 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDancing along Battery: Enabling Transformer with Run-time Reconfigurability on Mobile Devices
Feb 12, 2021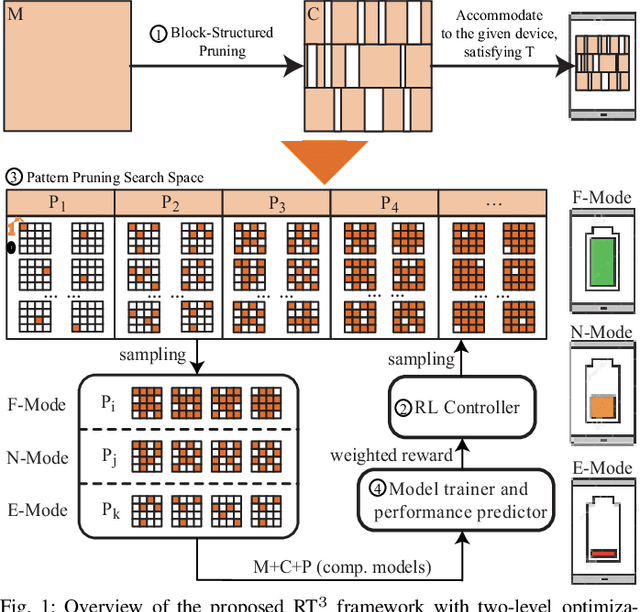
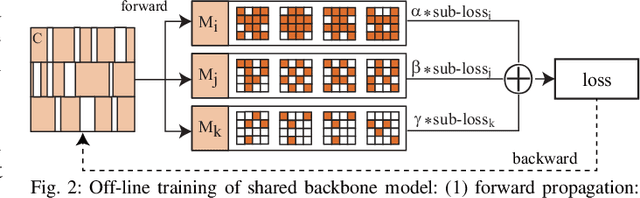
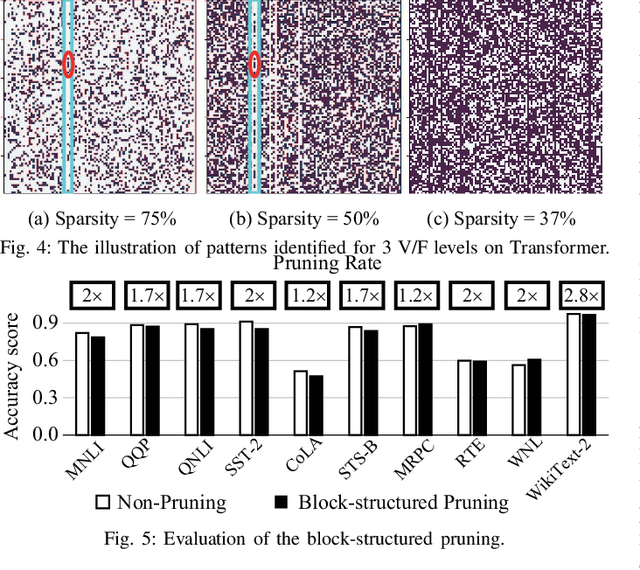

A pruning-based AutoML framework for run-time reconfigurability, namely RT3, is proposed in this work. This enables Transformer-based large Natural Language Processing (NLP) models to be efficiently executed on resource-constrained mobile devices and reconfigured (i.e., switching models for dynamic hardware conditions) at run-time. Such reconfigurability is the key to save energy for battery-powered mobile devices, which widely use dynamic voltage and frequency scaling (DVFS) technique for hardware reconfiguration to prolong battery life. In this work, we creatively explore a hybrid block-structured pruning (BP) and pattern pruning (PP) for Transformer-based models and first attempt to combine hardware and software reconfiguration to maximally save energy for battery-powered mobile devices. Specifically, RT3 integrates two-level optimizations: First, it utilizes an efficient BP as the first-step compression for resource-constrained mobile devices; then, RT3 heuristically generates a shrunken search space based on the first level optimization and searches multiple pattern sets with diverse sparsity for PP via reinforcement learning to support lightweight software reconfiguration, which corresponds to available frequency levels of DVFS (i.e., hardware reconfiguration). At run-time, RT3 can switch the lightweight pattern sets within 45ms to guarantee the required real-time constraint at different frequency levels. Results further show that RT3 can prolong battery life over 4x improvement with less than 1% accuracy loss for Transformer and 1.5% score decrease for DistilBERT.
