 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Performance Bounds Prediction in Quantum Computing with Unstable Noise
Jul 22, 2025Quantum computing has significantly advanced in recent years, boasting devices with hundreds of quantum bits (qubits), hinting at its potential quantum advantage over classical computing. Yet, noise in quantum devices poses significant barriers to realizing this supremacy. Understanding noise's impact is crucial for reproducibility and application reuse; moreover, the next-generation quantum-centric supercomputing essentially requires efficient and accurate noise characterization to support system management (e.g., job scheduling), where ensuring correct functional performance (i.e., fidelity) of jobs on available quantum devices can even be higher-priority than traditional objectives. However, noise fluctuates over time, even on the same quantum device, which makes predicting the computational bounds for on-the-fly noise is vital. Noisy quantum simulation can offer insights but faces efficiency and scalability issues. In this work, we propose a data-driven workflow, namely QuBound, to predict computational performance bounds. It decomposes historical performance traces to isolate noise sources and devises a novel encoder to embed circuit and noise information processed by a Long Short-Term Memory (LSTM) network. For evaluation, we compare QuBound with a state-of-the-art learning-based predictor, which only generates a single performance value instead of a bound. Experimental results show that the result of the existing approach falls outside of performance bounds, while all predictions from our QuBound with the assistance of performance decomposition better fit the bounds. Moreover, QuBound can efficiently produce practical bounds for various circuits with over 106 speedup over simulation; in addition, the range from QuBound is over 10x narrower than the state-of-the-art analytical approach.
BSC: Block-based Stochastic Computing to Enable Accurate and Efficient TinyML
Nov 12, 2021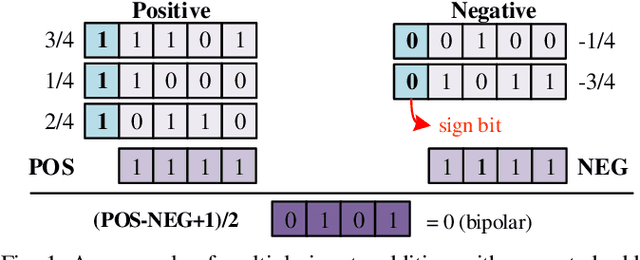
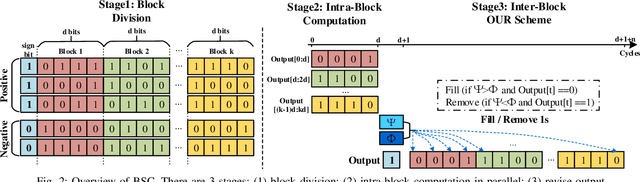
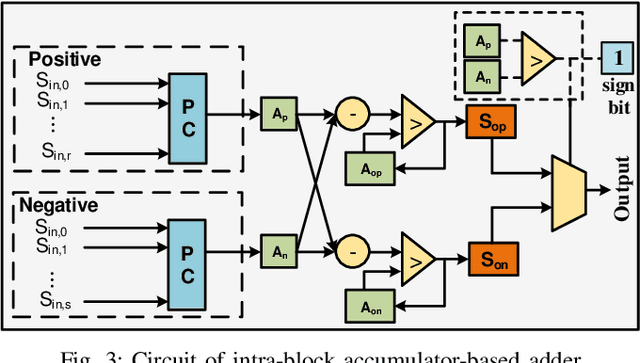
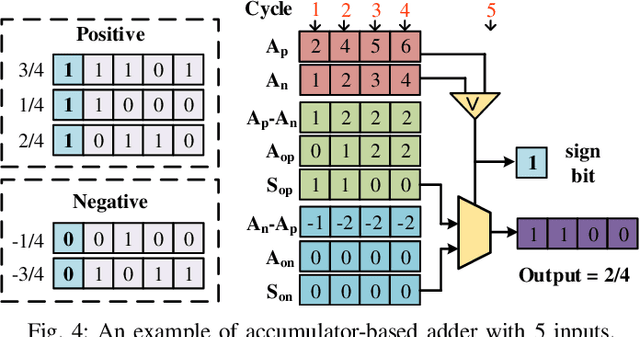
Along with the progress of AI democratization, machine learning (ML) has been successfully applied to edge applications, such as smart phones and automated driving. Nowadays, more applications require ML on tiny devices with extremely limited resources, like implantable cardioverter defibrillator (ICD), which is known as TinyML. Unlike ML on the edge, TinyML with a limited energy supply has higher demands on low-power execution. Stochastic computing (SC) using bitstreams for data representation is promising for TinyML since it can perform the fundamental ML operations using simple logical gates, instead of the complicated binary adder and multiplier. However, SC commonly suffers from low accuracy for ML tasks due to low data precision and inaccuracy of arithmetic units. Increasing the length of the bitstream in the existing works can mitigate the precision issue but incur higher latency. In this work, we propose a novel SC architecture, namely Block-based Stochastic Computing (BSC). BSC divides inputs into blocks, such that the latency can be reduced by exploiting high data parallelism. Moreover, optimized arithmetic units and output revision (OUR) scheme are proposed to improve accuracy. On top of it, a global optimization approach is devised to determine the number of blocks, which can make a better latency-power trade-off. Experimental results show that BSC can outperform the existing designs in achieving over 10% higher accuracy on ML tasks and over 6 times power reduction.
