 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Pretraining for Paraphrase Evaluation
Jul 24, 2021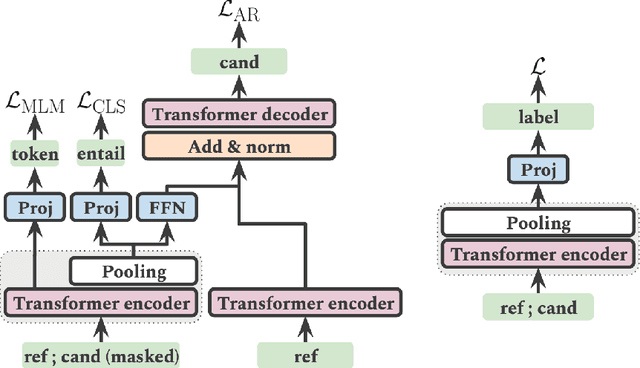
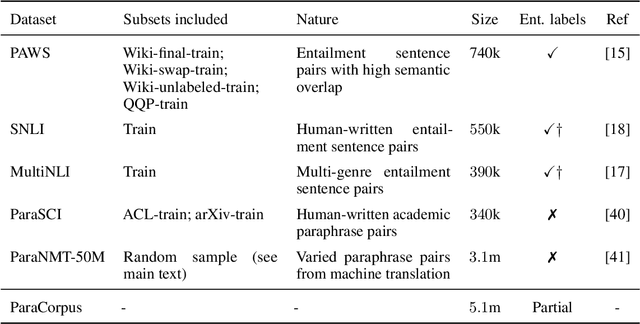
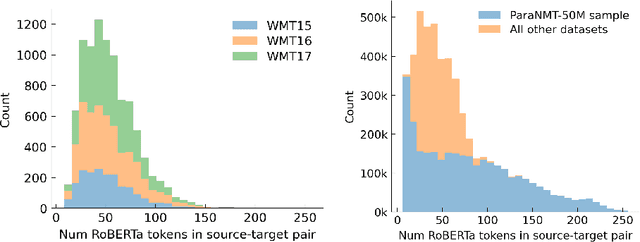

We introduce ParaBLEU, a paraphrase representation learning model and evaluation metric for text generation. Unlike previous approaches, ParaBLEU learns to understand paraphrasis using generative conditioning as a pretraining objective. ParaBLEU correlates more strongly with human judgements than existing metrics, obtaining new state-of-the-art results on the 2017 WMT Metrics Shared Task. We show that our model is robust to data scarcity, exceeding previous state-of-the-art performance using only $50\%$ of the available training data and surpassing BLEU, ROUGE and METEOR with only $40$ labelled examples. Finally, we demonstrate that ParaBLEU can be used to conditionally generate novel paraphrases from a single demonstration, which we use to confirm our hypothesis that it learns abstract, generalized paraphrase representations.
