 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexPath: A domain-oriented multi-path framework for legal article retrieval
May 28, 2026Legal article retrieval is critical for building traceable and reliable legal AI systems, where conclusions must be grounded in specific legal articles. However, existing open-domain retrieval methods rely heavily on surface-level lexical or semantic similarity, making it difficult for them to distinguish legally relevant articles from those that are textually similar but legally inapplicable or misaligned with the user's underlying intent. To bridge this gap, we propose \textsc{LexPath}, a domain-oriented multi-path framework comprising a multi-path retrieval module and an intent-aware reranking module. The retrieval module combines two complementary legal-specific paths to collect candidate articles: an IRAC-guided sparse path that expands queries with legally informative keywords, and a structure-guided dense path trained with hard negatives derived from legal hierarchy and citation relations. Then, the reranking module further refines the candidate ranking by incorporating the intent consistency score between queries and legal articles. We evaluate \textsc{LexPath} on two publicly available benchmarks focusing on general-public queries and a self-constructed benchmark targeting domain-professional scenarios. Experimental results demonstrate that \textsc{LexPath} consistently outperforms lexical, dense, hybrid, and adaptive retrieval-augmented generation (RAG) baselines. Ablation studies further verify the effectiveness of each component.
BSC: Block-based Stochastic Computing to Enable Accurate and Efficient TinyML
Nov 12, 2021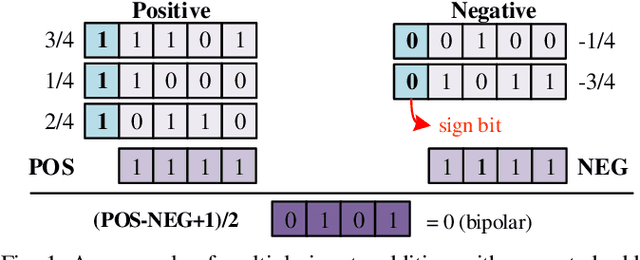
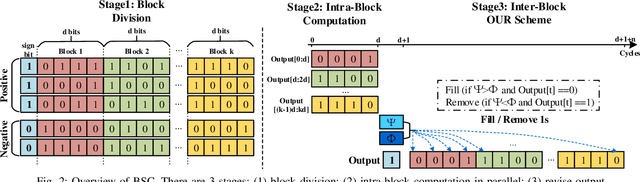
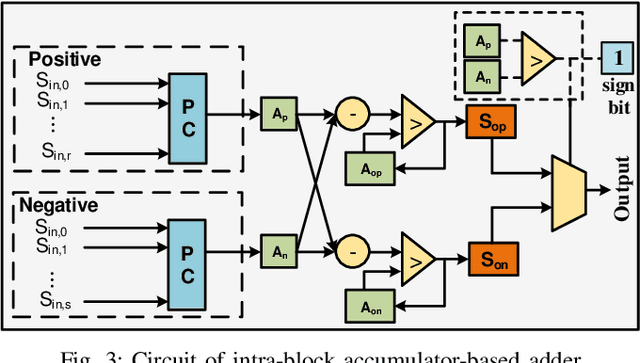
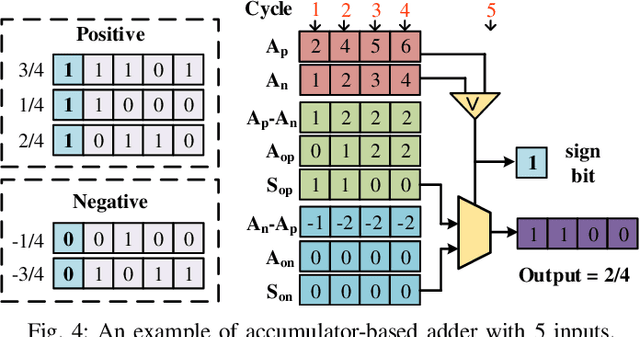
Along with the progress of AI democratization, machine learning (ML) has been successfully applied to edge applications, such as smart phones and automated driving. Nowadays, more applications require ML on tiny devices with extremely limited resources, like implantable cardioverter defibrillator (ICD), which is known as TinyML. Unlike ML on the edge, TinyML with a limited energy supply has higher demands on low-power execution. Stochastic computing (SC) using bitstreams for data representation is promising for TinyML since it can perform the fundamental ML operations using simple logical gates, instead of the complicated binary adder and multiplier. However, SC commonly suffers from low accuracy for ML tasks due to low data precision and inaccuracy of arithmetic units. Increasing the length of the bitstream in the existing works can mitigate the precision issue but incur higher latency. In this work, we propose a novel SC architecture, namely Block-based Stochastic Computing (BSC). BSC divides inputs into blocks, such that the latency can be reduced by exploiting high data parallelism. Moreover, optimized arithmetic units and output revision (OUR) scheme are proposed to improve accuracy. On top of it, a global optimization approach is devised to determine the number of blocks, which can make a better latency-power trade-off. Experimental results show that BSC can outperform the existing designs in achieving over 10% higher accuracy on ML tasks and over 6 times power reduction.
