 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Framework for Real-world Multiple Sound Source 2D Localization
Dec 10, 2020
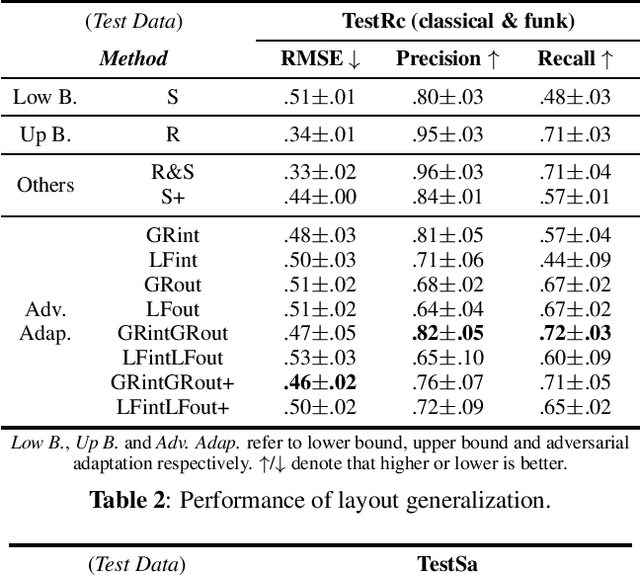
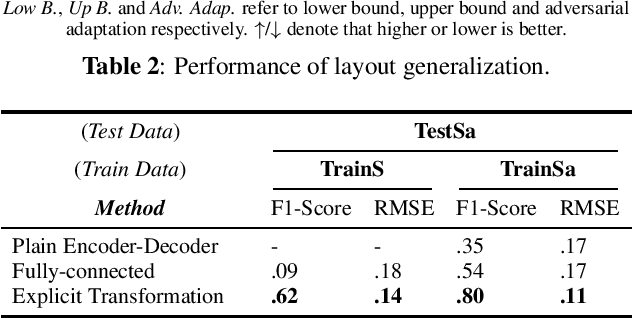
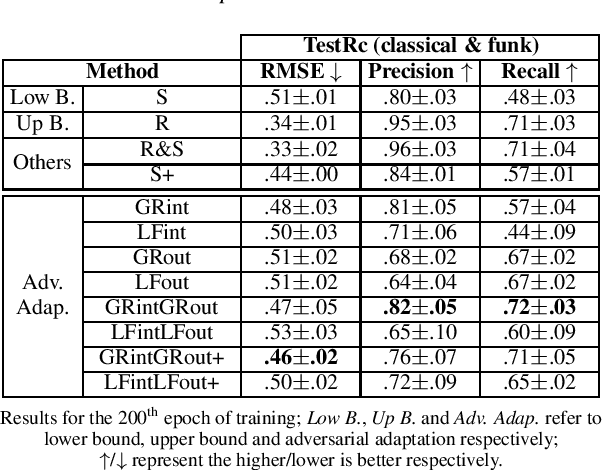
Deep neural networks have recently led to promising results for the task of multiple sound source localization. Yet, they require a lot of training data to cover a variety of acoustic conditions and microphone array layouts. One can leverage acoustic simulators to inexpensively generate labeled training data. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. Moreover, learning for different microphone array layouts makes the task more complicated due to the infinite number of possible layouts. We propose to use adversarial learning methods to close the gap between synthetic and real domains. Our novel ensemble-discrimination method significantly improves the localization performance without requiring any label from the real data. Furthermore, we propose a novel explicit transformation layer to be embedded in the localization architecture. It enables the model to be trained with data from specific microphone array layouts while generalizing well to unseen layouts during inference.