Learning De-identified Representations of Prosody from Raw Audio
Jul 17, 2021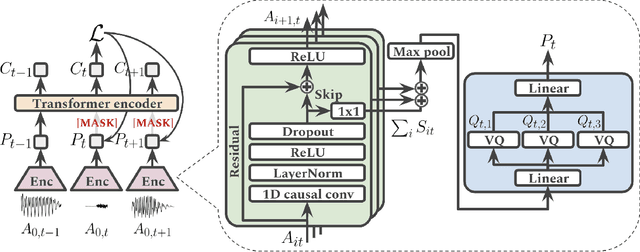
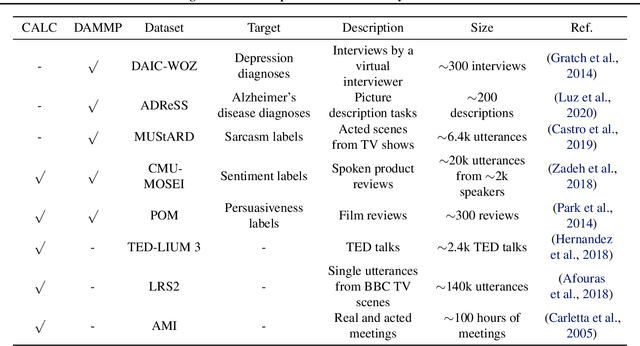
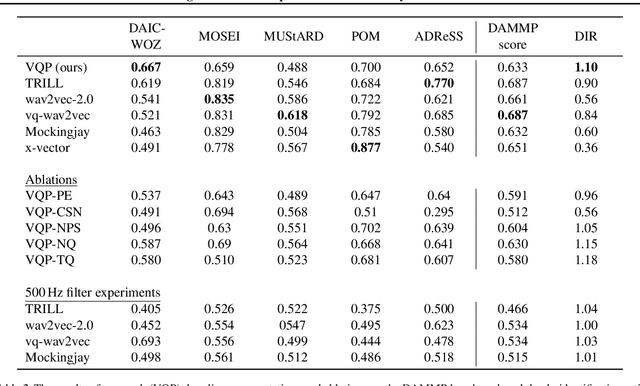
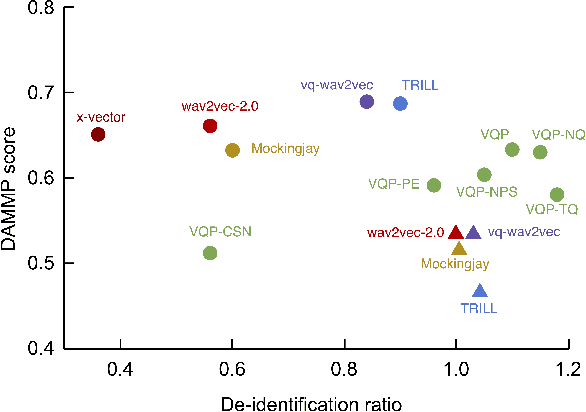
We propose a method for learning de-identified prosody representations from raw audio using a contrastive self-supervised signal. Whereas prior work has relied on conditioning models on bottlenecks, we introduce a set of inductive biases that exploit the natural structure of prosody to minimize timbral information and decouple prosody from speaker representations. Despite aggressive downsampling of the input and having no access to linguistic information, our model performs comparably to state-of-the-art speech representations on DAMMP, a new benchmark we introduce for spoken language understanding. We use minimum description length probing to show that our representations have selectively learned the subcomponents of non-timbral prosody, and that the product quantizer naturally disentangles them without using bottlenecks. We derive an information-theoretic definition of speech de-identifiability and use it to demonstrate that our prosody representations are less identifiable than other speech representations.
* ICML 2021
Incremental Text to Speech for Neural Sequence-to-Sequence Models using Reinforcement Learning
Aug 07, 2020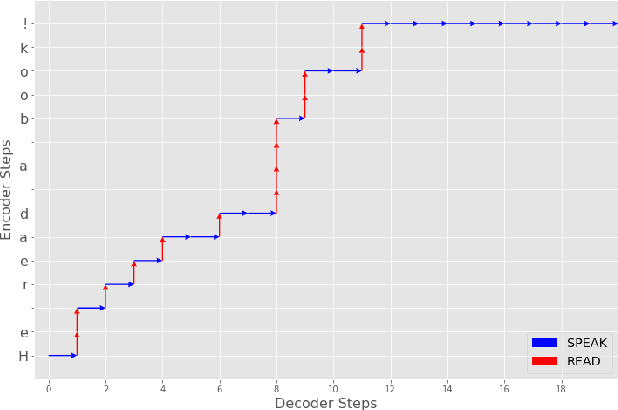

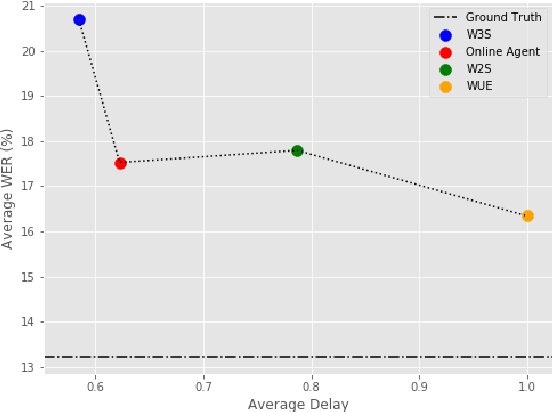
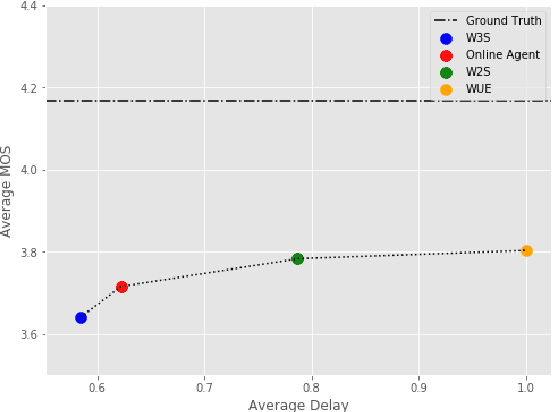
