 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Use of Yannakakis' Algorithm to Improve Query Performance: Machine Learning to the Rescue
Feb 27, 2025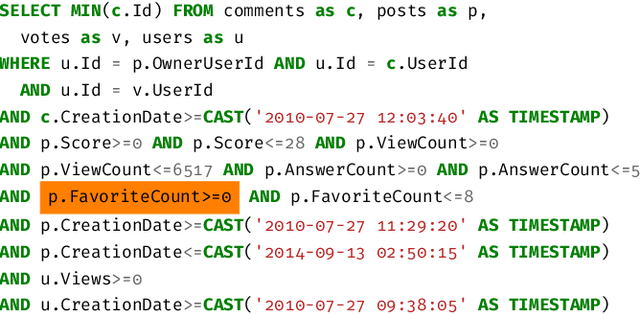
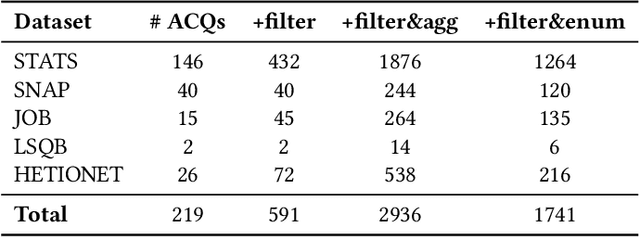

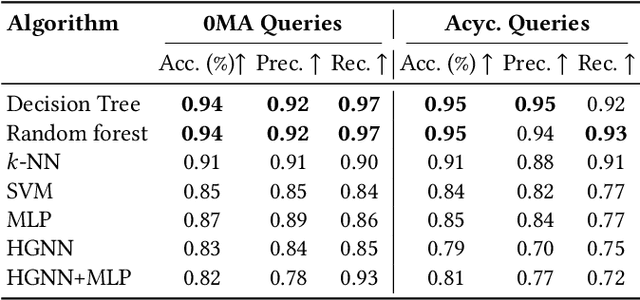
Query optimization has played a central role in database research for decades. However, more often than not, the proposed optimization techniques lead to a performance improvement in some, but not in all, situations. Therefore, we urgently need a methodology for designing a decision procedure that decides for a given query whether the optimization technique should be applied or not. In this work, we propose such a methodology with a focus on Yannakakis-style query evaluation as our optimization technique of interest. More specifically, we formulate this decision problem as an algorithm selection problem and we present a Machine Learning based approach for its solution. Empirical results with several benchmarks on a variety of database systems show that our approach indeed leads to a statistically significant performance improvement.
Fuzzy Datalog$^\exists$ over Arbitrary t-Norms
Mar 05, 2024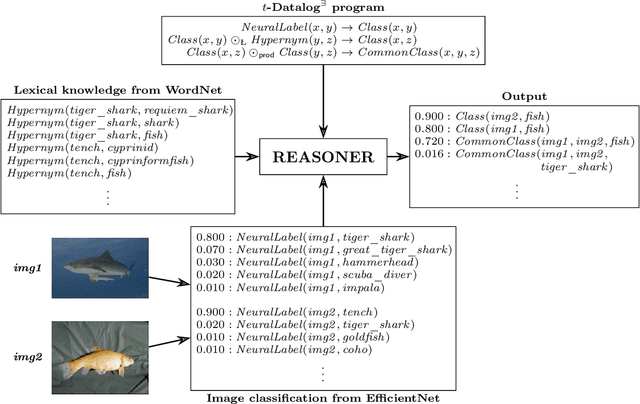
One of the main challenges in the area of Neuro-Symbolic AI is to perform logical reasoning in the presence of both neural and symbolic data. This requires combining heterogeneous data sources such as knowledge graphs, neural model predictions, structured databases, crowd-sourced data, and many more. To allow for such reasoning, we generalise the standard rule-based language Datalog with existential rules (commonly referred to as tuple-generating dependencies) to the fuzzy setting, by allowing for arbitrary t-norms in the place of classical conjunctions in rule bodies. The resulting formalism allows us to perform reasoning about data associated with degrees of uncertainty while preserving computational complexity results and the applicability of reasoning techniques established for the standard Datalog setting. In particular, we provide fuzzy extensions of Datalog chases which produce fuzzy universal models and we exploit them to show that in important fragments of the language, reasoning has the same complexity as in the classical setting.
Selective Forgetting: Advancing Machine Unlearning Techniques and Evaluation in Language Models
Feb 08, 2024