Ensemble of Discriminators for Domain Adaptation in Multiple Sound Source 2D Localization
Dec 10, 2020
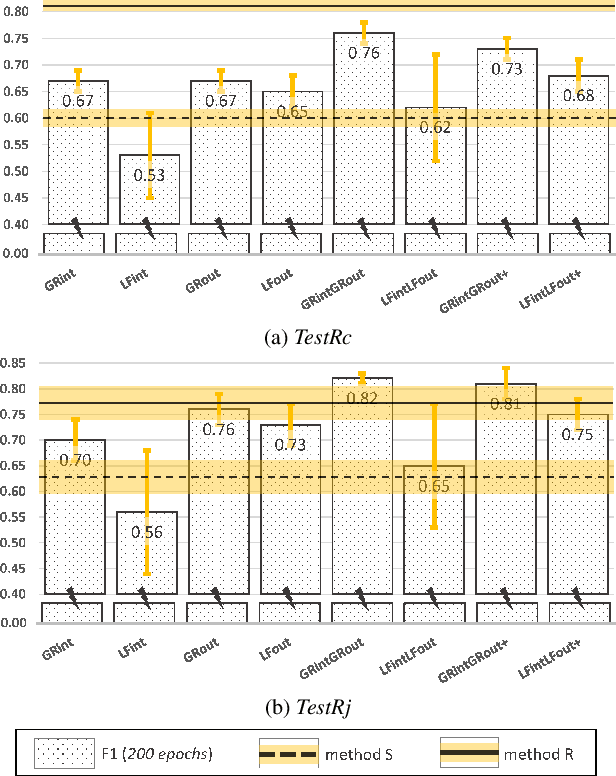
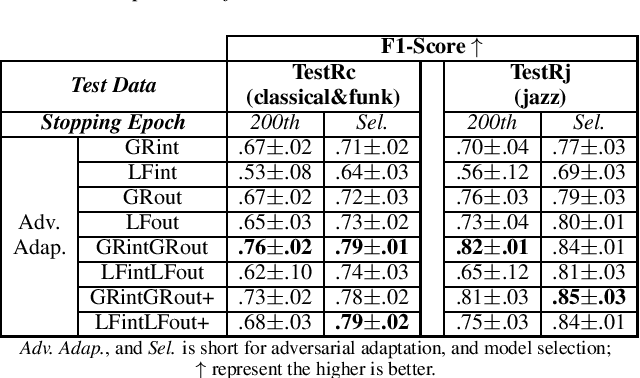
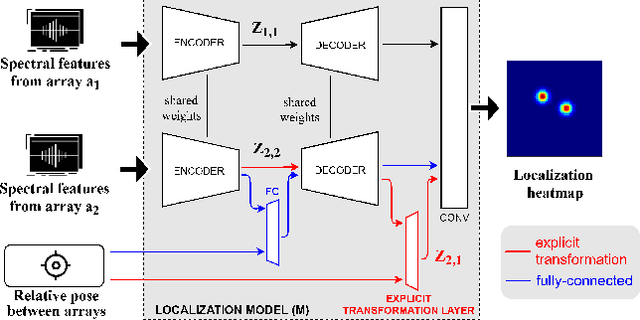
This paper introduces an ensemble of discriminators that improves the accuracy of a domain adaptation technique for the localization of multiple sound sources. Recently, deep neural networks have led to promising results for this task, yet they require a large amount of labeled data for training. Recording and labeling such datasets is very costly, especially because data needs to be diverse enough to cover different acoustic conditions. In this paper, we leverage acoustic simulators to inexpensively generate labeled training samples. However, models trained on synthetic data tend to perform poorly with real-world recordings due to the domain mismatch. For this, we explore two domain adaptation methods using adversarial learning for sound source localization which use labeled synthetic data and unlabeled real data. We propose a novel ensemble approach that combines discriminators applied at different feature levels of the localization model. Experiments show that our ensemble discrimination method significantly improves the localization performance without requiring any label from the real data.