Standing on the Shoulders of Giants: Hardware and Neural Architecture Co-Search with Hot Start
Jul 17, 2020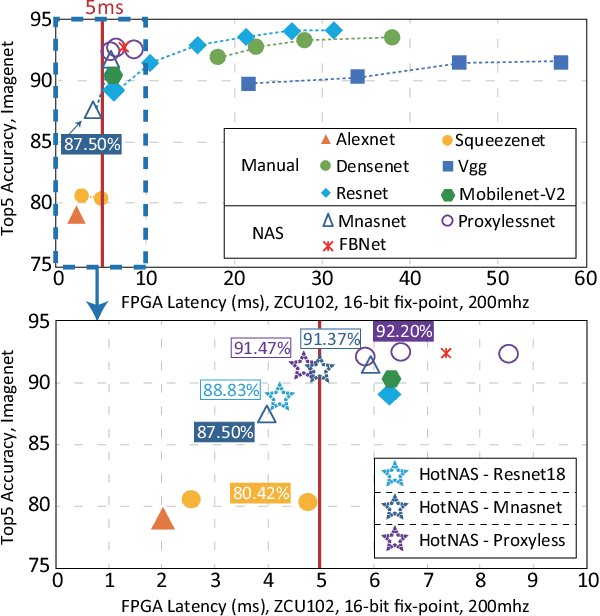
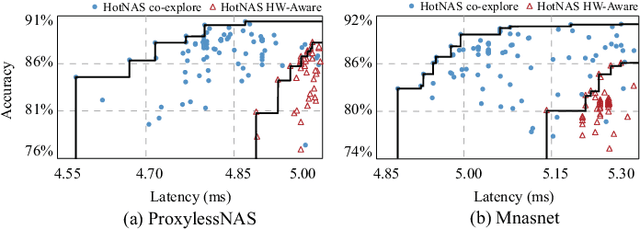
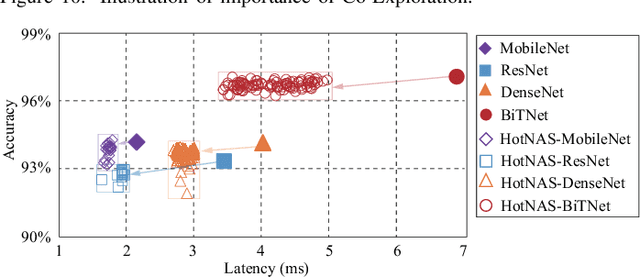
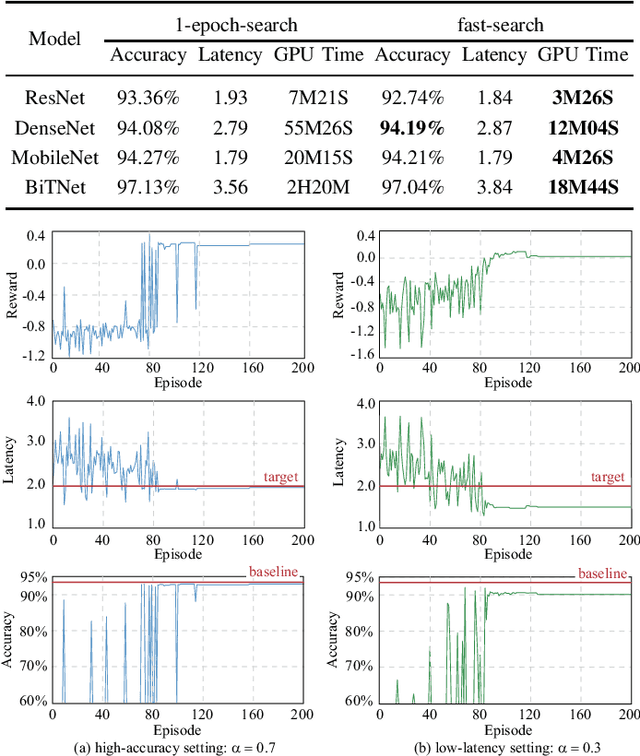
Hardware and neural architecture co-search that automatically generates Artificial Intelligence (AI) solutions from a given dataset is promising to promote AI democratization; however, the amount of time that is required by current co-search frameworks is in the order of hundreds of GPU hours for one target hardware. This inhibits the use of such frameworks on commodity hardware. The root cause of the low efficiency in existing co-search frameworks is the fact that they start from a "cold" state (i.e., search from scratch). In this paper, we propose a novel framework, namely HotNAS, that starts from a "hot" state based on a set of existing pre-trained models (a.k.a. model zoo) to avoid lengthy training time. As such, the search time can be reduced from 200 GPU hours to less than 3 GPU hours. In HotNAS, in addition to hardware design space and neural architecture search space, we further integrate a compression space to conduct model compressing during the co-search, which creates new opportunities to reduce latency but also brings challenges. One of the key challenges is that all of the above search spaces are coupled with each other, e.g., compression may not work without hardware design support. To tackle this issue, HotNAS builds a chain of tools to design hardware to support compression, based on which a global optimizer is developed