 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Framework for Real-world Multiple Sound Source 2D Localization
Dec 10, 2020
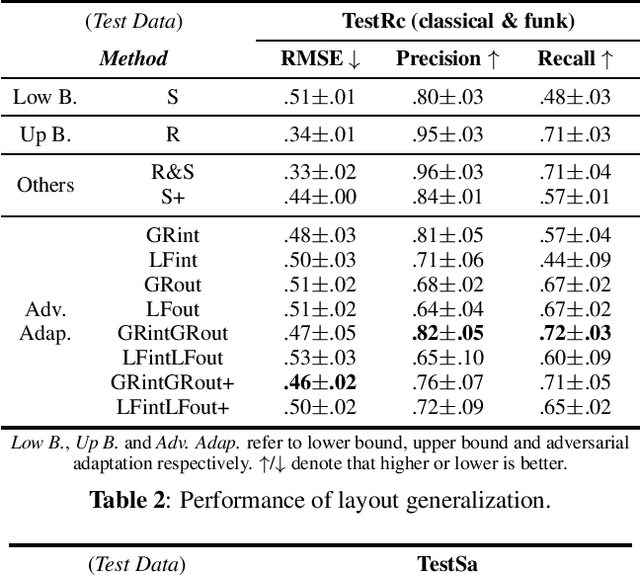
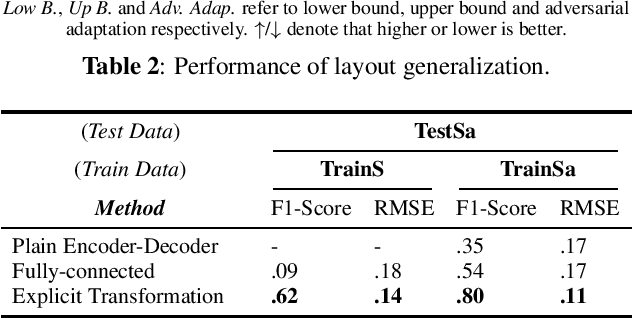
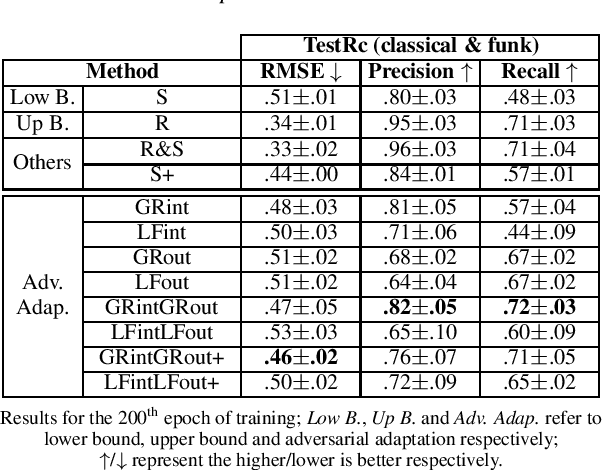
Deep neural networks have recently led to promising results for the task of multiple sound source localization. Yet, they require a lot of training data to cover a variety of acoustic conditions and microphone array layouts. One can leverage acoustic simulators to inexpensively generate labeled training data. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. Moreover, learning for different microphone array layouts makes the task more complicated due to the infinite number of possible layouts. We propose to use adversarial learning methods to close the gap between synthetic and real domains. Our novel ensemble-discrimination method significantly improves the localization performance without requiring any label from the real data. Furthermore, we propose a novel explicit transformation layer to be embedded in the localization architecture. It enables the model to be trained with data from specific microphone array layouts while generalizing well to unseen layouts during inference.
