 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCN-rLSTM: Deep Spatio-Temporal Neural Networks for Vehicle Counting in City Cameras
Paper and Code
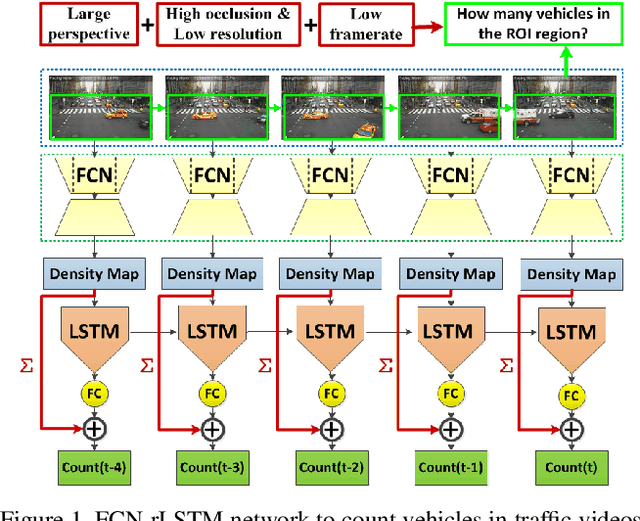


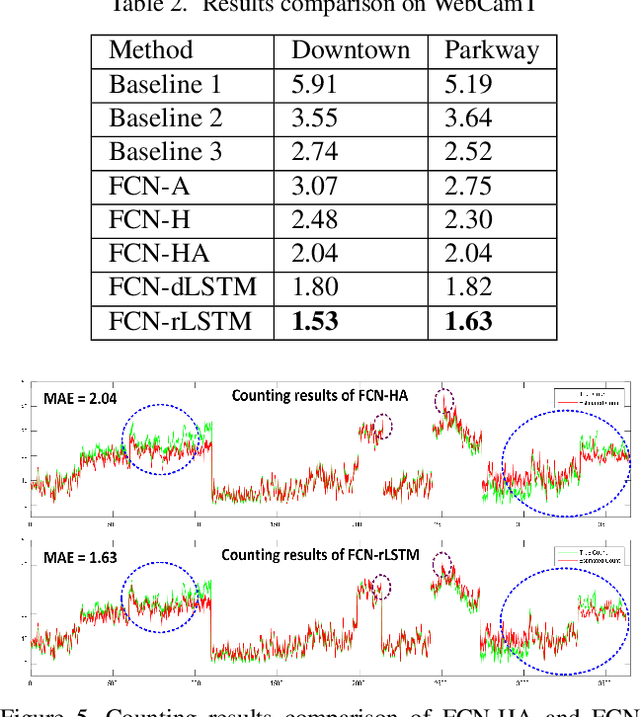
In this paper, we develop deep spatio-temporal neural networks to sequentially count vehicles from low quality videos captured by city cameras (citycams). Citycam videos have low resolution, low frame rate, high occlusion and large perspective, making most existing methods lose their efficacy. To overcome limitations of existing methods and incorporate the temporal information of traffic video, we design a novel FCN-rLSTM network to jointly estimate vehicle density and vehicle count by connecting fully convolutional neural networks (FCN) with long short term memory networks (LSTM) in a residual learning fashion. Such design leverages the strengths of FCN for pixel-level prediction and the strengths of LSTM for learning complex temporal dynamics. The residual learning connection reformulates the vehicle count regression as learning residual functions with reference to the sum of densities in each frame, which significantly accelerates the training of networks. To preserve feature map resolution, we propose a Hyper-Atrous combination to integrate atrous convolution in FCN and combine feature maps of different convolution layers. FCN-rLSTM enables refined feature representation and a novel end-to-end trainable mapping from pixels to vehicle count. We extensively evaluated the proposed method on different counting tasks with three datasets, with experimental results demonstrating their effectiveness and robustness. In particular, FCN-rLSTM reduces the mean absolute error (MAE) from 5.31 to 4.21 on TRANCOS, and reduces the MAE from 2.74 to 1.53 on WebCamT. Training process is accelerated by 5 times on average.