to automatically co-search all the involved search spaces. Experiments on ImageNet dataset and Xilinx FPGA show that, within the timing constraint of 5ms, neural architectures generated by HotNAS can achieve up to 5.79% Top-1 and 3.97% Top-5 accuracy gain, compared with the existing ones.
Continual Learning via Online Leverage Score Sampling
Aug 01, 2019

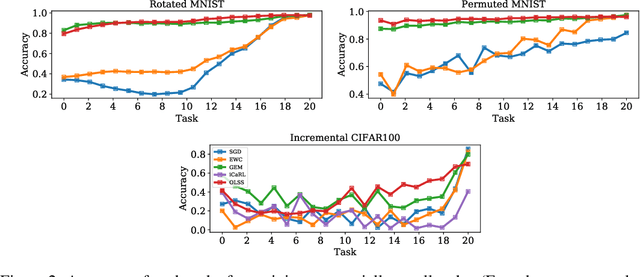
In order to mimic the human ability of continual acquisition and transfer of knowledge across various tasks, a learning system needs the capability for continual learning, effectively utilizing the previously acquired skills. As such, the key challenge is to transfer and generalize the knowledge learned from one task to other tasks, avoiding forgetting and interference of previous knowledge and improving the overall performance. In this paper, within the continual learning paradigm, we introduce a method that effectively forgets the less useful data samples continuously and allows beneficial information to be kept for training of the subsequent tasks, in an online manner. The method uses statistical leverage score information to measure the importance of the data samples in every task and adopts frequent directions approach to enable a continual or life-long learning property. This effectively maintains a constant training size across all tasks. We first provide mathematical intuition for the method and then demonstrate its effectiveness in avoiding catastrophic forgetting and computational efficiency on continual learning of classification tasks when compared with the existing state-of-the-art techniques.