Ensemble of Discriminators for Domain Adaptation in Multiple Sound Source 2D Localization
Dec 10, 2020
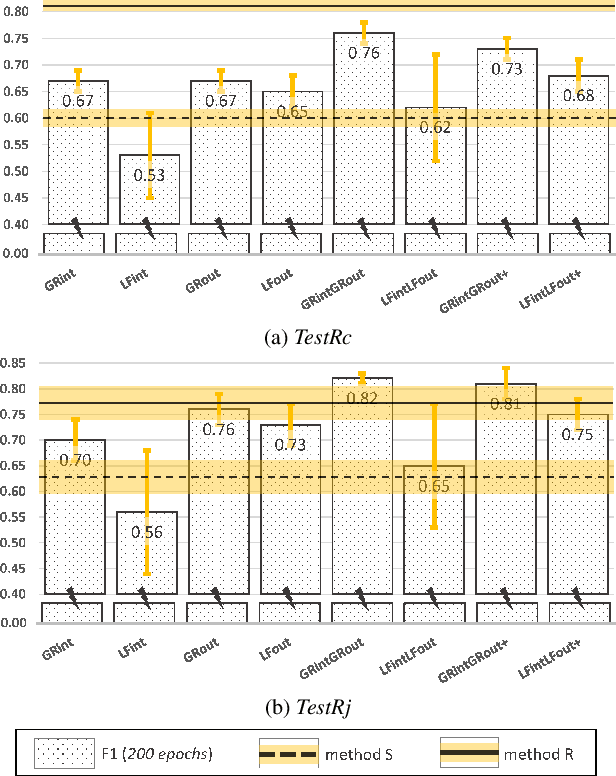
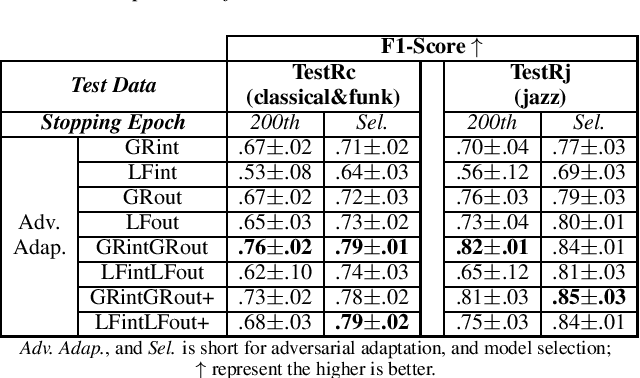
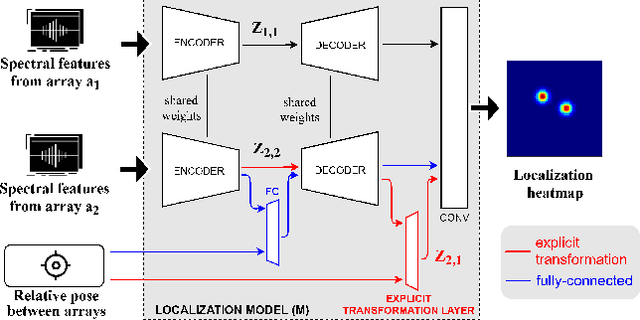
This paper introduces an ensemble of discriminators that improves the accuracy of a domain adaptation technique for the localization of multiple sound sources. Recently, deep neural networks have led to promising results for this task, yet they require a large amount of labeled data for training. Recording and labeling such datasets is very costly, especially because data needs to be diverse enough to cover different acoustic conditions. In this paper, we leverage acoustic simulators to inexpensively generate labeled training samples. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. For this, we explore two domain adaptation methods using adversarial learning for sound source localization which use labeled synthetic data and unlabeled real data. We propose a novel ensemble approach that combines discriminators applied at different feature levels of the localization model. Experiments show that our ensemble discrimination method significantly improves the localization performance without requiring any label from the real data.
