 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStanding on the Shoulders of Giants: Hardware and Neural Architecture Co-Search with Hot Start
Paper and Code
Jul 17, 2020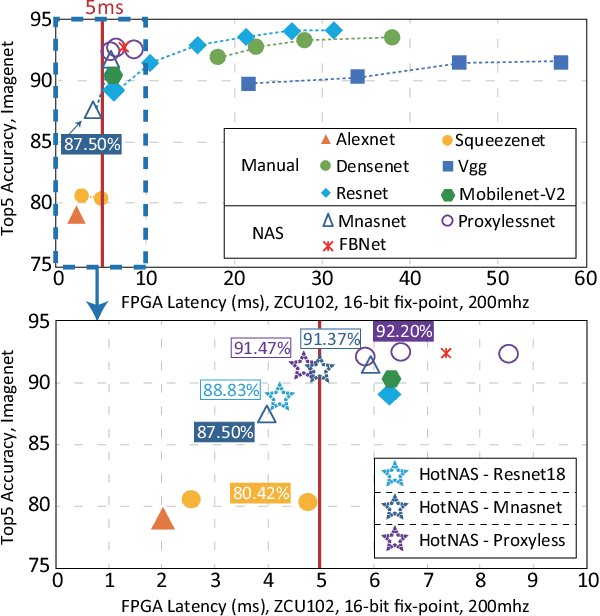
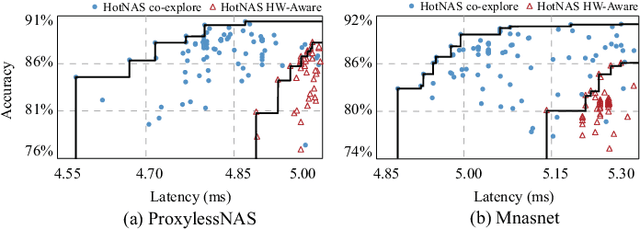
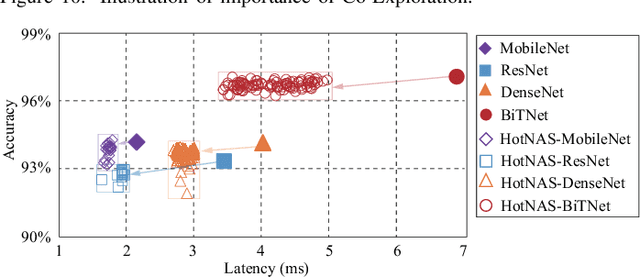
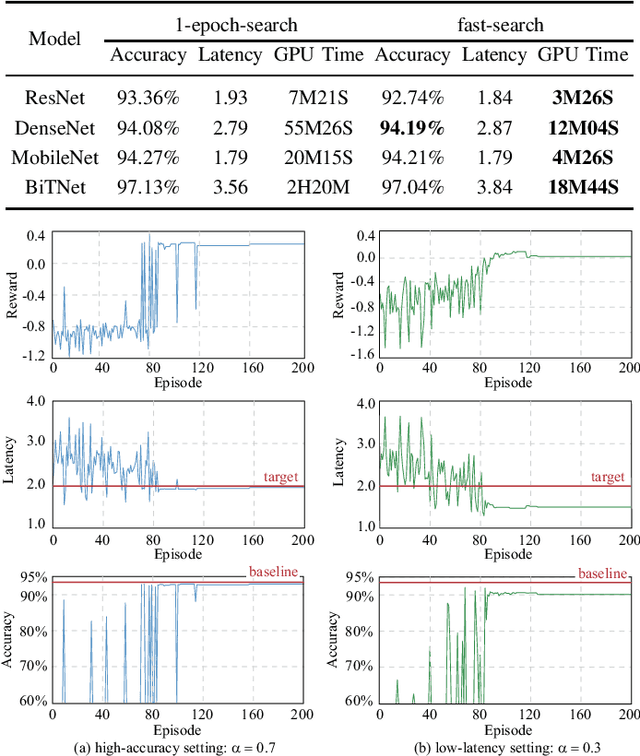
Hardware and neural architecture co-search that automatically generates Artificial Intelligence (AI) solutions from a given dataset is promising to promote AI democratization; however, the amount of time that is required by current co-search frameworks is in the order of hundreds of GPU hours for one target hardware. This inhibits the use of such frameworks on commodity hardware. The root cause of the low efficiency in existing co-search frameworks is the fact that they start from a "cold" state (i.e., search from scratch). In this paper, we propose a novel framework, namely HotNAS, that starts from a "hot" state based on a set of existing pre-trained models (a.k.a. model zoo) to avoid lengthy training time. As such, the search time can be reduced from 200 GPU hours to less than 3 GPU hours. In HotNAS, in addition to hardware design space and neural architecture search space, we further integrate a compression space to conduct model compressing during the co-search, which creates new opportunities to reduce latency but also brings challenges. One of the key challenges is that all of the above search spaces are coupled with each other, e.g., compression may not work without hardware design support. To tackle this issue, HotNAS builds a chain of tools to design hardware to support compression, based on which a global optimizer is developed to automatically co-search all the involved search spaces. Experiments on ImageNet dataset and Xilinx FPGA show that, within the timing constraint of 5ms, neural architectures generated by HotNAS can achieve up to 5.79% Top-1 and 3.97% Top-5 accuracy gain, compared with the existing ones.