Learning Multiple Sound Source 2D Localization
Dec 10, 2020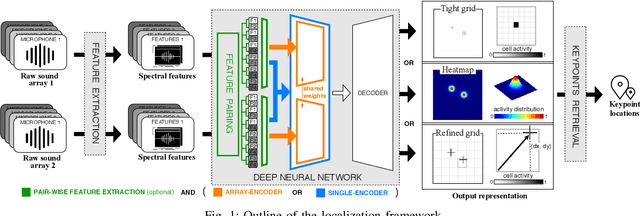
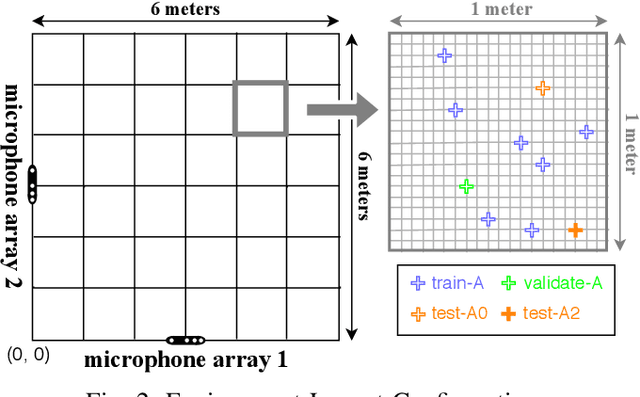
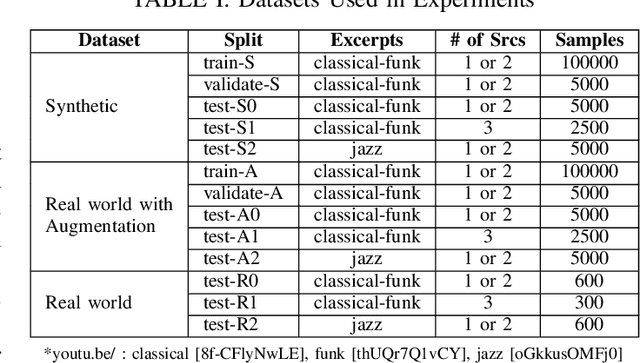
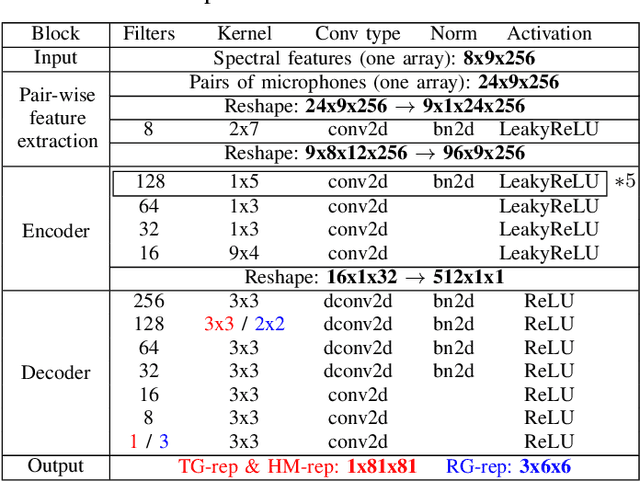
In this paper, we propose novel deep learning based algorithms for multiple sound source localization. Specifically, we aim to find the 2D Cartesian coordinates of multiple sound sources in an enclosed environment by using multiple microphone arrays. To this end, we use an encoding-decoding architecture and propose two improvements on it to accomplish the task. In addition, we also propose two novel localization representations which increase the accuracy. Lastly, new metrics are developed relying on resolution-based multiple source association which enables us to evaluate and compare different localization approaches. We tested our method on both synthetic and real world data. The results show that our method improves upon the previous baseline approach for this problem.
Q-learning with Language Model for Edit-based Unsupervised Summarization
Oct 09, 2020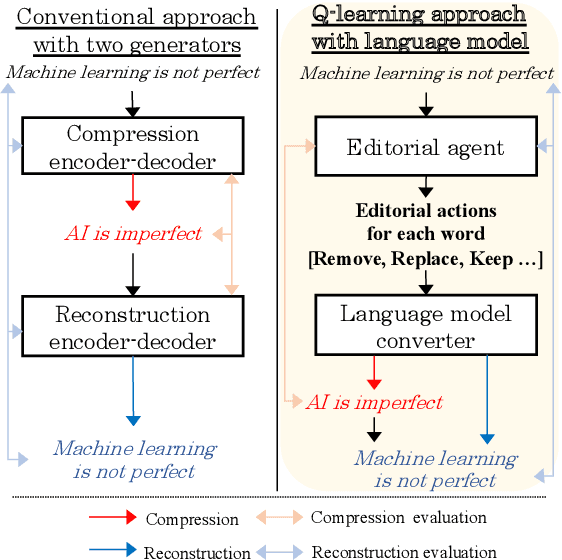
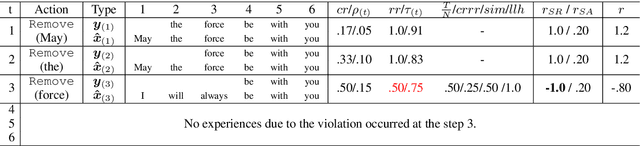
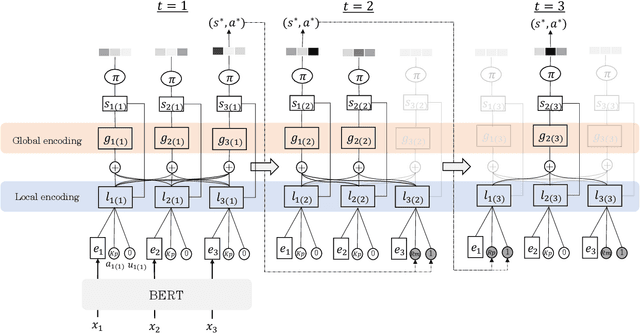
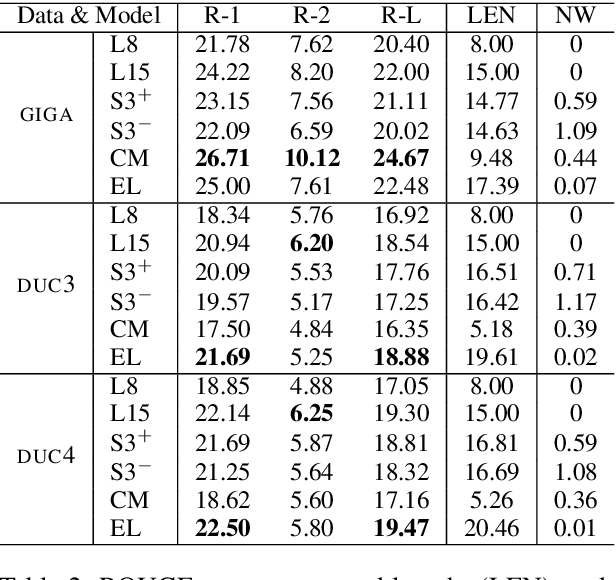
Unsupervised methods are promising for abstractive text summarization in that the parallel corpora is not required. However, their performance is still far from being satisfied, therefore research on promising solutions is on-going. In this paper, we propose a new approach based on Q-learning with an edit-based summarization. The method combines two key modules to form an Editorial Agent and Language Model converter (EALM). The agent predicts edit actions (e.t., delete, keep, and