Learning Multiple Sound Source 2D Localization
Dec 10, 2020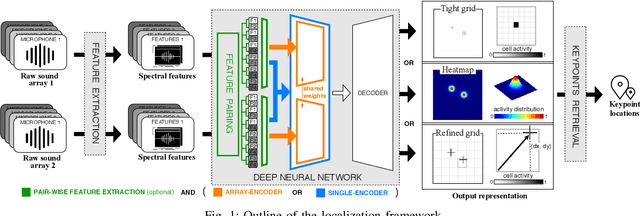
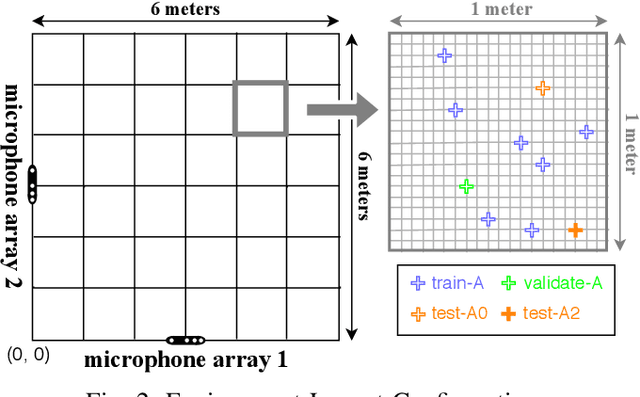
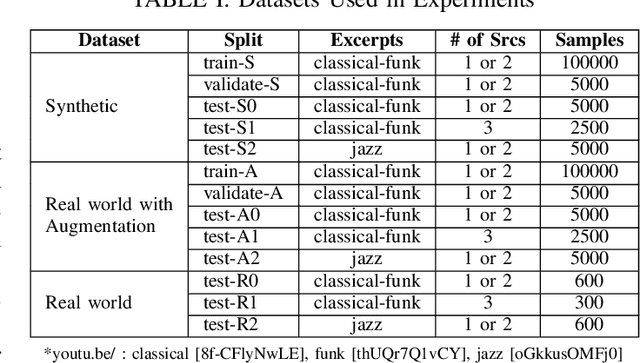
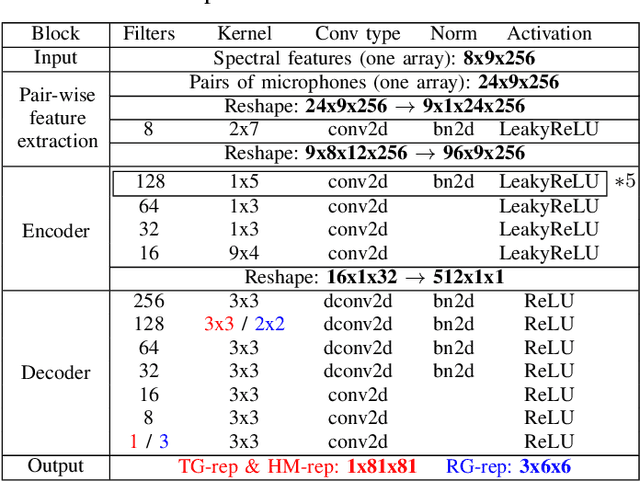
In this paper, we propose novel deep learning based algorithms for multiple sound source localization. Specifically, we aim to find the 2D Cartesian coordinates of multiple sound sources in an enclosed environment by using multiple microphone arrays. To this end, we use an encoding-decoding architecture and propose two improvements on it to accomplish the task. In addition, we also propose two novel localization representations which increase the accuracy. Lastly, new metrics are developed relying on resolution-based multiple source association which enables us to evaluate and compare different localization approaches. We tested our method on both synthetic and real world data. The results show that our method improves upon the previous baseline approach for this problem.
