 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTypoSwype: An Imaging Approach to Detect Typo-Squatting
Sep 02, 2022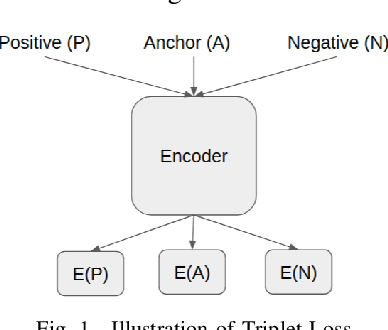
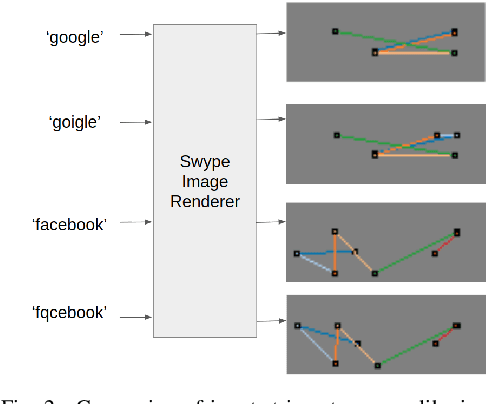
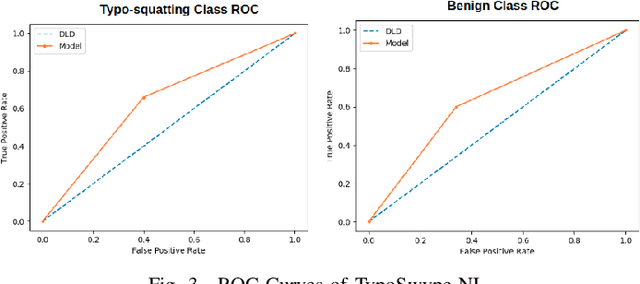

Typo-squatting domains are a common cyber-attack technique. It involves utilising domain names, that exploit possible typographical errors of commonly visited domains, to carry out malicious activities such as phishing, malware installation, etc. Current approaches typically revolve around string comparison algorithms like the Demaru-Levenschtein Distance (DLD) algorithm. Such techniques do not take into account keyboard distance, which researchers find to have a strong correlation with typical typographical errors and are trying to take account of. In this paper, we present the TypoSwype framework which converts strings to images that take into account keyboard location innately. We also show how modern state of the art image recognition techniques involving Convolutional Neural Networks, trained via either Triplet Loss or NT-Xent Loss, can be applied to learn a mapping to a lower dimensional space where distances correspond to image, and equivalently, textual similarity. Finally, we also demonstrate our method's ability to improve typo-squatting detection over the widely used DLD algorithm, while maintaining the classification accuracy as to which domain the input domain was attempting to typo-squat.
BinImg2Vec: Augmenting Malware Binary Image Classification with Data2Vec
Sep 02, 2022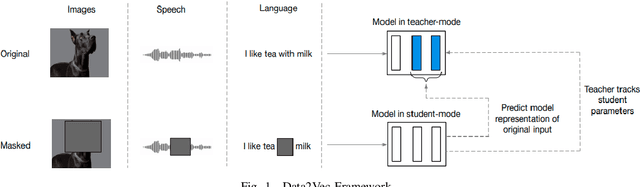

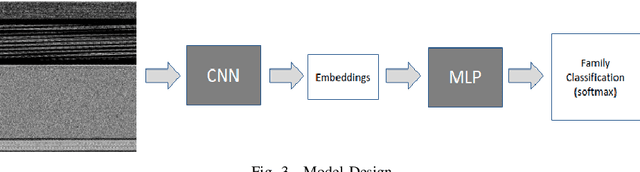
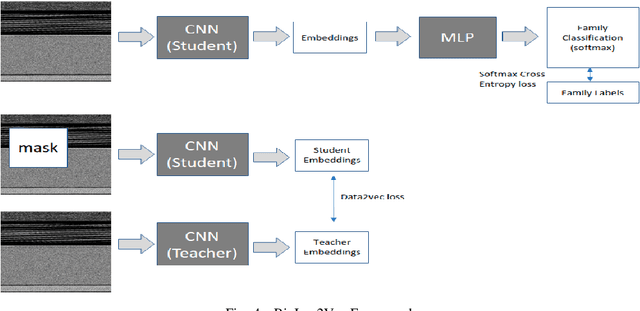
Rapid digitalisation spurred by the Covid-19 pandemic has resulted in more cyber crime. Malware-as-a-service is now a booming business for cyber criminals. With the surge in malware activities, it is vital for cyber defenders to understand more about the malware samples they have at hand as such information can greatly influence their next course of actions during a breach. Recently, researchers have shown how malware family classification can be done by first converting malware binaries into grayscale images and then passing them through neural networks for classification. However, most work focus on studying the impact of different neural network architectures on classification performance. In the last year, researchers have shown that augmenting supervised learning with self-supervised learning can improve performance. Even more recently, Data2Vec was proposed as a modality agnostic self-supervised framework to train neural networks. In this paper, we present BinImg2Vec, a framework of training malware binary image classifiers that incorporates both self-supervised learning and supervised learning to produce a model that consistently outperforms one trained only via supervised learning. We were able to achieve a 4% improvement in classification performance and a 0.5% reduction in performance variance over multiple runs. We also show how our framework produces embeddings that can be well clustered, facilitating model explanability.
PhishGAN: Data Augmentation and Identification of Homoglpyh Attacks
Jun 29, 2020