Model-based Deep Reinforcement Learning for Dynamic Portfolio Optimization
Jan 25, 2019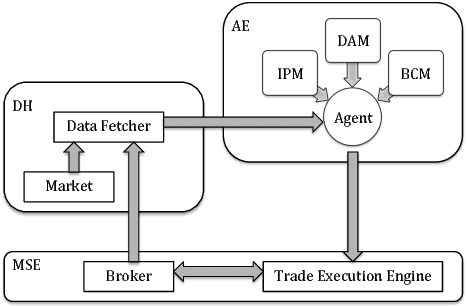
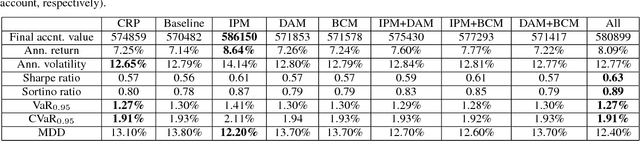
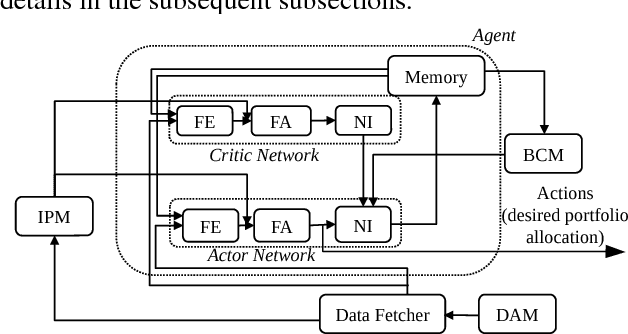
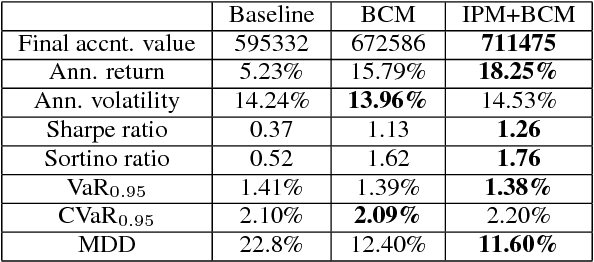
Dynamic portfolio optimization is the process of sequentially allocating wealth to a collection of assets in some consecutive trading periods, based on investors' return-risk profile. Automating this process with machine learning remains a challenging problem. Here, we design a deep reinforcement learning (RL) architecture with an autonomous trading agent such that, investment decisions and actions are made periodically, based on a global objective, with autonomy. In particular, without relying on a purely model-free RL agent, we train our trading agent using a novel RL architecture consisting of an infused prediction module (IPM), a generative adversarial data augmentation module (DAM) and a behavior cloning module (BCM). Our model-based approach works with both on-policy or off-policy RL algorithms. We further design the back-testing and execution engine which interact with the RL agent in real time. Using historical {\em real} financial market data, we simulate trading with practical constraints, and demonstrate that our proposed model is robust, profitable and risk-sensitive, as compared to baseline trading strategies and model-free RL agents from prior work.
Internal Model from Observations for Reward Shaping
Oct 14, 2018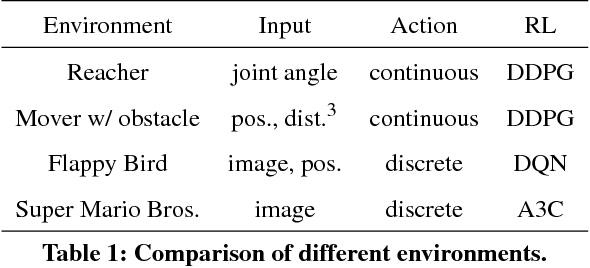
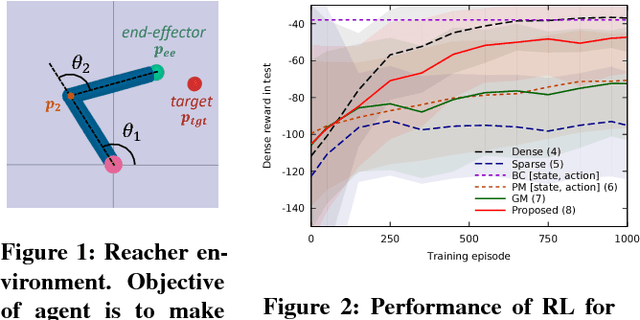
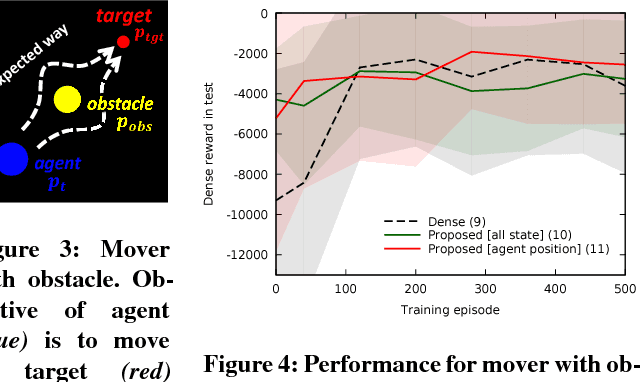
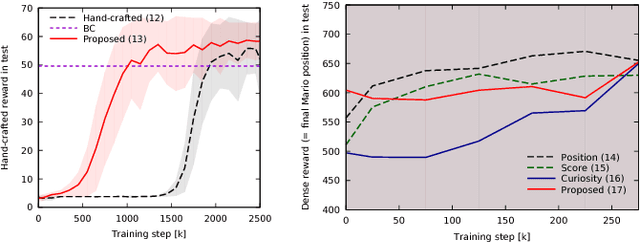
Reinforcement learning methods require careful design involving a reward function to obtain the desired action policy for a given task. In the absence of hand-crafted reward functions, prior work on the topic has proposed several methods for reward estimation by using expert state trajectories and action pairs. However, there are cases where complete or good action information