Experimental Force-Torque Dataset for Robot Learning of Multi-Shape Insertion
Jul 25, 2018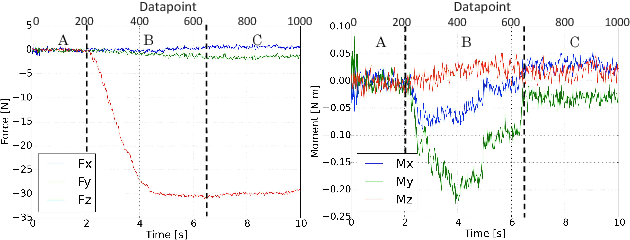
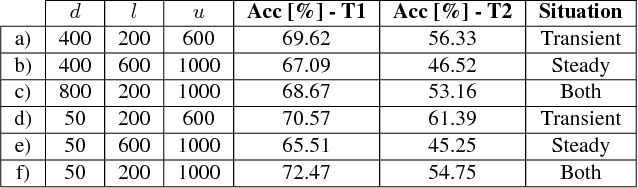

The accurate modeling of real-world systems and physical interactions is a common challenge towards the resolution of robotics tasks. Machine learning approaches have demonstrated significant results in the modeling of complex systems (e.g., articulated robot structures, cable stretch, fluid dynamics), or to learn robotics tasks (e.g., grasping, reaching) from raw sensor measurements without explicit programming, using reinforcement learning. However, a common bottleneck in machine learning techniques resides in the availability of suitable data. While many vision-based datasets have been released in the recent years, ones involving physical interactions, of particular interest for the robotic community, have been scarcer. In this paper, we present a public dataset on peg-in-hole insertion tasks containing force-torque and pose information for multiple variations of convex-shaped pegs. We demonstrate how this dataset can be used to train a robot to insert polyhedral pegs into holes using only 6-axis force/torque sensor measurements as inputs, as well as other tasks involving contact such as shape recognition.
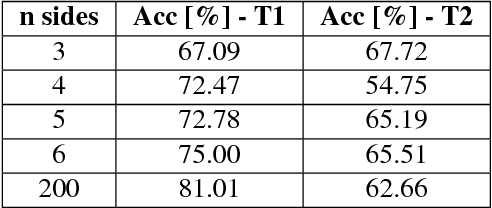
Transfer Learning From Synthetic To Real Images Using Variational Autoencoders For Precise Position Detection
Jul 04, 2018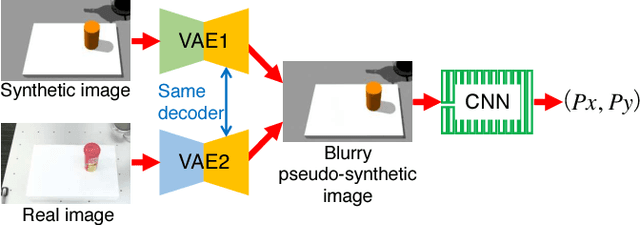
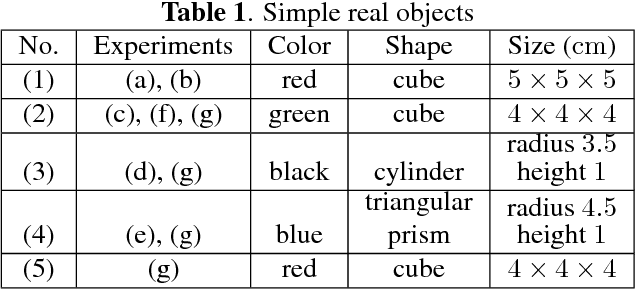
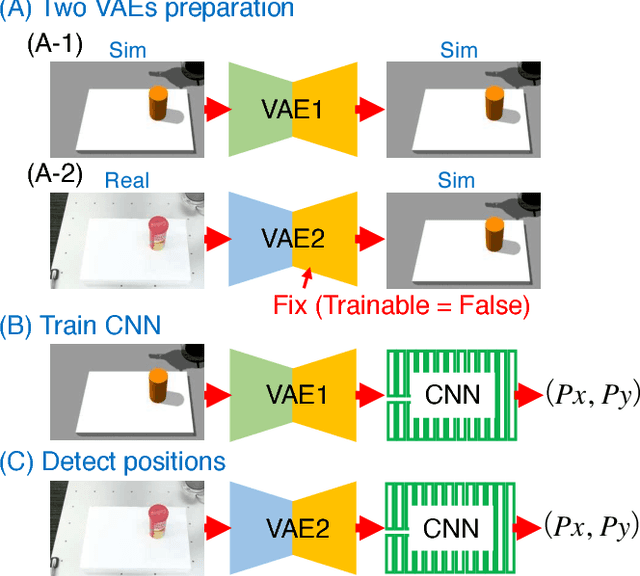

Capturing and labeling camera images in the real world is an expensive task, whereas synthesizing labeled images in a simulation environment is easy for collecting large-scale image data. However, learning from only synthetic images may not achieve the desired performance in the real world due to a gap between synthetic and real images. We propose a method that transfers learned detection of an object position from a simulation environment to the real world. This method uses only a significantly limited dataset of real images while leveraging a large dataset of synthetic images using variational autoencoders. Additionally, the proposed method consistently performed well in different lighting conditions, in the presence of other distractor objects, and on different backgrounds. Experimental results showed that it achieved accuracy of 1.5mm to 3.5mm on average. Furthermore, we showed how the method can be used in a real-world scenario like a "pick-and-place" robotic task.