Accelerating Framework of Transformer by Hardware Design and Model Compression Co-Optimization
Oct 19, 2021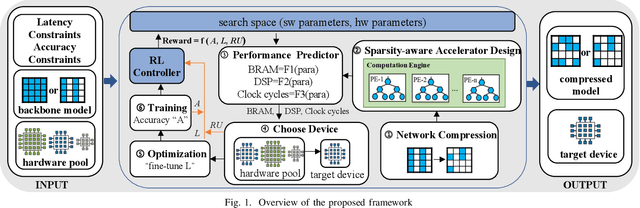
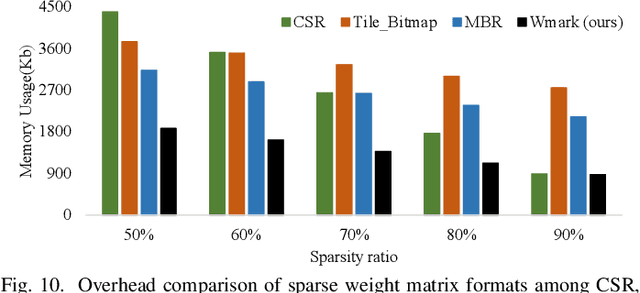
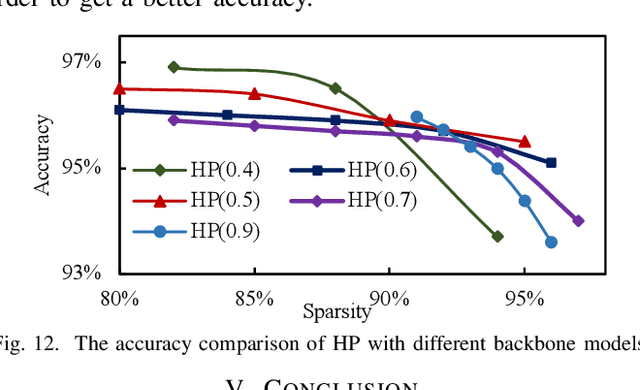
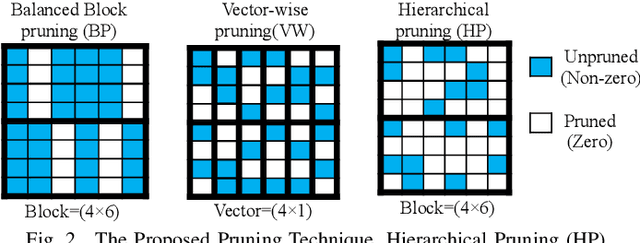
State-of-the-art Transformer-based models, with gigantic parameters, are difficult to be accommodated on resource constrained embedded devices. Moreover, with the development of technology, more and more embedded devices are available to run a Transformer model. For a Transformer model with different constraints (tight or loose), it can be deployed onto devices with different computing power. However, in previous work, designers did not choose the best device among multiple devices. Instead, they just used an existing device to deploy model, which was not necessarily the best fit and may lead to underutilization of resources. To address the deployment challenge of Transformer and the problem to select the best device, we propose an algorithm & hardware closed-loop acceleration framework. Given a dataset, a model, latency constraint LC and accuracy constraint AC, our framework can provide a best device satisfying both constraints. In order to generate a compressed model with high sparsity ratio, we propose a novel pruning technique, hierarchical pruning (HP). We optimize the sparse matrix storage format for HP matrix to further reduce memory usage for FPGA implementation. We design a accelerator that takes advantage of HP to solve the problem of concurrent random access. Experiments on Transformer and TinyBert model show that our framework can find different devices for various LC and AC, covering from low-end devices to high-end devices. Our HP can achieve higher sparsity ratio and is more flexible than other sparsity pattern. Our framework can achieve 37x, 1.9x, 1.7x speedup compared to CPU, GPU and FPGA, respectively.