Modern approaches to text to speech require the entire input character sequence to be processed before any audio is synthesised. This latency limits the suitability of such models for time-sensitive tasks like simultaneous interpretation. Interleaving the action of reading a character with that of synthesising audio reduces this latency. However, the order of this sequence of interleaved actions varies across sentences, which raises the question of how the actions should be chosen. We propose a reinforcement learning based framework to train an agent to make this decision. We compare our performance against that of deterministic, rule-based systems. Our results demonstrate that our agent successfully balances the trade-off between the latency of audio generation and the quality of synthesised audio. More broadly, we show that neural sequence-to-sequence models can be adapted to run in an incremental manner.
Phonological Features for 0-shot Multilingual Speech Synthesis
Aug 06, 2020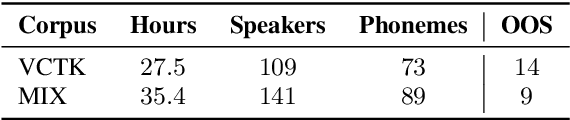


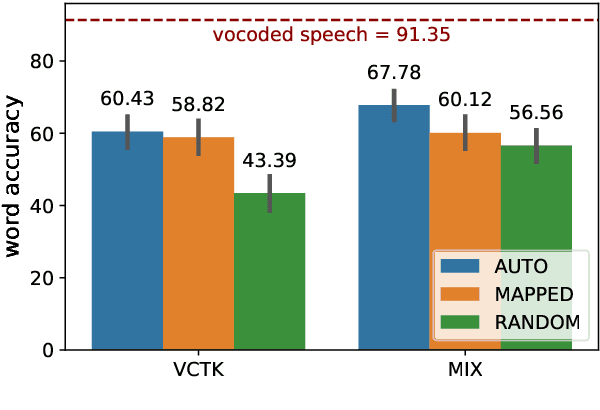
Code-switching---the intra-utterance use of multiple languages---is prevalent across the world. Within text-to-speech (TTS), multilingual models have been found to enable code-switching. By modifying the linguistic input to sequence-to-sequence TTS, we show that code-switching is possible for languages unseen during training, even within monolingual models. We use a small set of phonological features derived from the International Phonetic Alphabet (IPA), such as vowel height and frontness, consonant place and manner. This allows the model topology to stay unchanged for different languages, and enables new, previously unseen feature combinations to be interpreted by the model. We show that this allows us to generate intelligible, code-switched speech in a new language at test time, including the approximation of sounds never seen in training.
