Graphics Networks: Learning 2D-to-3D Lifting and Image-to-Image Translation from Unpaired Supervision
Sep 02, 2017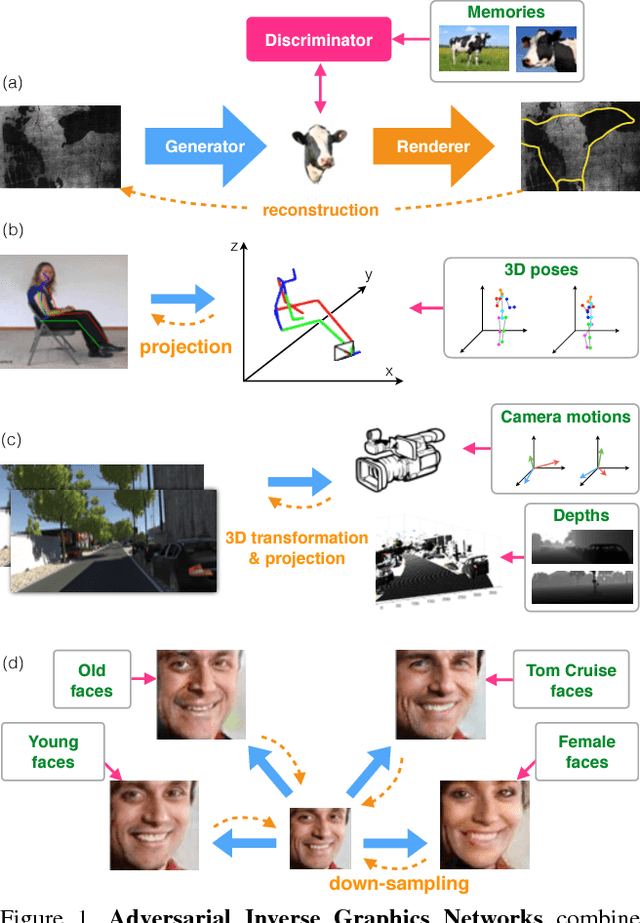
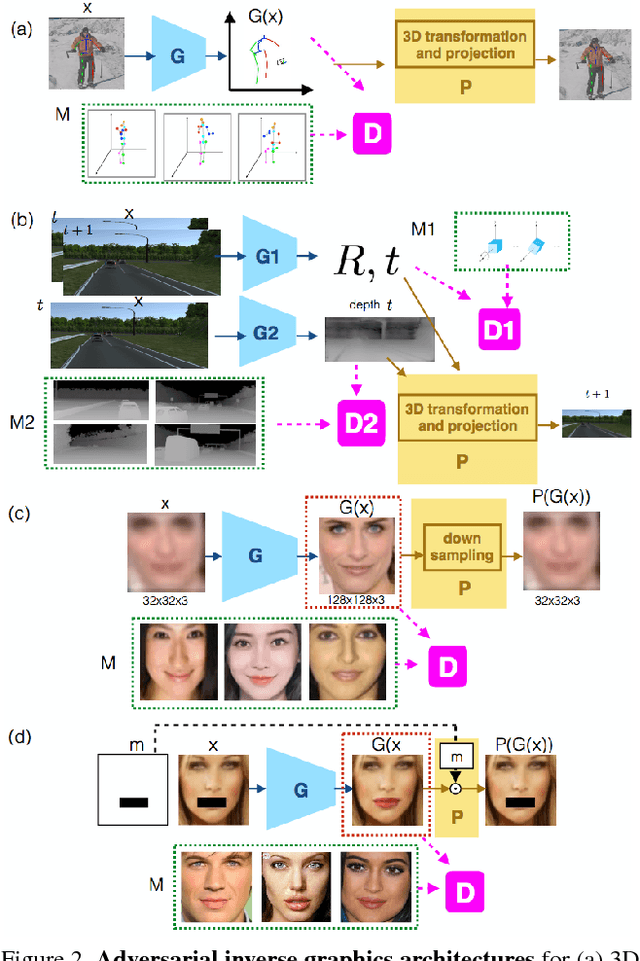
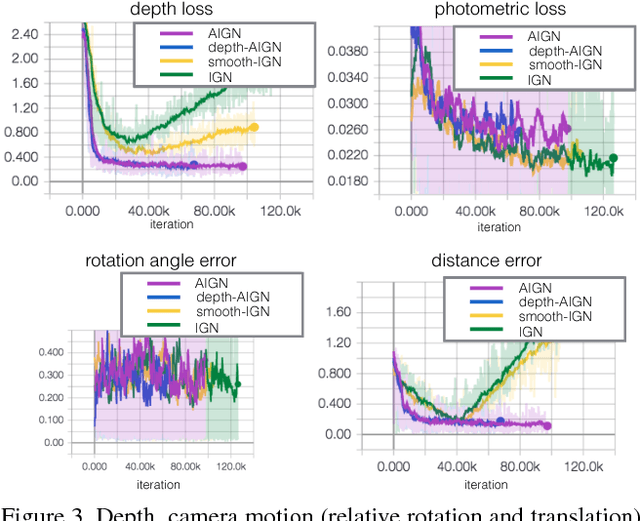
Researchers have developed excellent feed-forward models that learn to map images to desired outputs, such as to the images' latent factors, or to other images, using supervised learning. Learning such mappings from unlabelled data, or improving upon supervised models by exploiting unlabelled data, remains elusive. We argue that there are two important parts to learning without annotations: (i) matching the predictions to the input observations, and (ii) matching the predictions to known priors. We propose Adversarial Inverse Graphics networks (AIGNs): weakly supervised neural network models that combine feedback from rendering their predictions, with distribution matching between their predictions and a collection of ground-truth factors. We apply AIGNs to 3D human pose estimation and 3D structure and egomotion estimation, and outperform models supervised by only paired annotations. We further apply AIGNs to facial image transformation using super-resolution and inpainting renderers, while deliberately adding biases in the ground-truth datasets. Our model seamlessly incorporates such biases, rendering input faces towards young, old, feminine, masculine or Tom Cruise-like equivalents (depending on the chosen bias), or adding lip and nose augmentations while inpainting concealed lips and noses.