 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-resolution of Time-series Labels for Bootstrapped Event Detection
Jun 01, 2019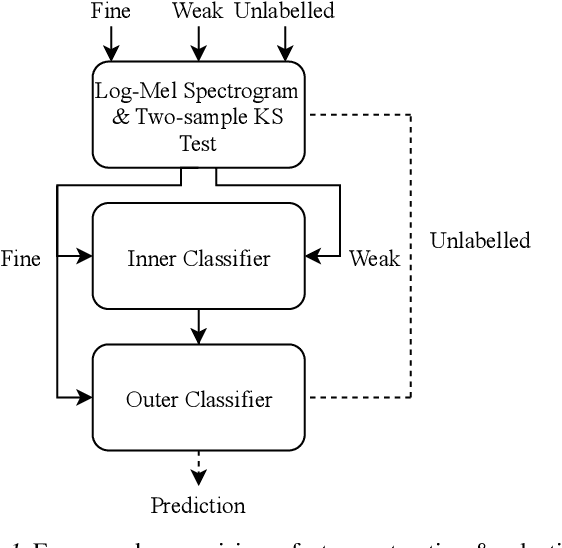
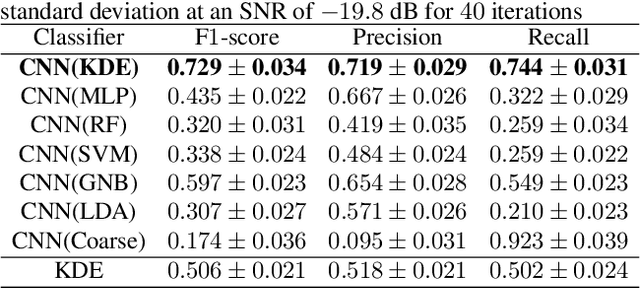
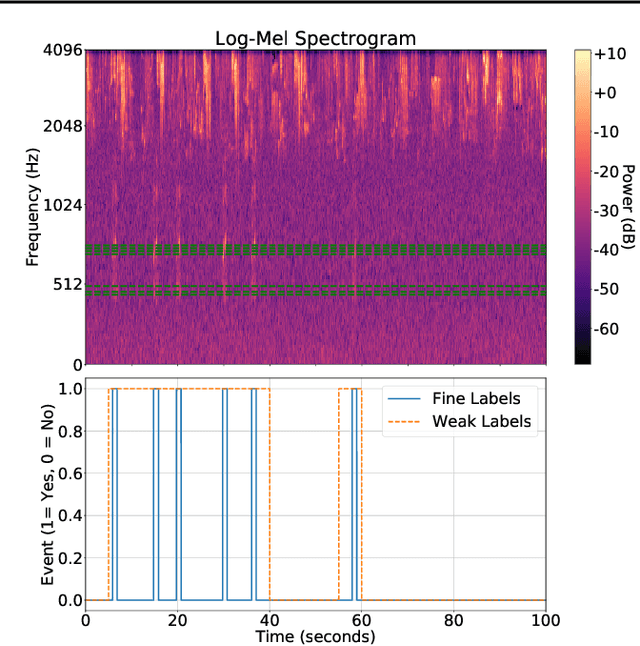

Solving real-world problems, particularly with deep learning, relies on the availability of abundant, quality data. In this paper we develop a novel framework that maximises the utility of time-series datasets that contain only small quantities of expertly-labelled data, larger quantities of weakly (or coarsely) labelled data and a large volume of unlabelled data. This represents scenarios commonly encountered in the real world, such as in crowd-sourcing applications. In our work, we use a nested loop using a Kernel Density Estimator (KDE) to super-resolve the abundant low-quality data labels, thereby enabling effective training of a Convolutional Neural Network (CNN). We demonstrate two key results: a) The KDE is able to super-resolve labels more accurately, and with better calibrated probabilities, than well-established classifiers acting as baselines; b) Our CNN, trained on super-resolved labels from the KDE, achieves an improvement in F1 score of 22.1% over the next best baseline system in our candidate problem domain.