 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Traffic Density from Large-Scale Web Camera Data
Paper and Code

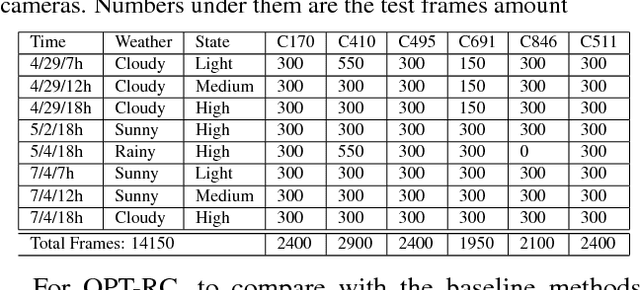
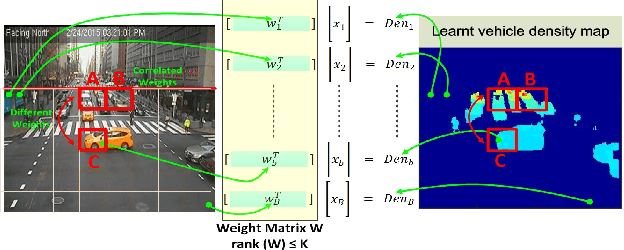
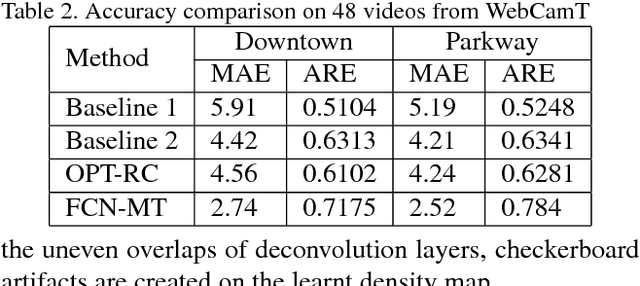
Understanding traffic density from large-scale web camera (webcam) videos is a challenging problem because such videos have low spatial and temporal resolution, high occlusion and large perspective. To deeply understand traffic density, we explore both deep learning based and optimization based methods. To avoid individual vehicle detection and tracking, both methods map the image into vehicle density map, one based on rank constrained regression and the other one based on fully convolution networks (FCN). The regression based method learns different weights for different blocks in the image to increase freedom degrees of weights and embed perspective information. The FCN based method jointly estimates vehicle density map and vehicle count with a residual learning framework to perform end-to-end dense prediction, allowing arbitrary image resolution, and adapting to different vehicle scales and perspectives. We analyze and compare both methods, and get insights from optimization based method to improve deep model. Since existing datasets do not cover all the challenges in our work, we collected and labelled a large-scale traffic video dataset, containing 60 million frames from 212 webcams. Both methods are extensively evaluated and compared on different counting tasks and datasets. FCN based method significantly reduces the mean absolute error from 10.99 to 5.31 on the public dataset TRANCOS compared with the state-of-the-art baseline.