Accelerating Framework of Transformer by Hardware Design and Model Compression Co-Optimization
Oct 19, 2021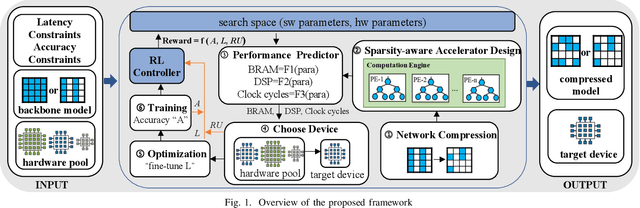
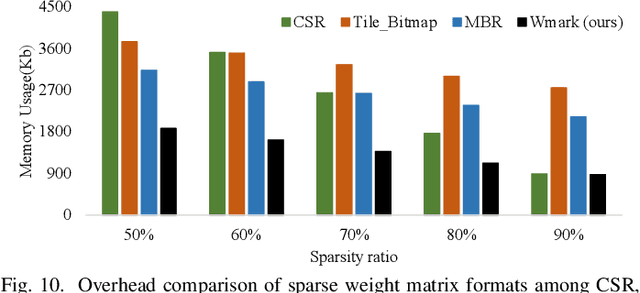
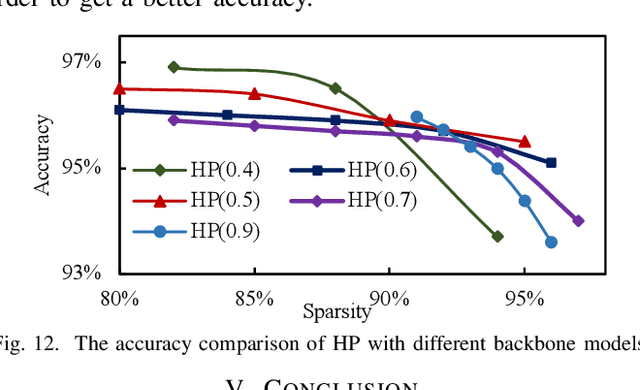
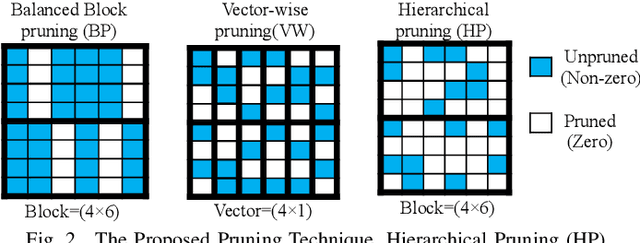
State-of-the-art Transformer-based models, with gigantic parameters, are difficult to be accommodated on resource constrained embedded devices. Moreover, with the development of technology, more and more embedded devices are available to run a Transformer model. For a Transformer model with different constraints (tight or loose), it can be deployed onto devices with different computing power. However, in previous work, designers did not choose the best device among multiple devices. Instead, they just used an existing device to deploy model, which was not necessarily the best fit and may lead to underutilization of resources. To address the deployment challenge of Transformer and the problem to select the best device, we propose an algorithm & hardware closed-loop acceleration framework. Given a dataset, a model, latency constraint LC and accuracy constraint AC, our framework can provide a best device satisfying both constraints. In order to generate a compressed model with high sparsity ratio, we propose a novel pruning technique, hierarchical pruning (HP). We optimize the sparse matrix storage format for HP matrix to further reduce memory usage for FPGA implementation. We design a accelerator that takes advantage of HP to solve the problem of concurrent random access. Experiments on Transformer and TinyBert model show that our framework can find different devices for various LC and AC, covering from low-end devices to high-end devices. Our HP can achieve higher sparsity ratio and is more flexible than other sparsity pattern. Our framework can achieve 37x, 1.9x, 1.7x speedup compared to CPU, GPU and FPGA, respectively.
