 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Pretraining for Paraphrase Evaluation
Jul 24, 2021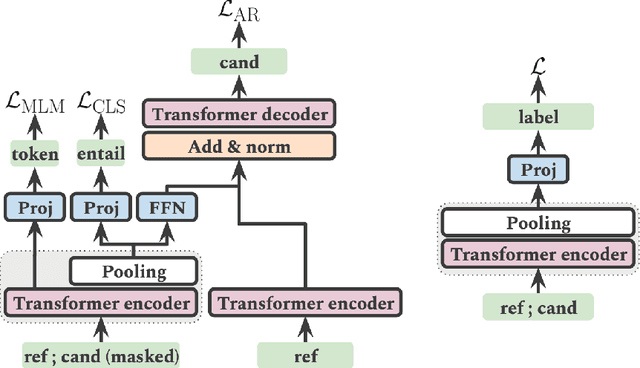
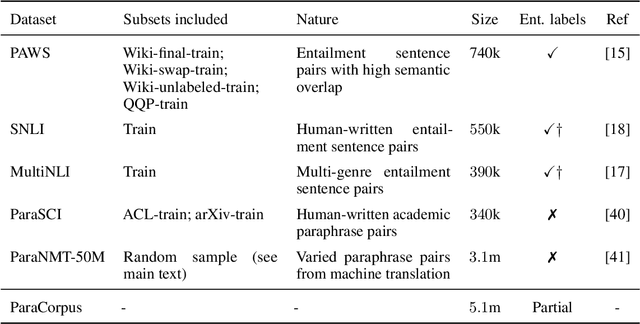
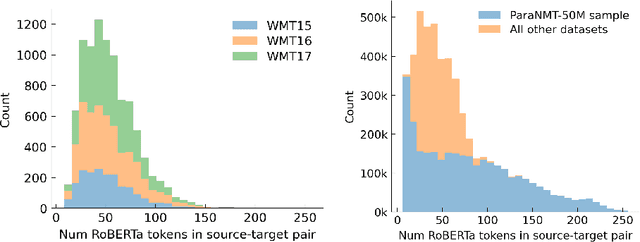

We introduce ParaBLEU, a paraphrase representation learning model and evaluation metric for text generation. Unlike previous approaches, ParaBLEU learns to understand paraphrasis using generative conditioning as a pretraining objective. ParaBLEU correlates more strongly with human judgements than existing metrics, obtaining new state-of-the-art results on the 2017 WMT Metrics Shared Task. We show that our model is robust to data scarcity, exceeding previous state-of-the-art performance using only $50\%$ of the available training data and surpassing BLEU, ROUGE and METEOR with only $40$ labelled examples. Finally, we demonstrate that ParaBLEU can be used to conditionally generate novel paraphrases from a single demonstration, which we use to confirm our hypothesis that it learns abstract, generalized paraphrase representations.
Learning De-identified Representations of Prosody from Raw Audio
Jul 17, 2021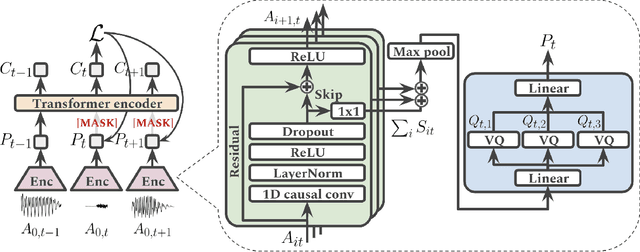
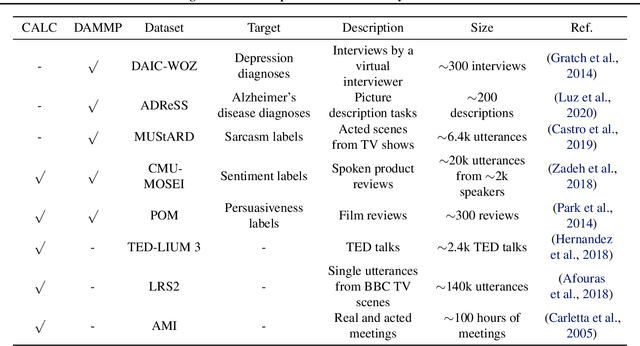
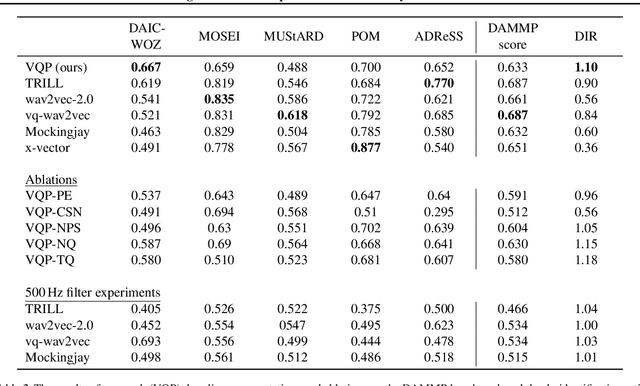
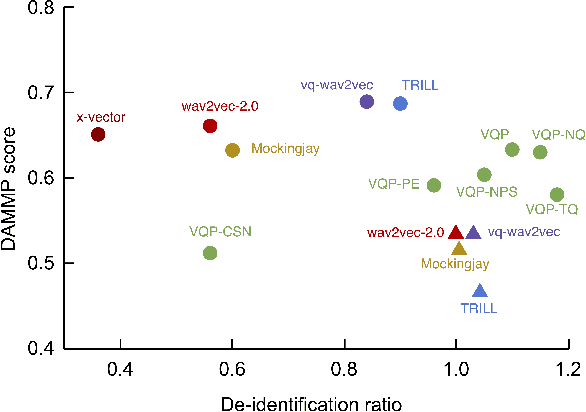
We propose a method for learning de-identified prosody representations from raw audio using a contrastive self-supervised signal. Whereas prior work has relied on conditioning models on bottlenecks, we introduce a set of inductive biases that exploit the natural structure of prosody to minimize timbral information and decouple prosody from speaker representations. Despite aggressive downsampling of the input and having no access to linguistic information, our model performs comparably to state-of-the-art speech representations on DAMMP, a new benchmark we introduce for spoken language understanding. We use minimum description length probing to show that our representations have selectively learned the subcomponents of non-timbral prosody, and that the product quantizer naturally disentangles them without using bottlenecks. We derive an information-theoretic definition of speech de-identifiability and use it to demonstrate that our prosody representations are less identifiable than other speech representations.