BlaBla: Linguistic Feature Extraction for Clinical Analysis in Multiple Languages
May 20, 2020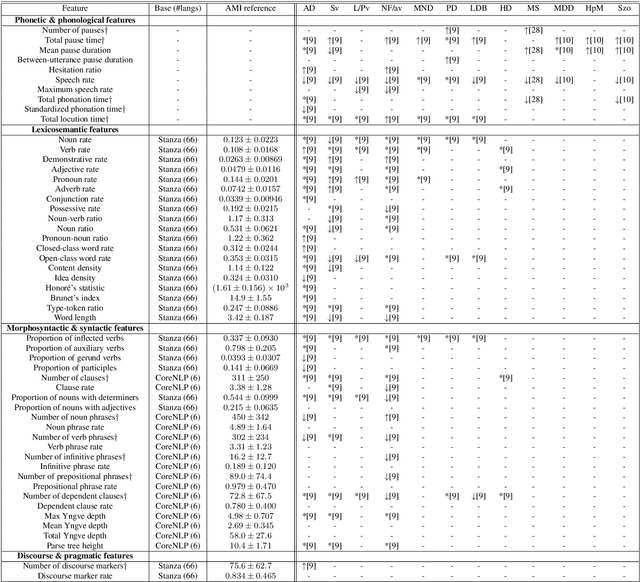


We introduce BlaBla, an open-source Python library for extracting linguistic features with proven clinical relevance to neurological and psychiatric diseases across many languages. BlaBla is a unifying framework for accelerating and simplifying clinical linguistic research. The library is built on state-of-the-art NLP frameworks and supports multithreaded/GPU-enabled feature extraction via both native Python calls and a command line interface. We describe BlaBla's architecture and clinical validation of its features across 12 diseases. We further demonstrate the application of BlaBla to a task visualizing and classifying language disorders in three languages on real clinical data from the AphasiaBank dataset. We make the codebase freely available to researchers with the hope of providing a consistent, well-validated foundation for the next generation of clinical linguistic research.
Surfboard: Audio Feature Extraction for Modern Machine Learning
May 18, 2020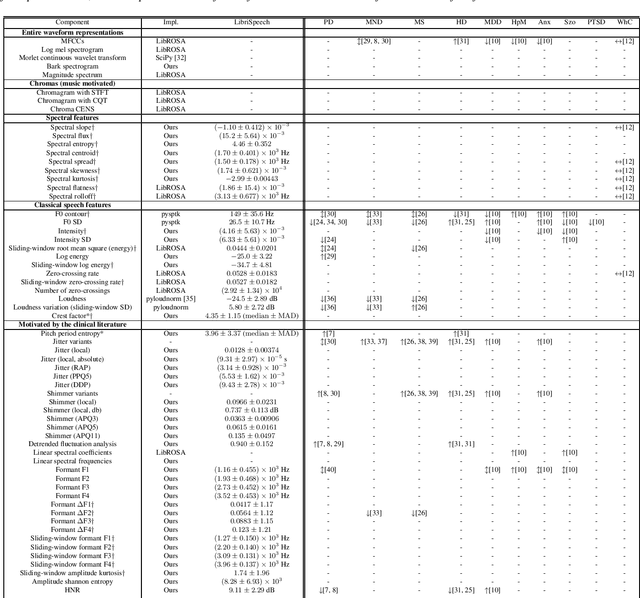
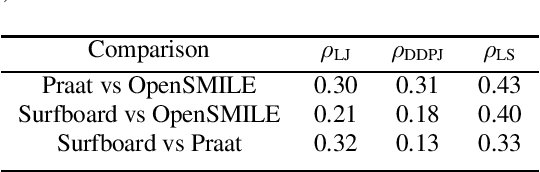
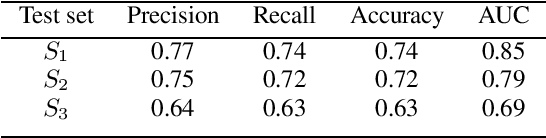
We introduce Surfboard, an open-source Python library for extracting audio features with application to the medical domain. Surfboard is written with the aim of addressing pain points of existing libraries and facilitating joint use with modern machine learning frameworks. The package can be accessed both programmatically in Python and via its command line interface, allowing it to be easily integrated within machine learning workflows. It builds on state-of-the-art audio analysis packages and offers multiprocessing support for processing large workloads. We review similar frameworks and describe Surfboard's architecture, including the clinical motivation for its features. Using the mPower dataset, we illustrate Surfboard's application to a Parkinson's disease classification task, highlighting common pitfalls in existing research. The source code is opened up to the research community to facilitate future audio research in the clinical domain.