The aim of this study is to investigate Machine Unlearning (MU), a burgeoning field focused on addressing concerns related to neural models inadvertently retaining personal or sensitive data. Here, a novel approach is introduced to achieve precise and selective forgetting within language models. Unlike previous methodologies that adopt completely opposing training objectives, this approach aims to mitigate adverse effects on language model performance, particularly in generation tasks. Furthermore, two innovative evaluation metrics are proposed: Sensitive Information Extraction Likelihood (S-EL) and Sensitive Information Memory Accuracy (S-MA), designed to gauge the effectiveness of sensitive information elimination. To reinforce the forgetting framework, an effective method for annotating sensitive scopes is presented, involving both online and offline strategies. The online selection mechanism leverages language probability scores to ensure computational efficiency, while the offline annotation entails a robust two-stage process based on Large Language Models (LLMs).
Incremental Updates of Generalized Hypertree Decompositions
Sep 21, 2022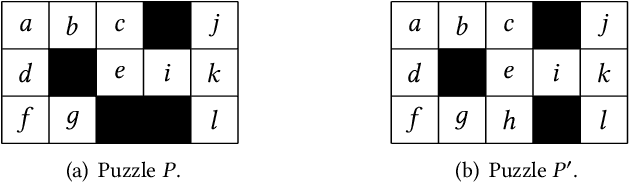
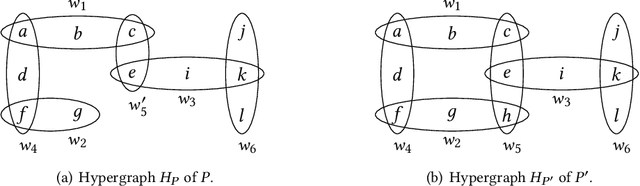

Structural decomposition methods, such as generalized hypertree decompositions, have been successfully used for solving constraint satisfaction problems (CSPs). As decompositions can be reused to solve CSPs with the same constraint scopes, investing resources in computing good decompositions is beneficial, even though the computation itself is hard. Unfortunately, current methods need to compute a completely new decomposition even if the scopes change only slightly. In this paper, we make the first steps toward solving the problem of updating the decomposition of a CSP $P$ so that it becomes a valid decomposition of a new CSP $P'$ produced by some modification of $P$. Even though the problem is hard in theory, we propose and implement a framework for effectively updating GHDs. The experimental evaluation of our algorithm strongly suggests practical applicability.
Non-Uniformly Terminating Chase: Size and Complexity
Apr 26, 2022The chase procedure, originally introduced for checking implication of database constraints, and later on used for computing data exchange solutions, has recently become a central algorithmic tool in rule-based ontological reasoning. In this context, a key problem is non-uniform chase termination: does the chase of a database w.r.t. a rule-based ontology terminate? And if this is the case, what is the size of the result of the chase? We focus on guarded tuple-generating dependencies (TGDs), which form a robust rule-based ontology language, and study the above central questions for the semi-oblivious version of the chase. One of our main findings is that non-uniform semi-oblivious chase termination for guarded TGDs is feasible in polynomial time w.r.t. the database, and the size of the result of the chase (whenever is finite) is linear w.r.t. the database. Towards our results concerning non-uniform chase termination, we show that basic techniques such as simplification and linearization, originally introduced in the context of ontological query answering, can be safely applied to the chase termination problem.
On the Complexity of Inductively Learning Guarded Rules
Oct 07, 2021We investigate the computational complexity of mining guarded clauses from clausal datasets through the framework of inductive logic programming (ILP). We show that learning guarded clauses is NP-complete and thus one step below the $\sigma^P_2$-complete task of learning Horn clauses on the polynomial hierarchy. Motivated by practical applications on large datasets we identify a natural tractable fragment of the problem. Finally, we also generalise all of our results to $k$-guarded clauses for constant $k$.
The HyperTrac Project: Recent Progress and Future Research Directions on Hypergraph Decompositions
Dec 29, 2020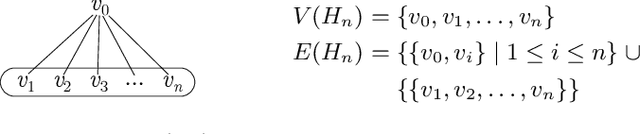