Dancing along Battery: Enabling Transformer with Run-time Reconfigurability on Mobile Devices
Feb 12, 2021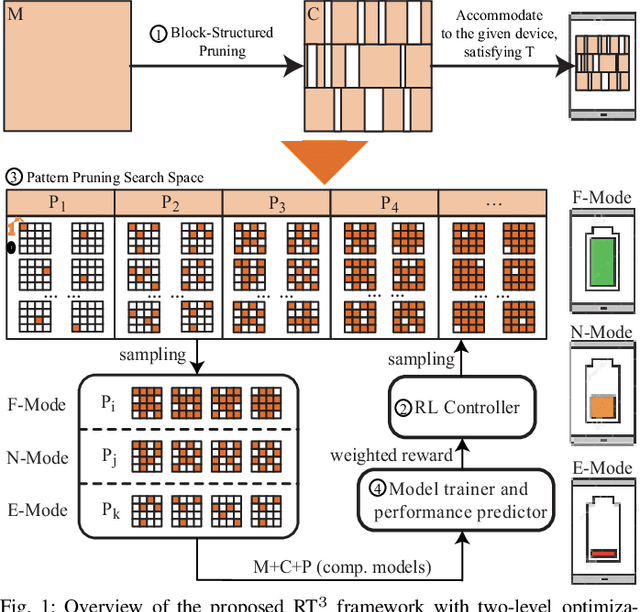
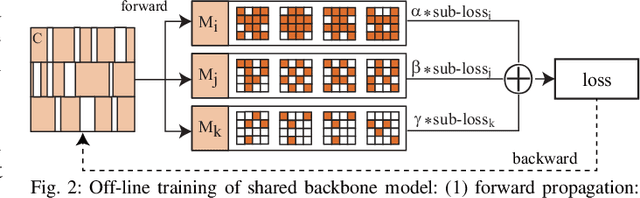
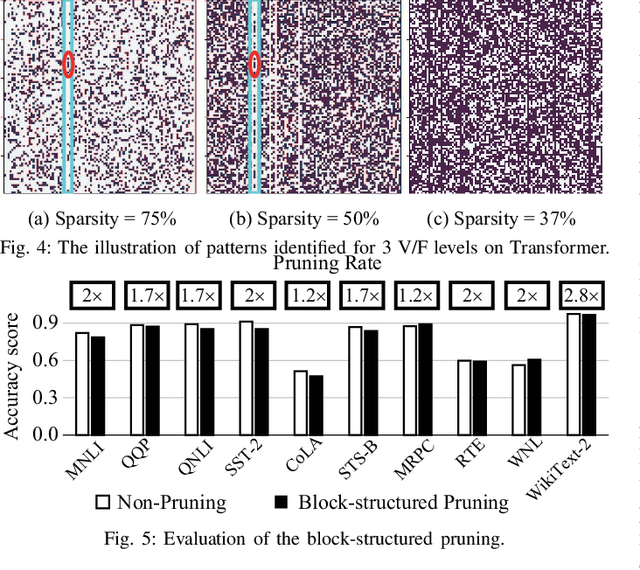

A pruning-based AutoML framework for run-time reconfigurability, namely RT3, is proposed in this work. This enables Transformer-based large Natural Language Processing (NLP) models to be efficiently executed on resource-constrained mobile devices and reconfigured (i.e., switching models for dynamic hardware conditions) at run-time. Such reconfigurability is the key to save energy for battery-powered mobile devices, which widely use dynamic voltage and frequency scaling (DVFS) technique for hardware reconfiguration to prolong battery life. In this work, we creatively explore a hybrid block-structured pruning (BP) and pattern pruning (PP) for Transformer-based models and first attempt to combine hardware and software reconfiguration to maximally save energy for battery-powered mobile devices. Specifically, RT3 integrates two-level optimizations: First, it utilizes an efficient BP as the first-step compression for resource-constrained mobile devices; then, RT3 heuristically generates a shrunken search space based on the first level optimization and searches multiple pattern sets with diverse sparsity for PP via reinforcement learning to support lightweight software reconfiguration, which corresponds to available frequency levels of DVFS (i.e., hardware reconfiguration). At run-time, RT3 can switch the lightweight pattern sets within 45ms to guarantee the required real-time constraint at different frequency levels. Results further show that RT3 can prolong battery life over 4x improvement with less than 1% accuracy loss for Transformer and 1.5% score decrease for DistilBERT.