replace), and then the LM converter deterministically generates a summary on the basis of the action signals. Q-learning is leveraged to train the agent to produce proper edit actions. Experimental results show that EALM delivered competitive performance compared with the previous encoder-decoder-based methods, even with truly zero paired data (i.e., no validation set). Defining the task as Q-learning enables us not only to develop a competitive method but also to make the latest techniques in reinforcement learning available for unsupervised summarization. We also conduct qualitative analysis, providing insights into future study on unsupervised summarizers.
Bootstrapped Q-learning with Context Relevant Observation Pruning to Generalize in Text-based Games
Sep 24, 2020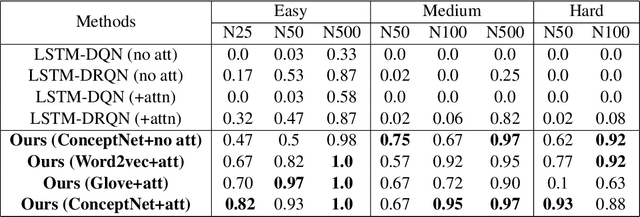
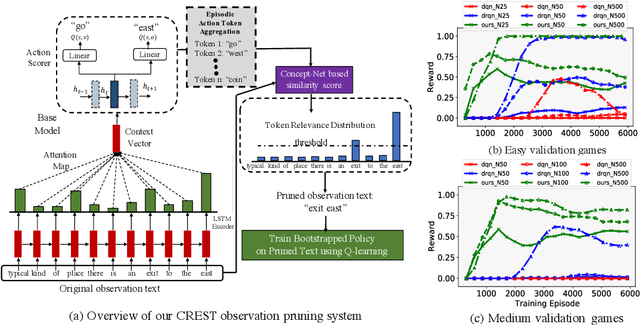
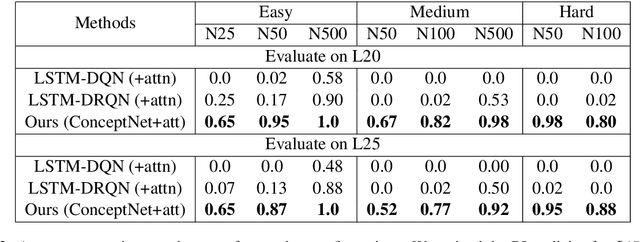
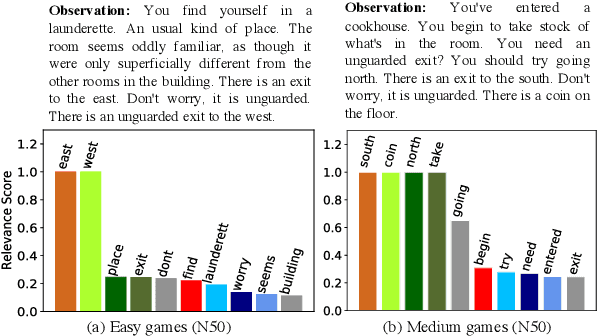
We show that Reinforcement Learning (RL) methods for solving Text-Based Games (TBGs) often fail to generalize on unseen games, especially in small data regimes. To address this issue, we propose Context Relevant Episodic State Truncation (CREST) for irrelevant token removal in observation text for improved generalization. Our method first trains a base model using Q-learning, which typically overfits the training games. The base model's action token distribution is used to perform observation pruning that removes irrelevant tokens. A second bootstrapped model is then retrained on the pruned observation text. Our bootstrapped agent shows improved generalization in solving unseen TextWorld games, using 10x-20x fewer training games compared to previous state-of-the-art methods despite requiring less number of training episodes.