cannot be obtained from expert demonstrations. We propose a novel reinforcement learning method in which the agent learns an internal model of observation on the basis of expert-demonstrated state trajectories to estimate rewards without completely learning the dynamics of the external environment from state-action pairs. The internal model is obtained in the form of a predictive model for the given expert state distribution. During reinforcement learning, the agent predicts the reward as a function of the difference between the actual state and the state predicted by the internal model. We conducted multiple experiments in environments of varying complexity, including the Super Mario Bros and Flappy Bird games. We show our method successfully trains good policies directly from expert game-play videos.
Transfer Learning From Synthetic To Real Images Using Variational Autoencoders For Precise Position Detection
Jul 04, 2018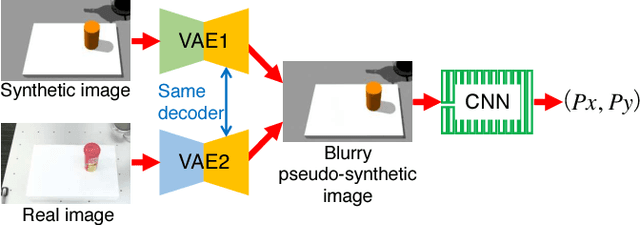
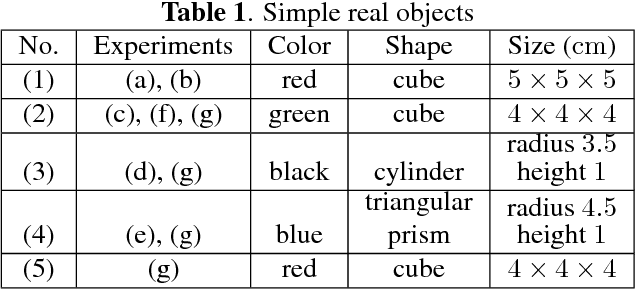
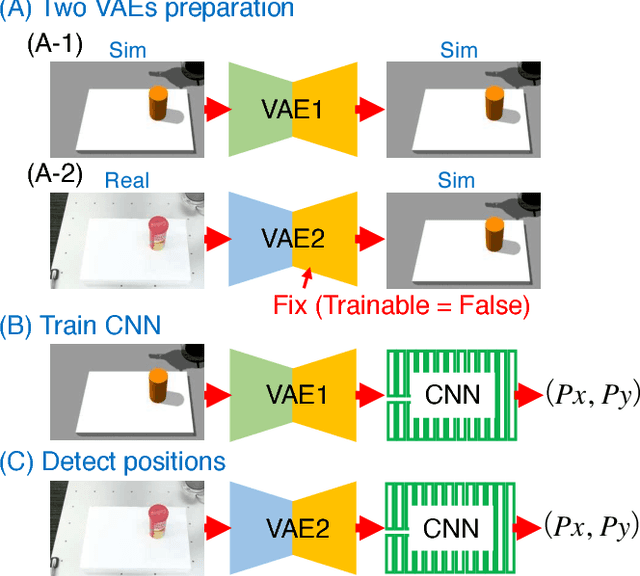

Capturing and labeling camera images in the real world is an expensive task, whereas synthesizing labeled images in a simulation environment is easy for collecting large-scale image data. However, learning from only synthetic images may not achieve the desired performance in the real world due to a gap between synthetic and real images. We propose a method that transfers learned detection of an object position from a simulation environment to the real world. This method uses only a significantly limited dataset of real images while leveraging a large dataset of synthetic images using variational autoencoders. Additionally, the proposed method consistently performed well in different lighting conditions, in the presence of other distractor objects, and on different backgrounds. Experimental results showed that it achieved accuracy of 1.5mm to 3.5mm on average. Furthermore, we showed how the method can be used in a real-world scenario like a "pick-and-place" robotic task.