Dancing along Battery: Enabling Transformer with Run-time Reconfigurability on Mobile Devices
Feb 12, 2021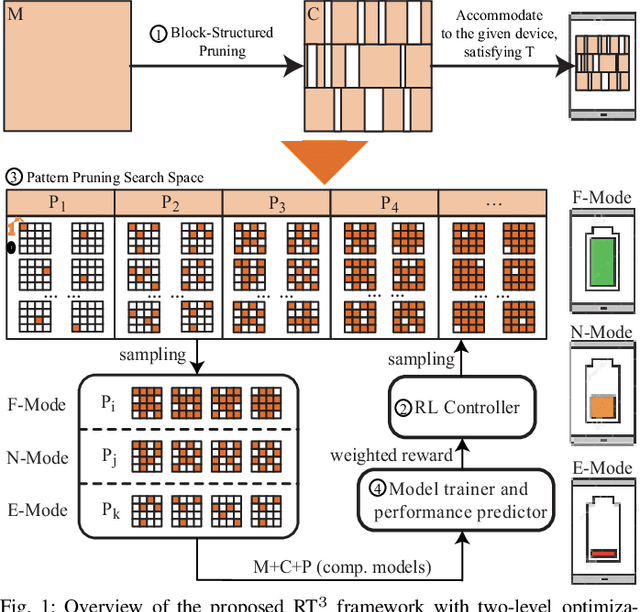
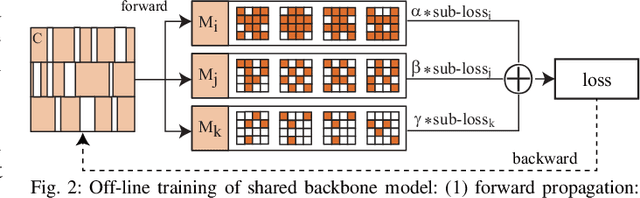
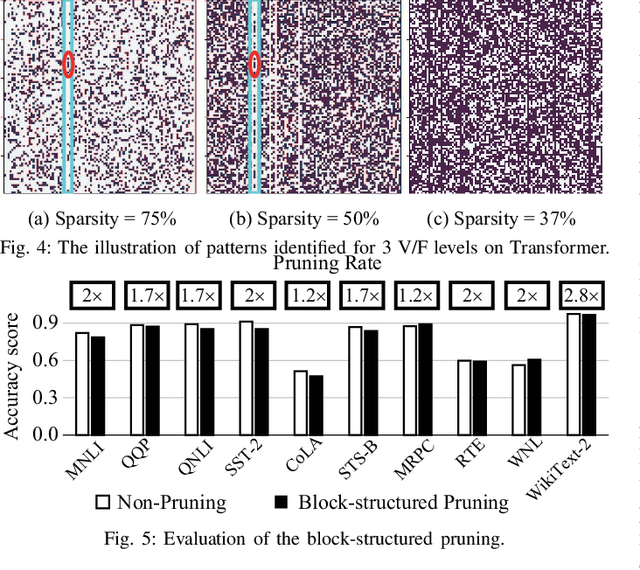

A pruning-based AutoML framework for run-time reconfigurability, namely RT3, is proposed in this work. This enables Transformer-based large Natural Language Processing (NLP) models to be efficiently executed on resource-constrained mobile devices and reconfigured (i.e., switching models for dynamic hardware conditions) at run-time. Such reconfigurability is the key to save energy for battery-powered mobile devices, which widely use dynamic voltage and frequency scaling (DVFS) technique for hardware reconfiguration to prolong battery life. In this work, we creatively explore a hybrid block-structured pruning (BP) and pattern pruning (PP) for Transformer-based models and first attempt to combine hardware and software reconfiguration to maximally save energy for battery-powered mobile devices. Specifically, RT3 integrates two-level optimizations: First, it utilizes an efficient BP as the first-step compression for resource-constrained mobile devices; then, RT3 heuristically generates a shrunken search space based on the first level optimization and searches multiple pattern sets with diverse sparsity for PP via reinforcement learning to support lightweight software reconfiguration, which corresponds to available frequency levels of DVFS (i.e., hardware reconfiguration). At run-time, RT3 can switch the lightweight pattern sets within 45ms to guarantee the required real-time constraint at different frequency levels. Results further show that RT3 can prolong battery life over 4x improvement with less than 1% accuracy loss for Transformer and 1.5% score decrease for DistilBERT.