 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Image, Different Meanings: Toward Retrieval of Context-Dependent Meanings
May 13, 2026A scene of two people in the rain can convey hope and warmth in a reunion story or sorrow and finality in a farewell story. We investigate this context-dependent nature of image meaning and its implications for retrieval. Our key observation is that context dependency correlates with semantic abstraction: concrete elements (objects, actions) remain stable across contexts, while abstract elements (atmosphere, intent) shift with context. We operationalize this as the L1--L4 framework, organizing image semantics from context-independent (L1) to maximally context-dependent (L4). Using synthetic story contexts and queries for controlled evaluation, we examine how injecting narrative context into embeddings affects retrieval across abstraction levels. Concrete queries are retrievable without context, while abstract levels increasingly depend on narrative grounding. Where context is injected also matters, with image-side enrichment proving particularly effective. The most abstract level, however, remains challenging even with full context, highlighting context-dependent image retrieval as an important open problem. Our framework and findings lay groundwork toward retrieval systems that handle the context-dependent meanings images acquire in narrative settings.
Exploring Database Normalization Effects on SQL Generation
Oct 02, 2025Schema design, particularly normalization, is a critical yet often overlooked factor in natural language to SQL (NL2SQL) systems. Most prior research evaluates models on fixed schemas, overlooking the influence of design on performance. We present the first systematic study of schema normalization's impact, evaluating eight leading large language models on synthetic and real-world datasets with varied normalization levels. We construct controlled synthetic datasets with formal normalization (1NF-3NF) and real academic paper datasets with practical schemes. Our results show