Object Detection using Domain Randomization and Generative Adversarial Refinement of Synthetic Images
Jun 11, 2018

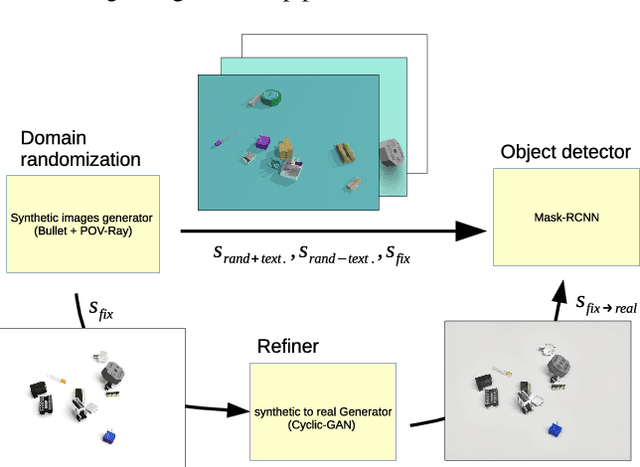
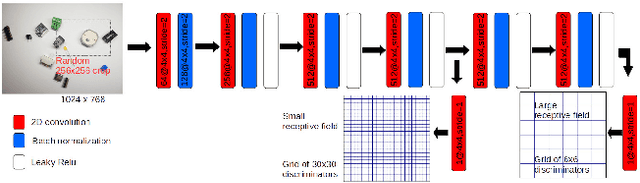
In this work, we present an application of domain randomization and generative adversarial networks (GAN) to train a near real-time object detector for industrial electric parts, entirely in a simulated environment. Large scale availability of labelled real world data is typically rare and difficult to obtain in many industrial settings. As such here, only a few hundred of unlabelled real images are used to train a Cyclic-GAN network, in combination with various degree of domain randomization procedures. We demonstrate that this enables robust translation of synthetic images to the real world domain. We show that a combination of the original synthetic (simulation) and GAN translated images, when used for training a Mask-RCNN object detection network achieves greater than 0.95 mean average precision in detecting and classifying a collection of industrial electric parts. We evaluate the performance across different combinations of training data.
