 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Supervision Improves Few-Shot Learning and Syntactic Generalization in Neural Language Models
Paper and Code
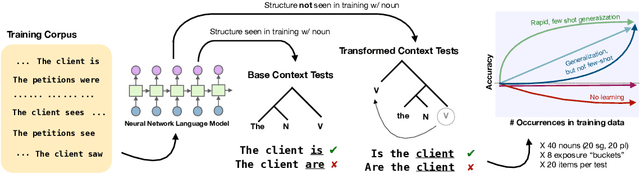
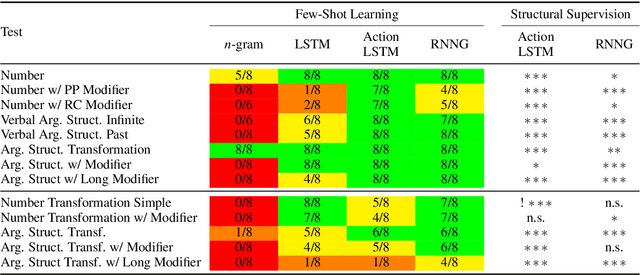
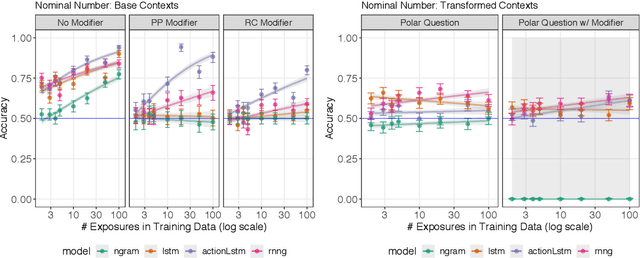
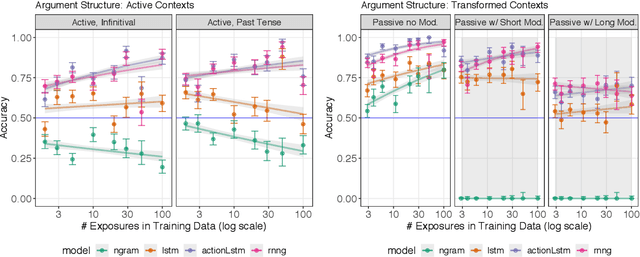
Humans can learn structural properties about a word from minimal experience, and deploy their learned syntactic representations uniformly in different grammatical contexts. We assess the ability of modern neural language models to reproduce this behavior in English and evaluate the effect of structural supervision on learning outcomes. First, we assess few-shot learning capabilities by developing controlled experiments that probe models' syntactic nominal number and verbal argument structure generalizations for tokens seen as few as two times during training. Second, we assess invariance properties of learned representation: the ability of a model to transfer syntactic generalizations from a base context (e.g., a simple declarative active-voice sentence) to a transformed context (e.g., an interrogative sentence). We test four models trained on the same dataset: an n-gram baseline, an LSTM, and two LSTM-variants trained with explicit structural supervision (Dyer et al.,2016; Charniak et al., 2016). We find that in most cases, the neural models are able to induce the proper syntactic generalizations after minimal exposure, often from just two examples during training, and that the two structurally supervised models generalize more accurately than the LSTM model. All neural models are able to leverage information learned in base contexts to drive expectations in transformed contexts, indicating that they have learned some invariance properties of syntax.