that denormalized schemas offer high accuracy on simple retrieval queries, even with cost-effective models in zero-shot settings. In contrast, normalized schemas (2NF/3NF) introduce challenges such as errors in base table selection and join type prediction; however, these issues are substantially mitigated by providing few-shot examples. For aggregation queries, normalized schemas yielded better performance, mainly due to their robustness against the data duplication and NULL value issues that cause errors in denormalized schemas. These findings suggest that the optimal schema design for NL2SQL applications depends on the types of queries to be supported. Our study demonstrates the importance of considering schema design when developing NL2SQL interfaces and integrating adaptive schema selection for real-world scenarios.
LOA: Logical Optimal Actions for Text-based Interaction Games
Oct 21, 2021
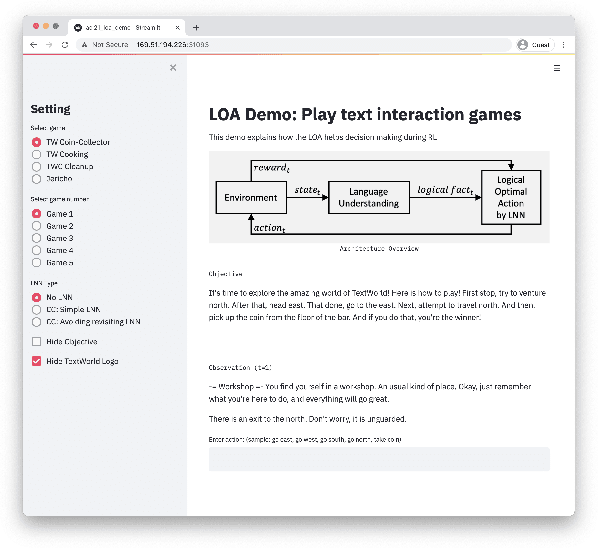
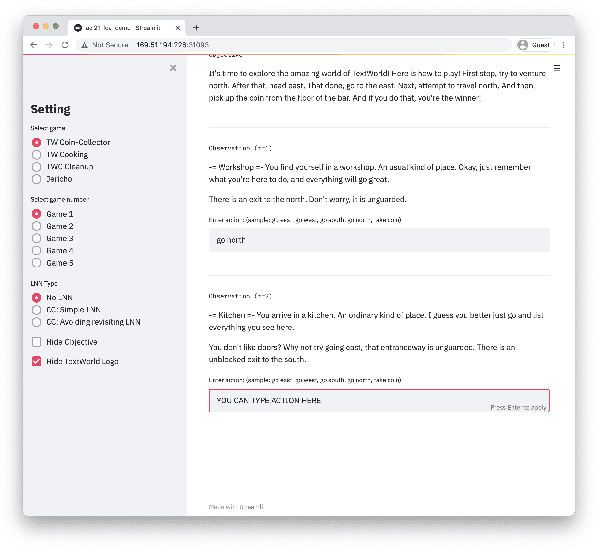
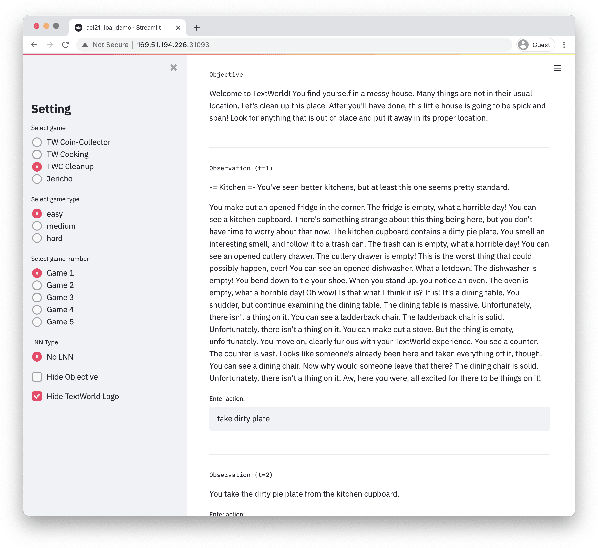
We present Logical Optimal Actions (LOA), an action decision architecture of reinforcement learning applications with a neuro-symbolic framework which is a combination of neural network and symbolic knowledge acquisition approach for natural language interaction games. The demonstration for LOA experiments consists of a web-based interactive platform for text-based games and visualization for acquired knowledge for improving interpretability for trained rules. This demonstration also provides a comparison module with other neuro-symbolic approaches as well as non-symbolic state-of-the-art agent models on the same text-based games. Our LOA also provides open-sourced implementation in Python for the reinforcement learning environment to facilitate an experiment for studying neuro-symbolic agents. Code: https://github.com/ibm/loa
Neuro-Symbolic Reinforcement Learning with First-Order Logic
Oct 21, 2021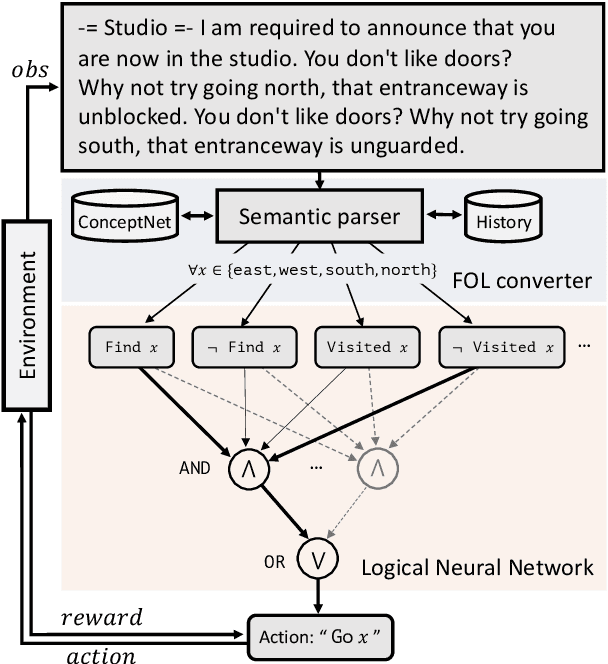
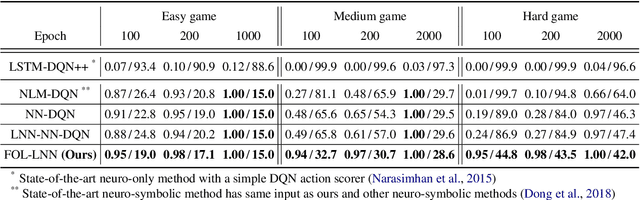
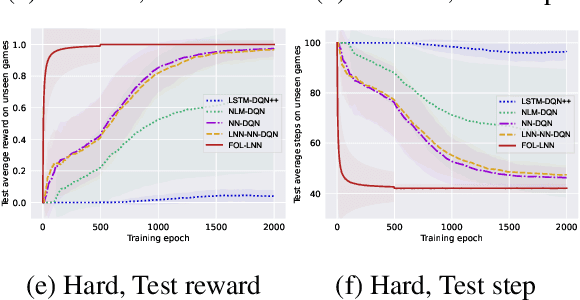