Automated flow for compressing convolution neural networks for efficient edge-computation with FPGA
Dec 18, 2017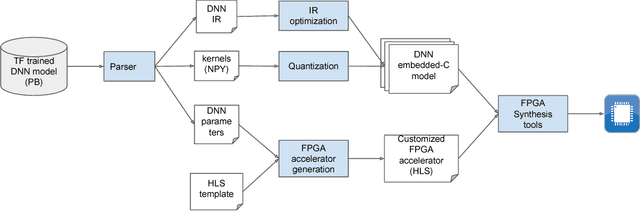
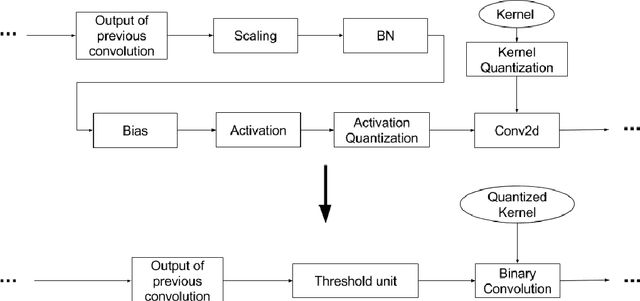
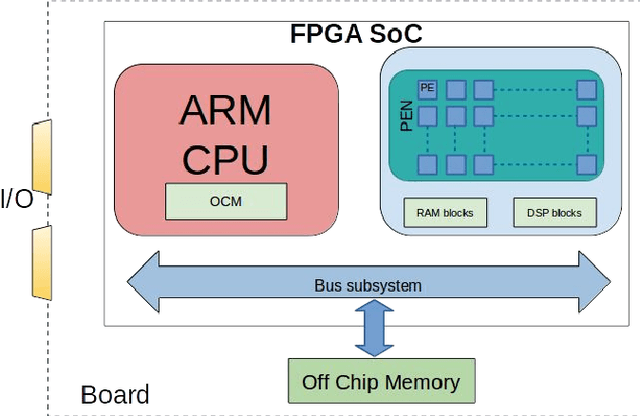
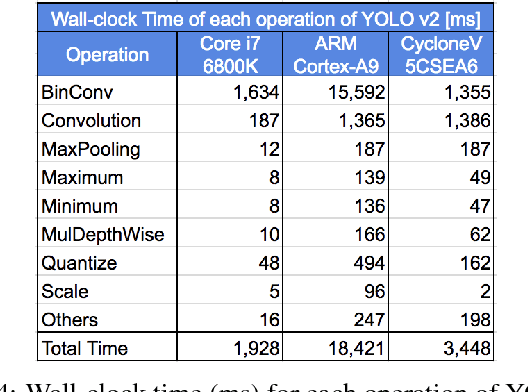
Deep convolutional neural networks (CNN) based solutions are the current state- of-the-art for computer vision tasks. Due to the large size of these models, they are typically run on clusters of CPUs or GPUs. However, power requirements and cost budgets can be a major hindrance in adoption of CNN for IoT applications. Recent research highlights that CNN contain significant redundancy in their structure and can be quantized to lower bit-width parameters and activations, while maintaining acceptable accuracy. Low bit-width and especially single bit-width (binary) CNN are particularly suitable for mobile applications based on FPGA implementation, due to the bitwise logic operations involved in binarized CNN. Moreover, the transition to lower bit-widths opens new avenues for performance optimizations and model improvement. In this paper, we present an automatic flow from trained TensorFlow models to FPGA system on chip implementation of binarized CNN. This flow involves quantization of model parameters and activations, generation of network and model in embedded-C, followed by automatic generation of the FPGA accelerator for binary convolutions. The automated flow is demonstrated through implementation of binarized "YOLOV2" on the low cost, low power Cyclone- V FPGA device. Experiments on object detection using binarized YOLOV2 demonstrate significant performance benefit in terms of model size and inference speed on FPGA as compared to CPU and mobile CPU platforms. Furthermore, the entire automated flow from trained models to FPGA synthesis can be completed within one hour.
Dynamic Boltzmann Machines for Second Order Moments and Generalized Gaussian Distributions
Dec 17, 2017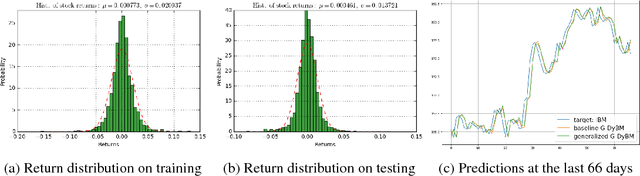
Dynamic Boltzmann Machine (DyBM) has been shown highly efficient to predict time-series data. Gaussian DyBM is a DyBM that assumes the predicted data is generated by a Gaussian distribution whose first-order moment (mean) dynamically changes over time but its second-order moment (variance) is fixed. However, in many financial applications, the assumption is quite limiting in two aspects. First, even when the data follows a Gaussian distribution, its variance may change over time. Such variance is also related to important temporal economic indicators such as the market volatility. Second, financial time-series data often requires learning datasets generated by the generalized Gaussian distribution with an additional shape parameter that is important to approximate heavy-tailed distributions. Addressing those aspects, we show how to extend DyBM that results in significant performance improvement in predicting financial time-series data.
