 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep OC-SORT: Multi-Pedestrian Tracking by Adaptive Re-Identification
Feb 23, 2023



Motion-based association for Multi-Object Tracking (MOT) has recently re-achieved prominence with the rise of powerful object detectors. Despite this, little work has been done to incorporate appearance cues beyond simple heuristic models that lack robustness to feature degradation. In this paper, we propose a novel way to leverage objects' appearances to adaptively integrate appearance matching into existing high-performance motion-based methods. Building upon the pure motion-based method OC-SORT, we achieve 1st place on MOT20 and 2nd place on MOT17 with 63.9 and 64.9 HOTA, respectively. We also achieve 61.3 HOTA on the challenging DanceTrack benchmark as a new state-of-the-art even compared to more heavily-designed methods. The code and models are available at \url{https://github.com/GerardMaggiolino/Deep-OC-SORT}.
Machine Vision based Sample-Tube Localization for Mars Sample Return
Mar 17, 2021

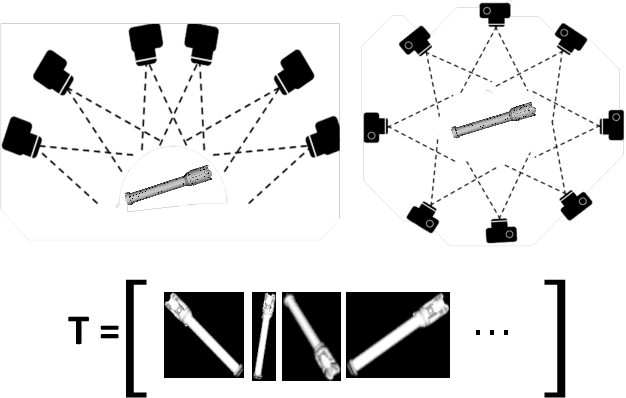
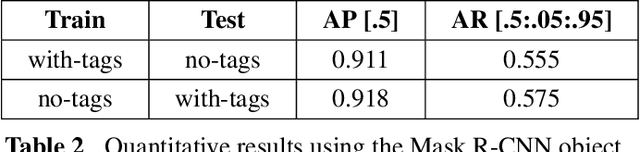
A potential Mars Sample Return (MSR) architecture is being jointly studied by NASA and ESA. As currently envisioned, the MSR campaign consists of a series of 3 missions: sample cache, fetch and return to Earth. In this paper, we focus on the fetch part of the MSR, and more specifically the problem of autonomously detecting and localizing sample tubes deposited on the Martian surface. Towards this end, we study two machine-vision based approaches: First, a geometry-driven approach based on template matching that uses hard-coded filters and a 3D shape model of the tube; and second, a data-driven approach based on convolutional neural networks (CNNs) and learned features. Furthermore, we present a large benchmark dataset of sample-tube images, collected in representative outdoor environments and annotated with ground truth segmentation masks and locations. The dataset was acquired systematically across different terrain, illumination conditions and dust-coverage; and benchmarking was performed to study the feasibility of each approach, their relative strengths and weaknesses, and robustness in the presence of adverse environmental conditions.
Rover Relocalization for Mars Sample Return by Virtual Template Synthesis and Matching
Mar 05, 2021
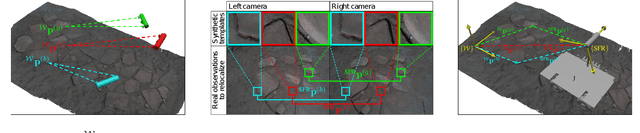

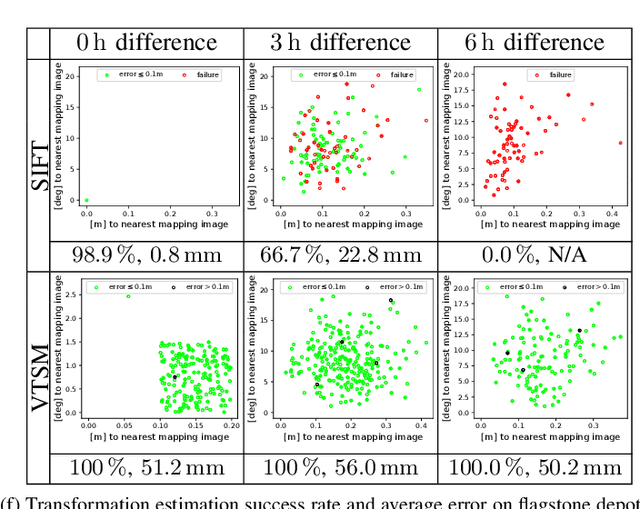
We consider the problem of rover relocalization in the context of the notional Mars Sample Return campaign. In this campaign, a rover (R1) needs to be capable of autonomously navigating and localizing itself within an area of approximately 50 x 50 m using reference images collected years earlier by another rover (R0). We propose a visual localizer that exhibits robustness to the relatively barren terrain that we expect to find in relevant areas, and to large lighting and viewpoint differences between R0 and R1. The localizer synthesizes partial renderings of a mesh built from reference R0 images and matches those to R1 images. We evaluate our method on a dataset totaling 2160 images covering the range of expected environmental conditions (terrain, lighting, approach angle). Experimental results show the effectiveness of our approach. This work informs the Mars Sample Return campaign on the choice of a site where Perseverance (R0) will place a set of sample tubes for future retrieval by another rover (R1).