Deep reinforcement learning (RL) methods often require many trials before convergence, and no direct interpretability of trained policies is provided. In order to achieve fast convergence and interpretability for the policy in RL, we propose a novel RL method for text-based games with a recent neuro-symbolic framework called Logical Neural Network, which can learn symbolic and interpretable rules in their differentiable network. The method is first to extract first-order logical facts from text observation and external word meaning network (ConceptNet), then train a policy in the network with directly interpretable logical operators. Our experimental results show RL training with the proposed method converges significantly faster than other state-of-the-art neuro-symbolic methods in a TextWorld benchmark.
Reinforcement Learning with External Knowledge by using Logical Neural Networks
Mar 03, 2021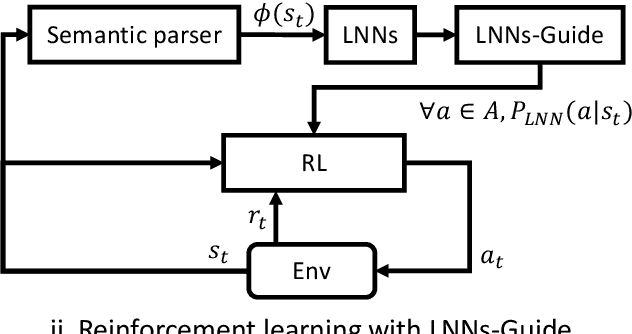
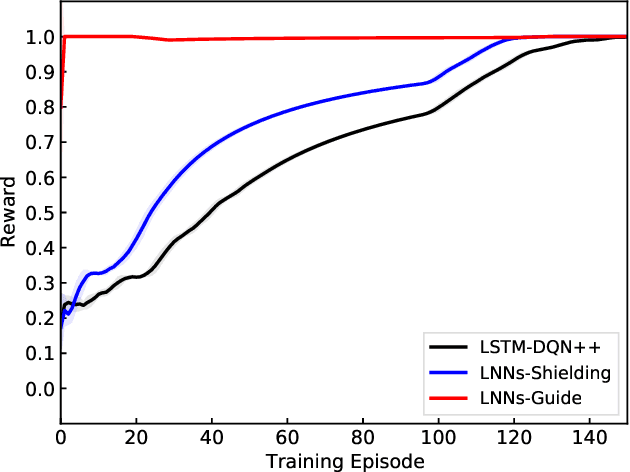
Conventional deep reinforcement learning methods are sample-inefficient and usually require a large number of training trials before convergence. Since such methods operate on an unconstrained action set, they can lead to useless actions. A recent neuro-symbolic framework called the Logical Neural Networks (LNNs) can simultaneously provide key-properties of both neural networks and symbolic logic. The LNNs functions as an end-to-end differentiable network that minimizes a novel contradiction loss to learn interpretable rules. In this paper, we utilize LNNs to define an inference graph using basic logical operations, such as AND and NOT, for faster convergence in reinforcement learning. Specifically, we propose an integrated method that enables model-free reinforcement learning from external knowledge sources in an LNNs-based logical constrained framework such as action shielding and guide. Our results empirically demonstrate that our method converges faster compared to a model-free reinforcement learning method that doesn't have such logical constraints.