Transfer learning from synthetic to real images using variational autoencoders for robotic applications
Sep 20, 2017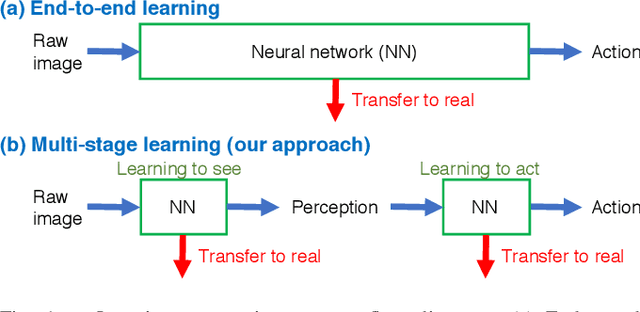
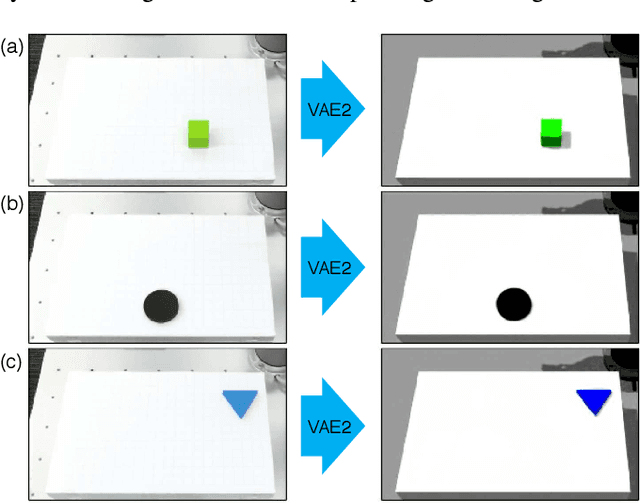

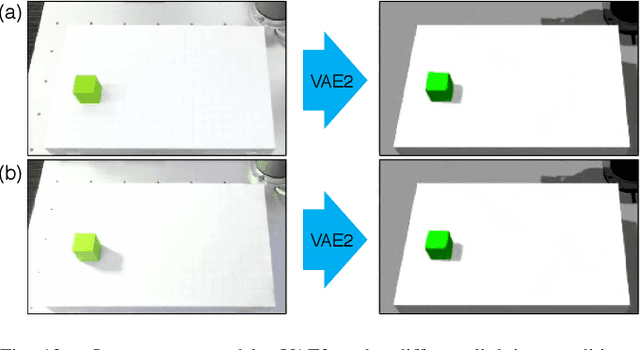
Robotic learning in simulation environments provides a faster, more scalable, and safer training methodology than learning directly with physical robots. Also, synthesizing images in a simulation environment for collecting large-scale image data is easy, whereas capturing camera images in the real world is time consuming and expensive. However, learning from only synthetic images may not achieve the desired performance in real environments due to the gap between synthetic and real images. We thus propose a method that transfers learned capability of detecting object position from a simulation environment to the real world. Our method enables us to use only a very limited dataset of real images while leveraging a large dataset of synthetic images using multiple variational autoencoders. It detects object positions 6 to 7 times more precisely than the baseline of directly learning from the dataset of the real images. Object position estimation under varying environmental conditions forms one of the underlying requirement for standard robotic manipulation tasks. We show that the proposed method performs robustly in different lighting conditions or with other distractor objects present for this requirement. Using this detected object position, we transfer pick-and-place or reaching tasks learned in a simulation environment to an actual physical robot without re-training.