* ICML 2021
Super-resolution of Time-series Labels for Bootstrapped Event Detection
Jun 01, 2019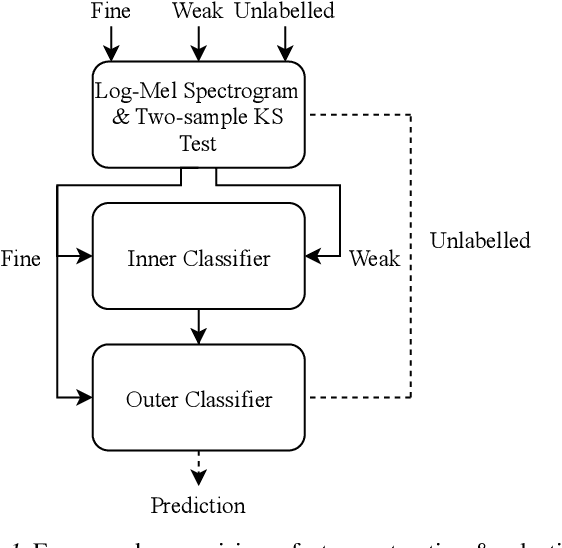
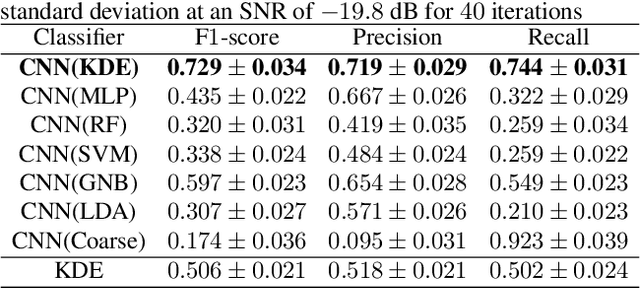
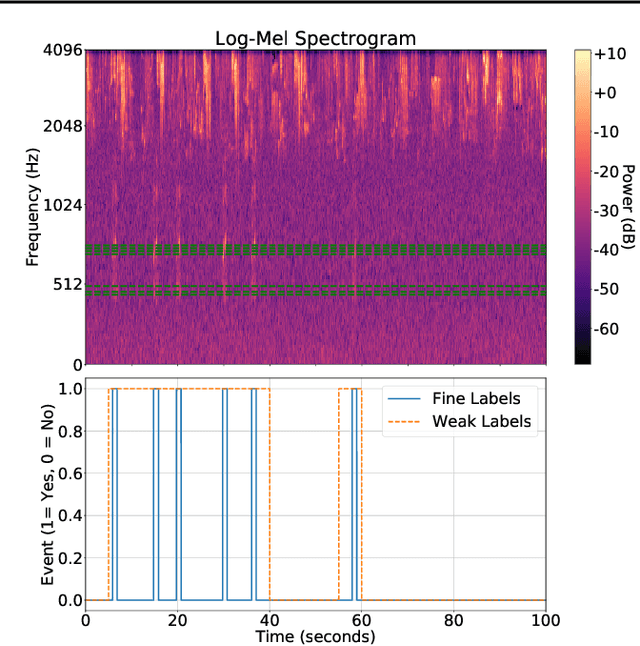

Solving real-world problems, particularly with deep learning, relies on the availability of abundant, quality data. In this paper we develop a novel framework that maximises the utility of time-series datasets that contain only small quantities of expertly-labelled data, larger quantities of weakly (or coarsely) labelled data and a large volume of unlabelled data. This represents scenarios commonly encountered in the real world, such as in crowd-sourcing applications. In our work, we use a nested loop using a Kernel Density Estimator (KDE) to super-resolve the abundant low-quality data labels, thereby enabling effective training of a Convolutional Neural Network (CNN). We demonstrate two key results: a) The KDE is able to super-resolve labels more accurately, and with better calibrated probabilities, than well-established classifiers acting as baselines; b) Our CNN, trained on super-resolved labels from the KDE, achieves an improvement in F1 score of 22.1% over the next best baseline system in our candidate problem domain.