Structural Supervision Improves Few-Shot Learning and Syntactic Generalization in Neural Language Models
Oct 12, 2020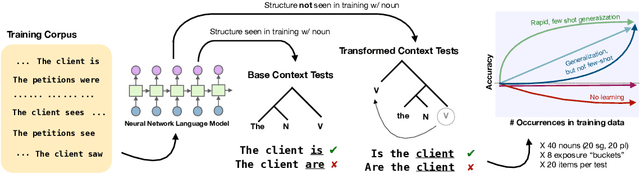
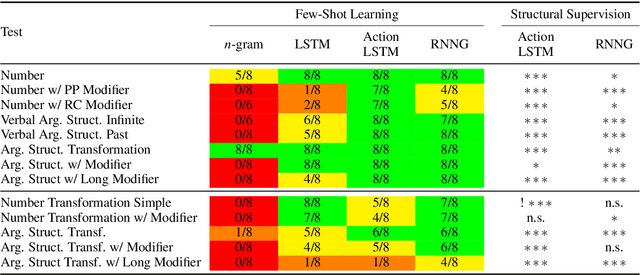
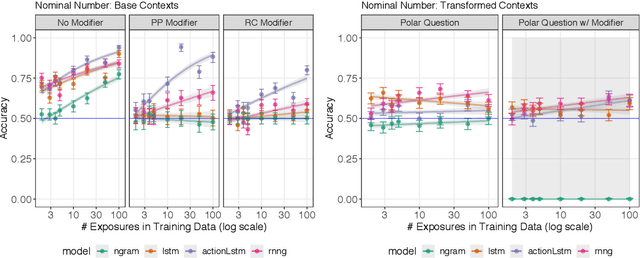
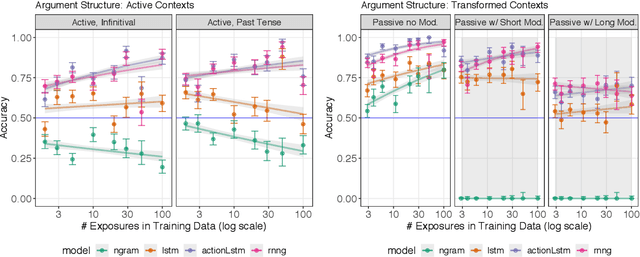
Humans can learn structural properties about a word from minimal experience, and deploy their learned syntactic representations uniformly in different grammatical contexts. We assess the ability of modern neural language models to reproduce this behavior in English and evaluate the effect of structural supervision on learning outcomes. First, we assess few-shot learning capabilities by developing controlled experiments that probe models' syntactic nominal number and verbal argument structure generalizations for tokens seen as few as two times during training. Second, we assess invariance properties of learned representation: the ability of a model to transfer syntactic generalizations from a base context (e.g., a simple declarative active-voice sentence) to a transformed context (e.g., an interrogative sentence). We test four models trained on the same dataset: an n-gram baseline, an LSTM, and two LSTM-variants trained with explicit structural supervision (Dyer et al.,2016; Charniak et al., 2016). We find that in most cases, the neural models are able to induce the proper syntactic generalizations after minimal exposure, often from just two examples during training, and that the two structurally supervised models generalize more accurately than the LSTM model. All neural models are able to leverage information learned in base contexts to drive expectations in transformed contexts, indicating that they have learned some invariance properties of syntax.