Unsupervised Temporal Feature Aggregation for Event Detection in Unstructured Sports Videos
Feb 19, 2020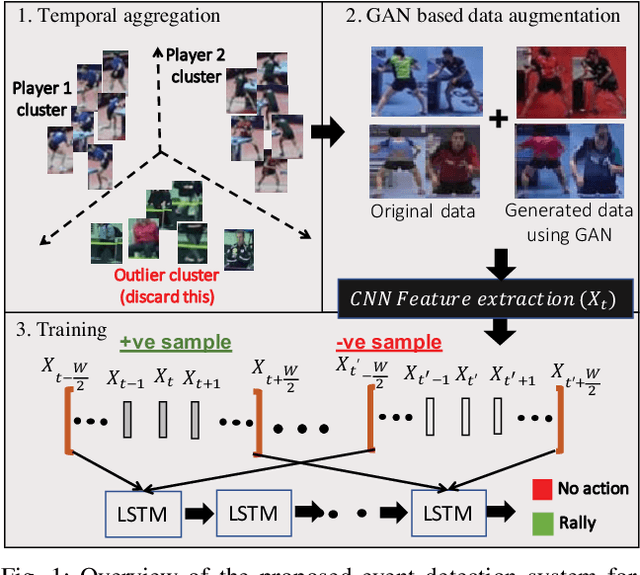



Image-based sports analytics enable automatic retrieval of key events in a game to speed up the analytics process for human experts. However, most existing methods focus on structured television broadcast video datasets with a straight and fixed camera having minimum variability in the capturing pose. In this paper, we study the case of event detection in sports videos for unstructured environments with arbitrary camera angles. The transition from structured to unstructured video analysis produces multiple challenges that we address in our paper. Specifically, we identify and solve two major problems: unsupervised identification of players in an unstructured setting and generalization of the trained models to pose variations due to arbitrary shooting angles. For the first problem, we propose a temporal feature aggregation algorithm using person re-identification features to obtain high player retrieval precision by boosting a weak heuristic scoring method. Additionally, we propose a data augmentation technique, based on multi-modal image translation model, to reduce bias in the appearance of training samples. Experimental evaluations show that our proposed method improves precision for player retrieval from 0.78 to 0.86 for obliquely angled videos. Additionally, we obtain an improvement in F1 score for rally detection in table tennis videos from 0.79 in case of global frame-level features to 0.89 using our proposed player-level features. Please see the supplementary video submission at https://ibm.biz/BdzeZA.