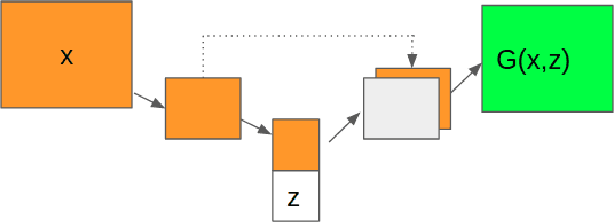
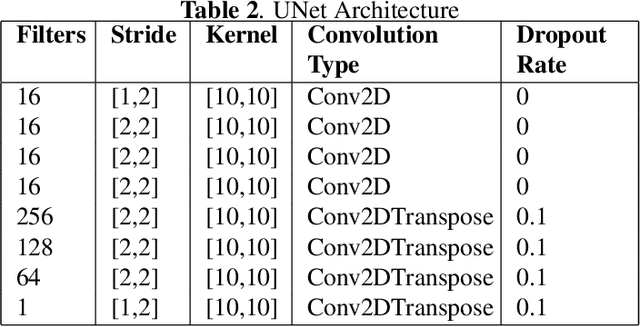
Homoglyph attacks are a common technique used by hackers to conduct phishing. Domain names or links that are visually similar to actual ones are created via punycode to obfuscate the attack, making the victim more susceptible to phishing. For example, victims may mistake "|inkedin.com" for "linkedin.com" and in the process, divulge personal details to the fake website. Current State of The Art (SOTA) typically make use of string comparison algorithms (e.g. Levenshtein Distance), which are computationally heavy. One reason for this is the lack of publicly available datasets thus hindering the training of more advanced Machine Learning (ML) models. Furthermore, no one font is able to render all types of punycode correctly, posing a significant challenge to the creation of a dataset that is unbiased toward any particular font. This coupled with the vast number of internet domains pose a challenge in creating a dataset that can capture all possible variations. Here, we show how a conditional Generative Adversarial Network (GAN), PhishGAN, can be used to generate images of hieroglyphs, conditioned on non-homoglpyh input text images. Practical changes to current SOTA were required to facilitate the generation of more varied homoglyph text-based images. We also demonstrate a workflow of how PhishGAN together with a Homoglyph Identifier (HI) model can be used to identify the domain the homoglyph was trying to imitate. Furthermore, we demonstrate how PhishGAN's ability to generate datasets on the fly facilitate the quick adaptation of cybersecurity systems to detect new threats as they emerge.
Model-based Deep Reinforcement Learning for Dynamic Portfolio Optimization
Jan 25, 2019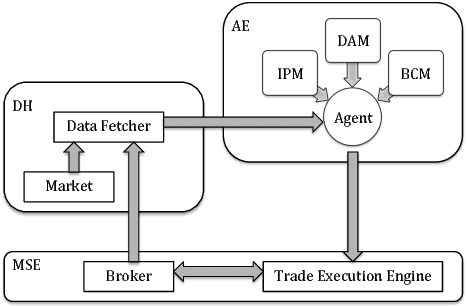
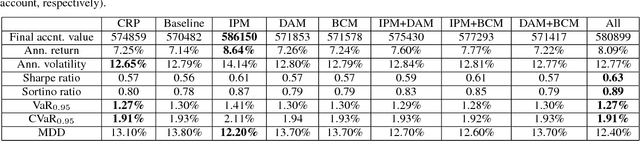
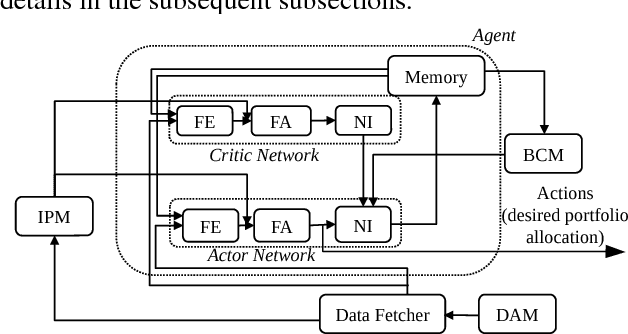
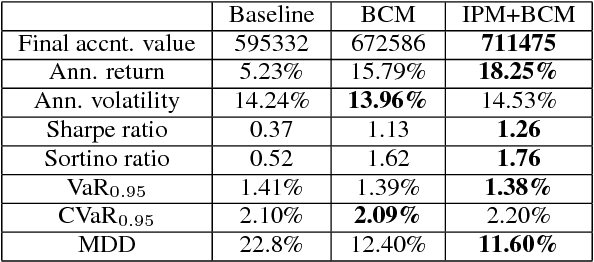
Dynamic portfolio optimization is the process of sequentially allocating wealth to a collection of assets in some consecutive trading periods, based on investors' return-risk profile. Automating this process with machine learning remains a challenging problem. Here, we design a deep reinforcement learning (RL) architecture with an autonomous trading agent such that, investment decisions and actions are made periodically, based on a global objective, with autonomy. In particular, without relying on a purely model-free RL agent, we train our trading agent using a novel RL architecture consisting of an infused prediction module (IPM), a generative adversarial data augmentation module (DAM) and a behavior cloning module (BCM). Our model-based approach works with both on-policy or off-policy RL algorithms. We further design the back-testing and execution engine which interact with the RL agent in real time. Using historical {\em real} financial market data, we simulate trading with practical constraints, and demonstrate that our proposed model is robust, profitable and risk-sensitive, as compared to baseline trading strategies and model-free RL agents from prior work.