 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Text to Speech for Neural Sequence-to-Sequence Models using Reinforcement Learning
Paper and Code
Aug 07, 2020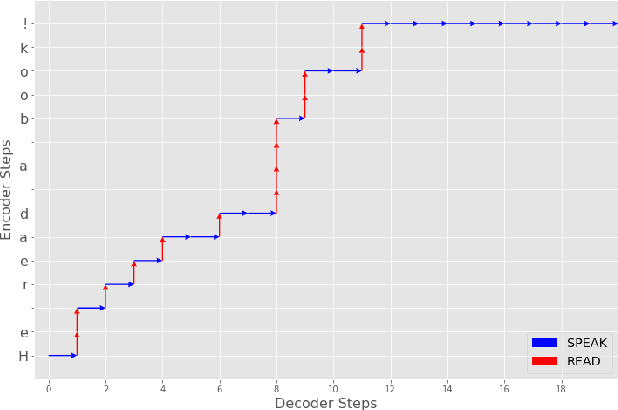

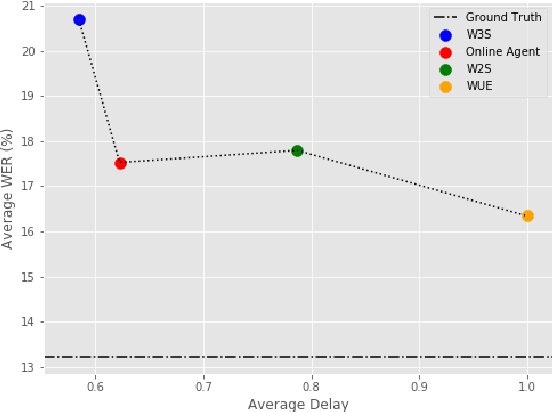
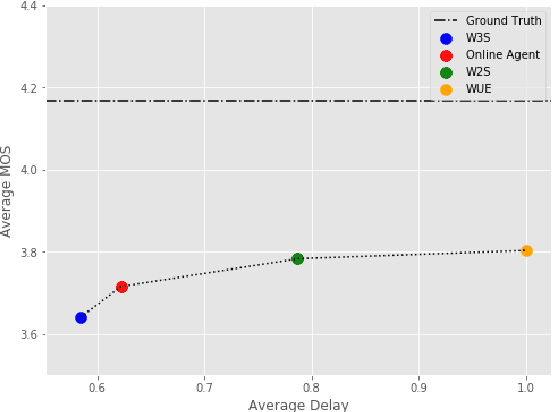
Modern approaches to text to speech require the entire input character sequence to be processed before any audio is synthesised. This latency limits the suitability of such models for time-sensitive tasks like simultaneous interpretation. Interleaving the action of reading a character with that of synthesising audio reduces this latency. However, the order of this sequence of interleaved actions varies across sentences, which raises the question of how the actions should be chosen. We propose a reinforcement learning based framework to train an agent to make this decision. We compare our performance against that of deterministic, rule-based systems. Our results demonstrate that our agent successfully balances the trade-off between the latency of audio generation and the quality of synthesised audio. More broadly, we show that neural sequence-to-sequence models can be adapted to run in an incremental manner.