Deep Reinforcement Learning for High Precision Assembly Tasks
Sep 22, 2017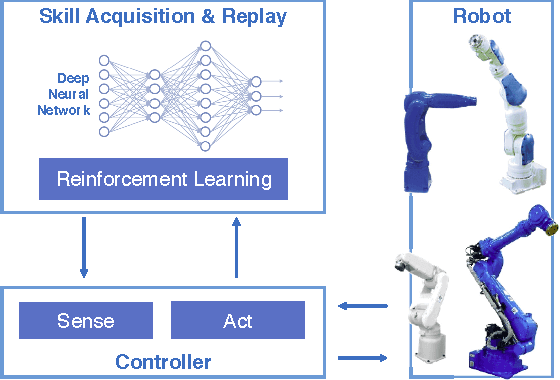
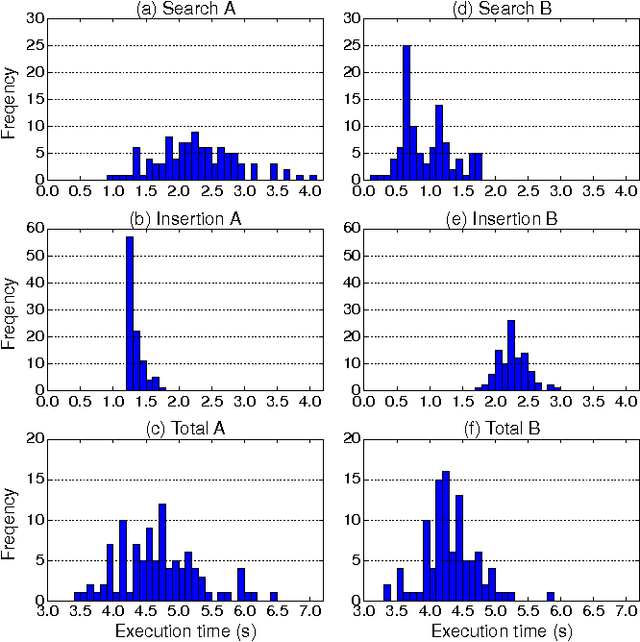

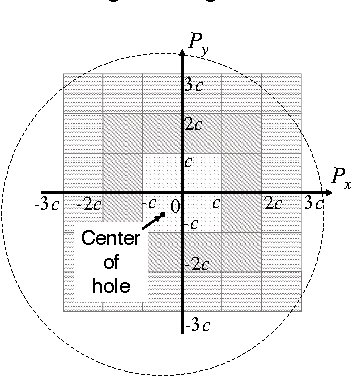
High precision assembly of mechanical parts requires accuracy exceeding the robot precision. Conventional part mating methods used in the current manufacturing requires tedious tuning of numerous parameters before deployment. We show how the robot can successfully perform a tight clearance peg-in-hole task through training a recurrent neural network with reinforcement learning. In addition to saving the manual effort, the proposed technique also shows robustness against position and angle errors for the peg-in-hole task. The neural network learns to take the optimal action by observing the robot sensors to estimate the system state. The advantages of our proposed method is validated experimentally on a 7-axis articulated robot arm.
