 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning from synthetic to real images using variational autoencoders for robotic applications
Paper and Code
Sep 20, 2017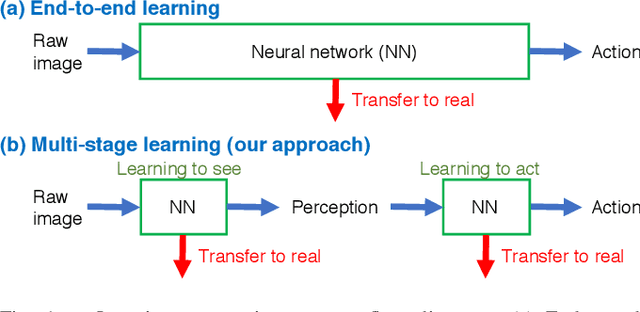
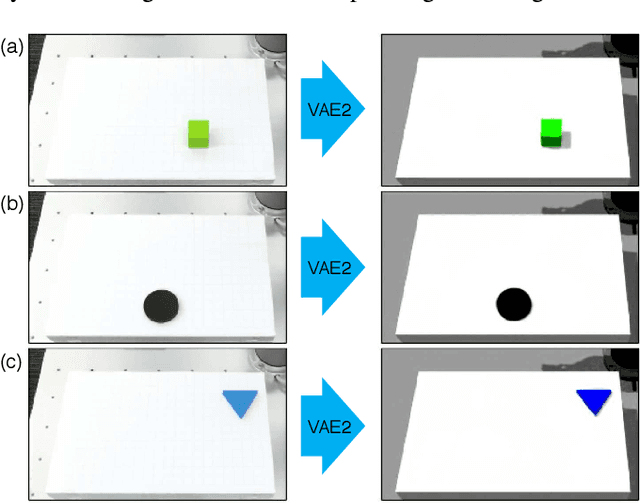

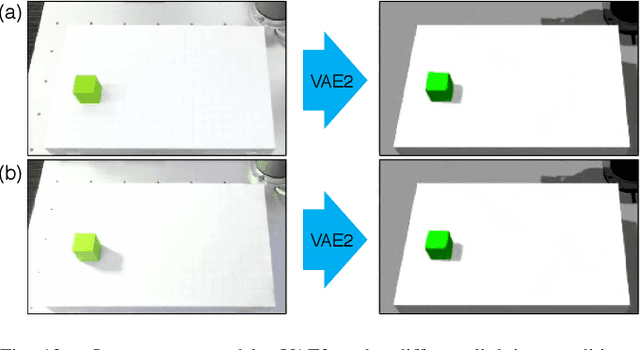
Robotic learning in simulation environments provides a faster, more scalable, and safer training methodology than learning directly with physical robots. Also, synthesizing images in a simulation environment for collecting large-scale image data is easy, whereas capturing camera images in the real world is time consuming and expensive. However, learning from only synthetic images may not achieve the desired performance in real environments due to the gap between synthetic and real images. We thus propose a method that transfers learned capability of detecting object position from a simulation environment to the real world. Our method enables us to use only a very limited dataset of real images while leveraging a large dataset of synthetic images using multiple variational autoencoders. It detects object positions 6 to 7 times more precisely than the baseline of directly learning from the dataset of the real images. Object position estimation under varying environmental conditions forms one of the underlying requirement for standard robotic manipulation tasks. We show that the proposed method performs robustly in different lighting conditions or with other distractor objects present for this requirement. Using this detected object position, we transfer pick-and-place or reaching tasks learned in a simulation environment to an actual physical robot without re-training.