Q-learning with Language Model for Edit-based Unsupervised Summarization
Oct 09, 2020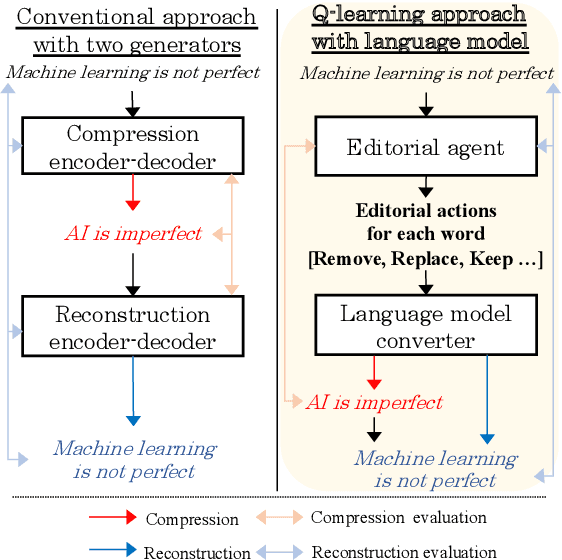
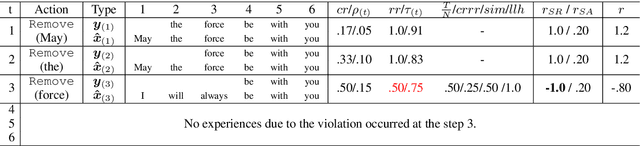
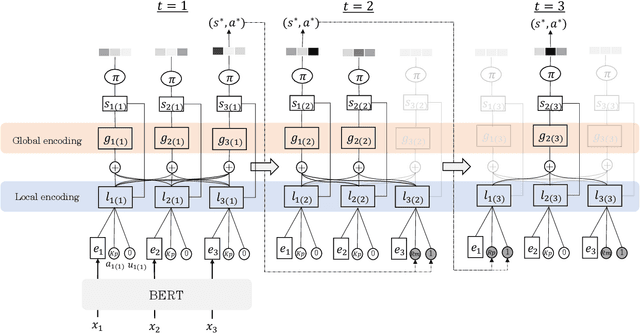
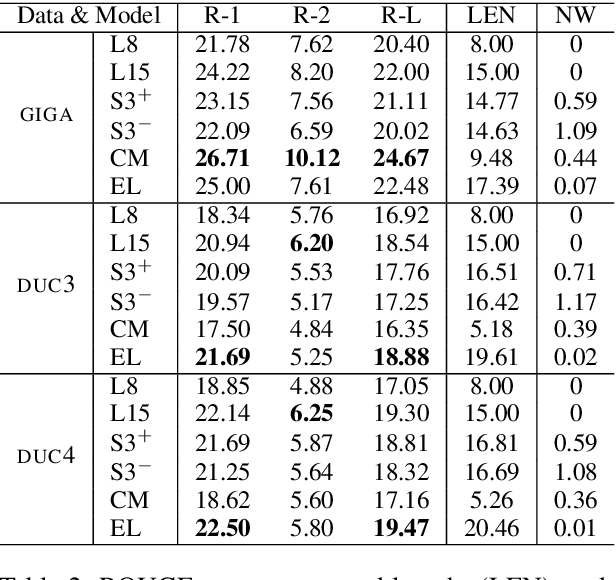
Unsupervised methods are promising for abstractive text summarization in that the parallel corpora is not required. However, their performance is still far from being satisfied, therefore research on promising solutions is on-going. In this paper, we propose a new approach based on Q-learning with an edit-based summarization. The method combines two key modules to form an Editorial Agent and Language Model converter (EALM). The agent predicts edit actions (e.t., delete, keep, and replace), and then the LM converter deterministically generates a summary on the basis of the action signals. Q-learning is leveraged to train the agent to produce proper edit actions. Experimental results show that EALM delivered competitive performance compared with the previous encoder-decoder-based methods, even with truly zero paired data (i.e., no validation set). Defining the task as Q-learning enables us not only to develop a competitive method but also to make the latest techniques in reinforcement learning available for unsupervised summarization. We also conduct qualitative analysis, providing insights into future study on unsupervised summarizers.