Transfer learning from synthetic to real images using variational autoencoders for robotic applications
Sep 20, 2017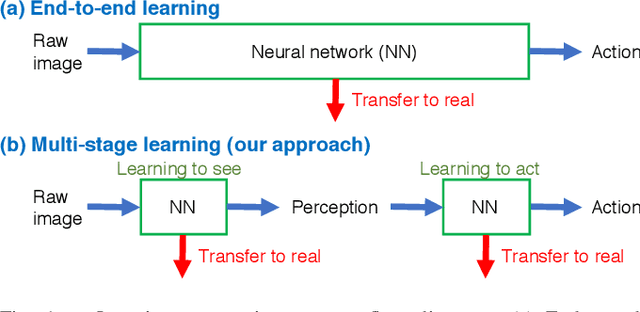
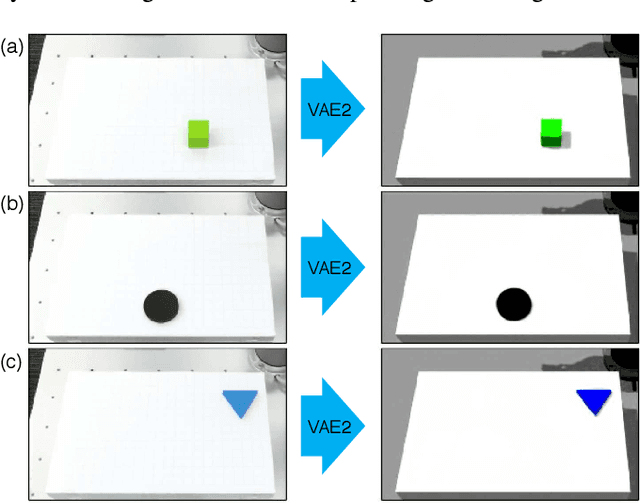

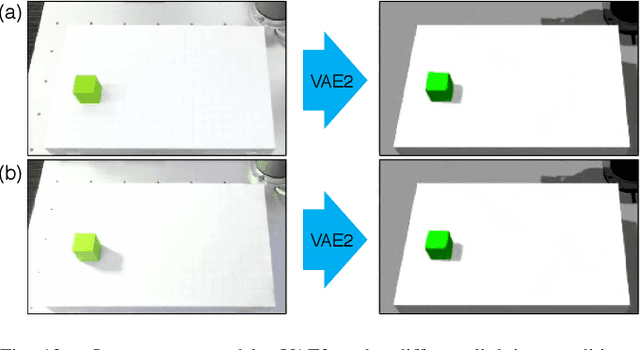
Robotic learning in simulation environments provides a faster, more scalable, and safer training methodology than learning directly with physical robots. Also, synthesizing images in a simulation environment for collecting large-scale image data is easy, whereas capturing camera images in the real world is time consuming and expensive. However, learning from only synthetic images may not achieve the desired performance in real environments due to the gap between synthetic and real images. We thus propose a method that transfers learned capability of detecting object position from a simulation environment to the real world. Our method enables us to use only a very limited dataset of real images while leveraging a large dataset of synthetic images using multiple variational autoencoders. It detects object positions 6 to 7 times more precisely than the baseline of directly learning from the dataset of the real images. Object position estimation under varying environmental conditions forms one of the underlying requirement for standard robotic manipulation tasks. We show that the proposed method performs robustly in different lighting conditions or with other distractor objects present for this requirement. Using this detected object position, we transfer pick-and-place or reaching tasks learned in a simulation environment to an actual physical robot without re-training.