Spatially-weighted Anomaly Detection with Regression Model
Mar 28, 2019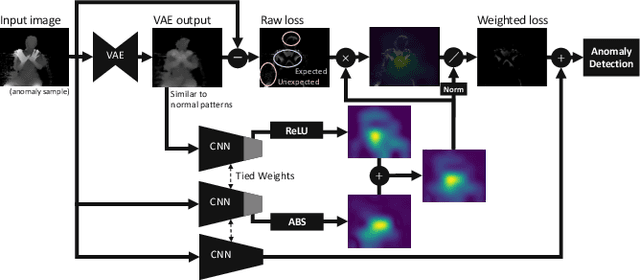
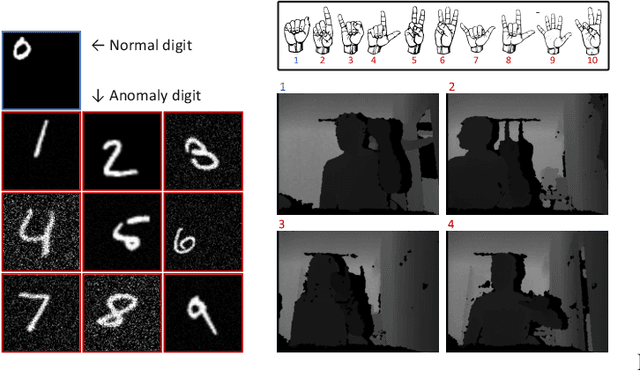
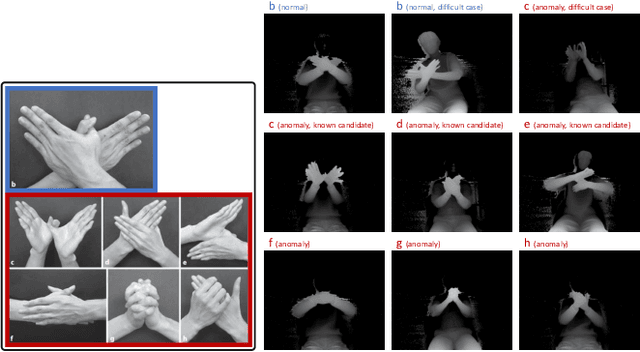
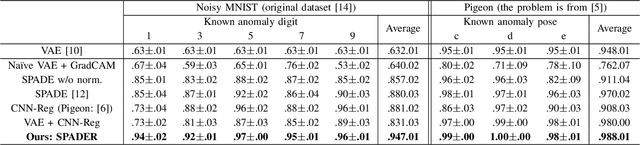
Visual anomaly detection is common in several applications including medical screening and production quality check. Although a definition of the anomaly is an unknown trend in data, in many cases some hints or samples of the anomaly class can be given in advance. Conventional methods cannot use the available anomaly data, and also do not have a robustness of noise. In this paper, we propose a novel spatially-weighted reconstruction-loss-based anomaly detection with a likelihood value from a regression model trained by all known data. The spatial weights are calculated by a region of interest generated from employing visualization of the regression model. We introduce some ways to combine with various strategies to propose a state-of-the-art method. Comparing with other methods on three different datasets, we empirically verify the proposed method performs better than the others.
Internal Model from Observations for Reward Shaping
Oct 14, 2018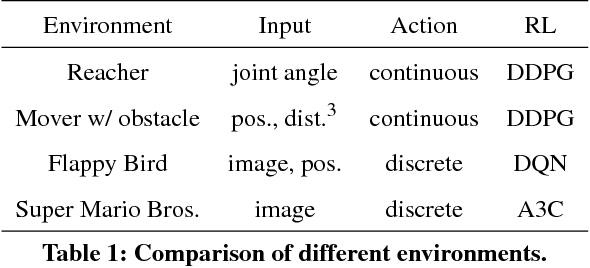
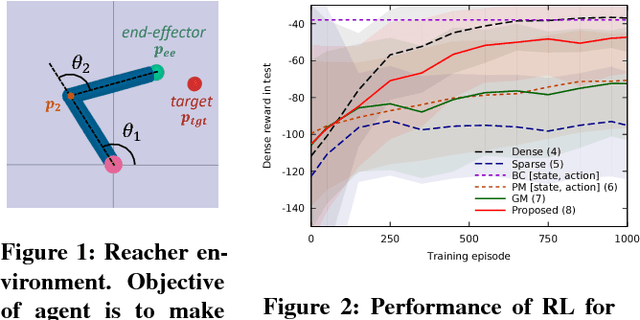
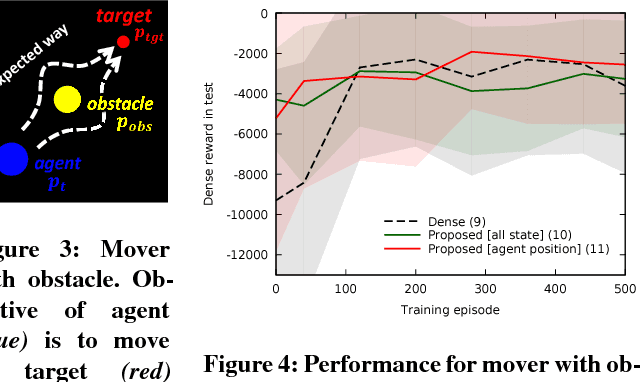
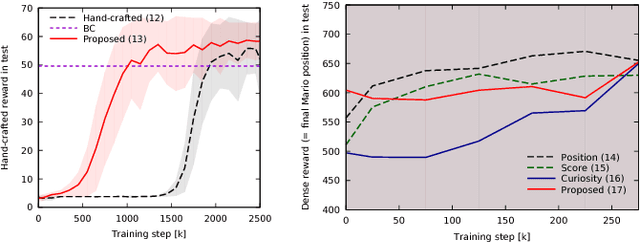
Reinforcement learning methods require careful design involving a reward function to obtain the desired action policy for a given task. In the absence of hand-crafted reward functions, prior work on the topic has proposed several methods for reward estimation by using expert state trajectories and action pairs. However, there are cases where complete or good action information cannot be obtained from expert demonstrations. We propose a novel reinforcement learning method in which the agent learns an internal model of observation on the basis of