Hardware/Software Co-Exploration of Neural Architectures
Jul 06, 2019

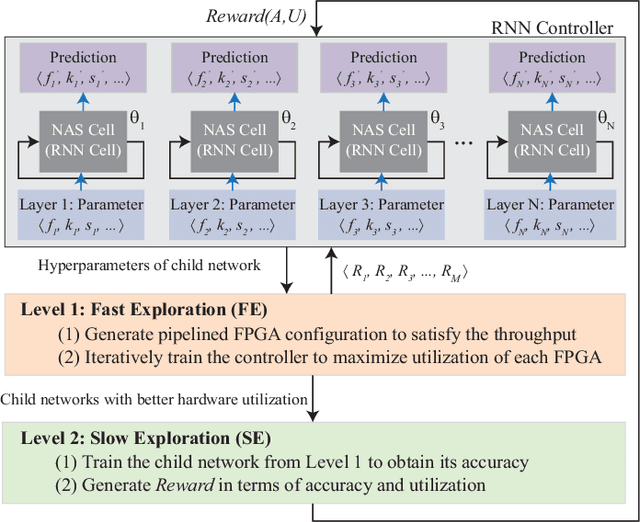
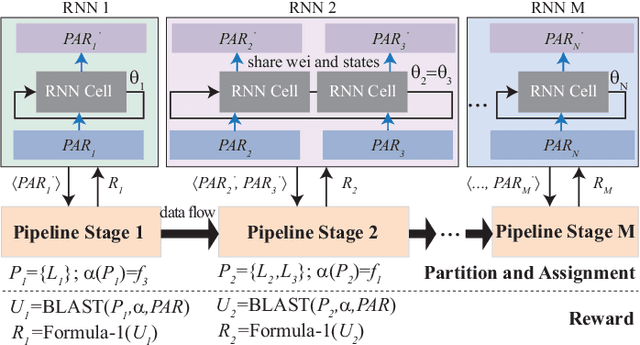
We propose a novel hardware and software co-exploration framework for efficient neural architecture search (NAS). Different from existing hardware-aware NAS which assumes a fixed hardware design and explores the neural architecture search space only, our framework simultaneously explores both the architecture search space and the hardware design space to identify the best neural architecture and hardware pairs that maximize both test accuracy and hardware efficiency. Such a practice greatly opens up the design freedom and pushes forward the Pareto frontier between hardware efficiency and test accuracy for better design tradeoffs. The framework iteratively performs a two-level (fast and slow) exploration. Without lengthy training, the fast exploration can effectively fine-tune hyperparameters and prune inferior architectures in terms of hardware specifications, which significantly accelerates the NAS process. Then, the slow exploration trains candidates on a validation set and updates a controller using the reinforcement learning to maximize the expected accuracy together with the hardware efficiency. Experiments on ImageNet show that our co-exploration NAS can find the neural architectures and associated hardware design with the same accuracy, 35.24% higher throughput, 54.05% higher energy efficiency and 136x reduced search time, compared with the state-of-the-art hardware-aware NAS.
Accuracy vs. Efficiency: Achieving Both through FPGA-Implementation Aware Neural Architecture Search
Jan 31, 2019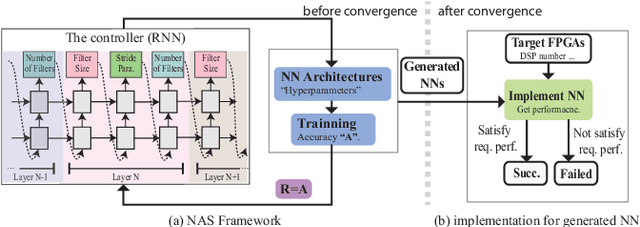


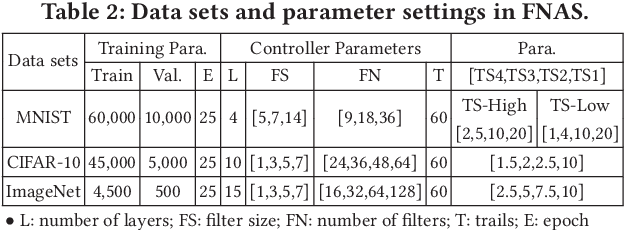
A fundamental question lies in almost every application of deep neural networks: what is the optimal neural architecture given a specific dataset? Recently, several Neural Architecture Search (NAS) frameworks have been developed that use reinforcement learning and evolutionary algorithm to search for the solution. However, most of them take a long time to find the optimal architecture due to the huge search space and the lengthy training process needed to evaluate each candidate. In addition, most of them aim at accuracy only and do not take into consideration the hardware that will be used to implement the architecture. This will potentially lead to excessive latencies beyond specifications, rendering the resulting architectures useless. To address both issues, in this paper we use Field Programmable Gate Arrays (FPGAs) as a vehicle to present a novel hardware-aware NAS framework, namely FNAS, which will provide an optimal neural architecture with latency guaranteed to meet the specification. In addition, with a performance abstraction model to analyze the latency of neural architectures without training, our framework can quickly prune architectures that do not satisfy the specification, leading to higher efficiency. Experimental results on common data set such as ImageNet show that in the cases where the state-of-the-art generates architectures with latencies 7.81x longer than the specification, those from FNAS can meet the specs with less than 1% accuracy loss. Moreover, FNAS also achieves up to 11.13x speedup for the search process. To the best of the authors' knowledge, this is the very first hardware aware NAS.