 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Framework of Transformer by Hardware Design and Model Compression Co-Optimization
Paper and Code
Oct 19, 2021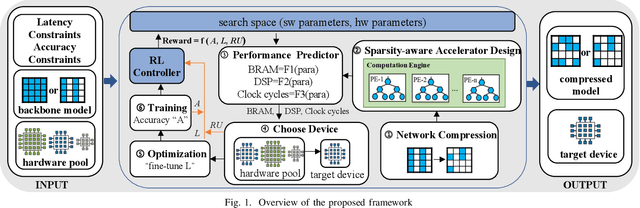
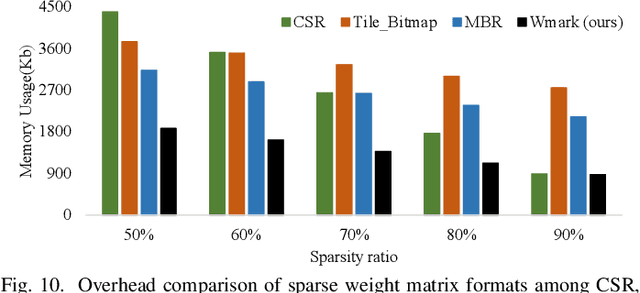
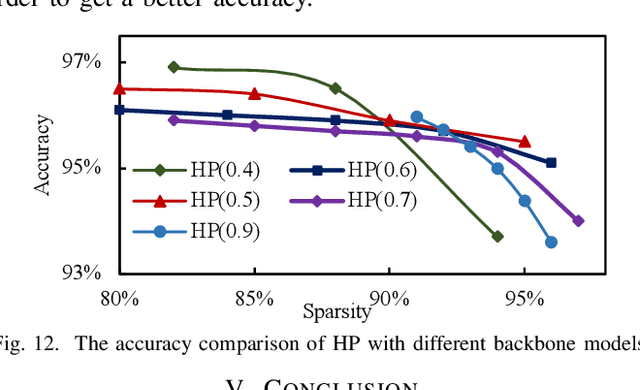
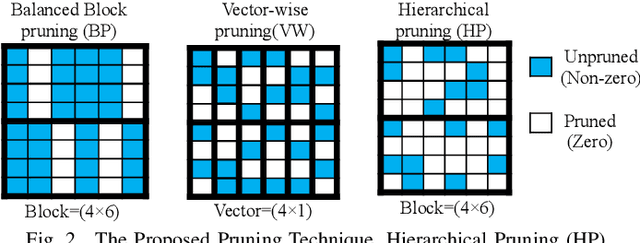
State-of-the-art Transformer-based models, with gigantic parameters, are difficult to be accommodated on resource constrained embedded devices. Moreover, with the development of technology, more and more embedded devices are available to run a Transformer model. For a Transformer model with different constraints (tight or loose), it can be deployed onto devices with different computing power. However, in previous work, designers did not choose the best device among multiple devices. Instead, they just used an existing device to deploy model, which was not necessarily the best fit and may lead to underutilization of resources. To address the deployment challenge of Transformer and the problem to select the best device, we propose an algorithm & hardware closed-loop acceleration framework. Given a dataset, a model, latency constraint LC and accuracy constraint AC, our framework can provide a best device satisfying both constraints. In order to generate a compressed model with high sparsity ratio, we propose a novel pruning technique, hierarchical pruning (HP). We optimize the sparse matrix storage format for HP matrix to further reduce memory usage for FPGA implementation. We design a accelerator that takes advantage of HP to solve the problem of concurrent random access. Experiments on Transformer and TinyBert model show that our framework can find different devices for various LC and AC, covering from low-end devices to high-end devices. Our HP can achieve higher sparsity ratio and is more flexible than other sparsity pattern. Our framework can achieve 37x, 1.9x, 1.7x speedup compared to CPU, GPU and FPGA, respectively.