expert-demonstrated state trajectories to estimate rewards without completely learning the dynamics of the external environment from state-action pairs. The internal model is obtained in the form of a predictive model for the given expert state distribution. During reinforcement learning, the agent predicts the reward as a function of the difference between the actual state and the state predicted by the internal model. We conducted multiple experiments in environments of varying complexity, including the Super Mario Bros and Flappy Bird games. We show our method successfully trains good policies directly from expert game-play videos.
Video Imitation GAN: Learning control policies by imitating raw videos using generative adversarial reward estimation
Oct 02, 2018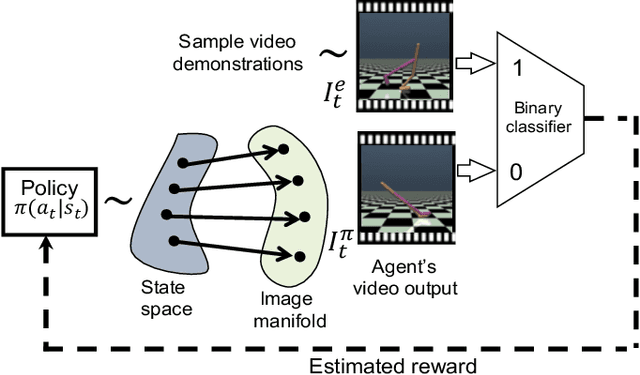
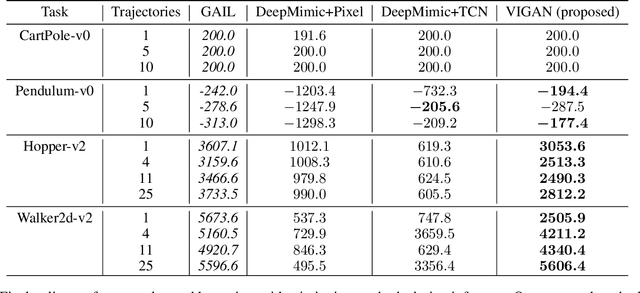
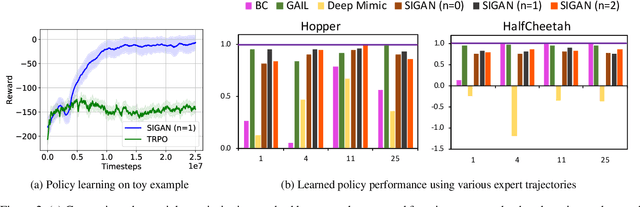
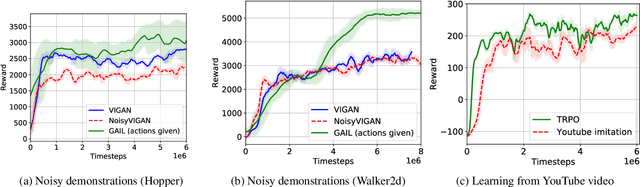
Natural imitation in humans usually consists of mimicking visual demonstrations of another person by continuously refining our skills until our performance is visually akin to the expert demonstrations. In this paper, we are interested in imitation learning of artificial agents in the natural setting - acquiring motor skills by watching raw video demonstrations. Traditional methods for learning from videos rely on extracting meaningful low-dimensional features from the videos followed by a separate hand-crafted reward estimation step based on feature separation between the agent and expert. We propose an imitation learning framework from raw video demonstrations, that reduces the dependence on hand engineered reward functions, by jointly learning the feature extraction and separation estimation steps, using generative adversarial networks. Additionally, we establish the equivalence between adversarial imitation from image manifolds and low-level state distribution matching, under certain conditions. Experimental results show that our proposed imitation learning method from raw videos produces a similar performance to state-of-the-art imitation learning techniques with low-level state and action information available while outperforming existing video imitation methods. Furthermore, we show that our method can learn action policies by imitating video demonstrations available on YouTube with performance comparable to learned agents from true reward signal. Please see the video at https://youtu.be/bvNpV2Q4rOA.
Constrained Exploration and Recovery from Experience Shaping
Sep 21, 2018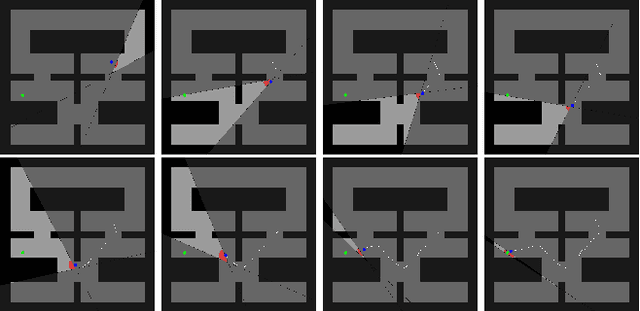
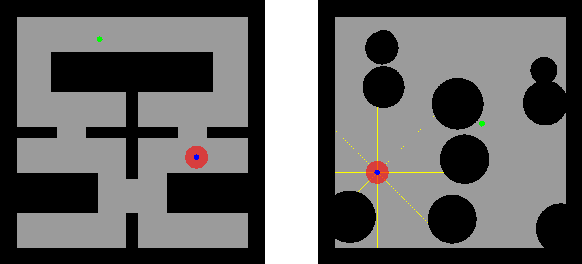
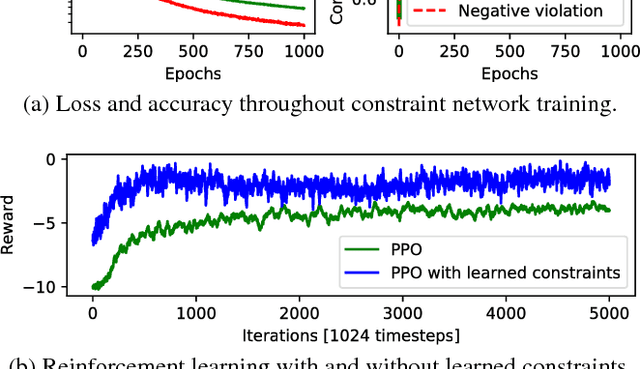

We consider the problem of reinforcement learning under safety requirements, in which an agent is trained to complete a given task, typically formalized as the maximization of a reward signal over time, while concurrently avoiding undesirable actions or states, associated to lower rewards, or penalties. The construction and balancing of different reward components can be difficult in the presence of multiple objectives, yet is crucial for producing a satisfying policy. For example, in reaching a target while avoiding obstacles, low collision penalties can lead to reckless movements while high penalties can discourage exploration. To circumvent this limitation, we examine the effect of past actions in terms of safety to estimate which are acceptable or should be avoided in the future. We then actively reshape the action space of the agent during reinforcement learning, so that reward-driven exploration is constrained within safety limits. We propose an algorithm enabling the learning of such safety constraints in parallel with reinforcement learning and demonstrate its effectiveness in terms of both task completion and training time.