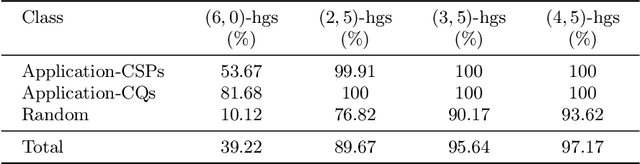

Constraint Satisfaction Problems (CSPs) play a central role in many applications in Artificial Intelligence and Operations Research. In general, solving CSPs is NP-complete. The structure of CSPs is best described by hypergraphs. Therefore, various forms of hypergraph decompositions have been proposed in the literature to identify tractable fragments of CSPs. However, also the computation of a concrete hypergraph decomposition is a challenging task in itself. In this paper, we report on recent progress in the study of hypergraph decompositions and we outline several directions for future research.
HyperBench: A Benchmark and Tool for Hypergraphs and Empirical Findings
Sep 02, 2020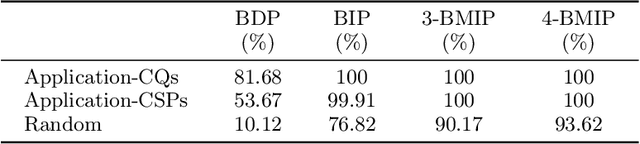
To cope with the intractability of answering Conjunctive Queries (CQs) and solving Constraint Satisfaction Problems (CSPs), several notions of hypergraph decompositions have been proposed -- giving rise to different notions of width, noticeably, plain, generalized, and fractional hypertree width (hw, ghw, and fhw). Given the increasing interest in using such decomposition methods in practice, a publicly accessible repository of decomposition software, as well as a large set of benchmarks, and a web-accessible workbench for inserting, analyzing, and retrieving hypergraphs are called for. We address this need by providing (i) concrete implementations of hypergraph decompositions (including new practical algorithms), (ii) a new, comprehensive benchmark of hypergraphs stemming from disparate CQ and CSP collections, and (iii) HyperBench, our new web-inter\-face for accessing the benchmark and the results of our analyses. In addition, we describe a number of actual experiments we carried out with this new infrastructure.
The Space-Efficient Core of Vadalog
Sep 16, 2018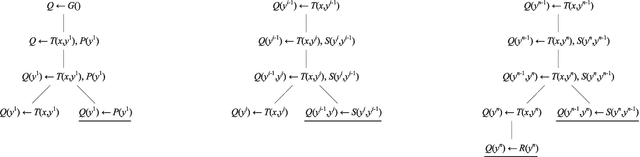
Vadalog is a system for performing complex reasoning tasks such as those required in advanced knowledge graphs. The logical core of the underlying Vadalog language is the warded fragment of tuple-generating dependencies (TGDs). This formalism ensures tractable reasoning in data complexity, while a recent analysis focusing on a practical implementation led to the reasoning algorithm around which the Vadalog system is built. A fundamental question that has emerged in the context of Vadalog is the following: can we limit the recursion allowed by wardedness in order to obtain a formalism that provides a convenient syntax for expressing useful recursive statements, and at the same time achieves space-efficiency? After analyzing several real-life examples of warded sets of TGDs provided by our industrial partners, as well as recent benchmarks, we observed that recursion is often used in a restricted way: the body of a TGD contains at most one atom whose predicate is mutually recursive with a predicate in the head. We show that this type of recursion, known as piece-wise linear in the Datalog literature, is the answer to our main question. We further show that piece-wise linear recursion alone, without the wardedness condition, is not enough as it leads to the undecidability of reasoning. We finally study the relative expressiveness of the query languages based on (piece-wise linear) warded sets of TGDs.
Datalog: Bag Semantics via Set Semantics
Jul 25, 2018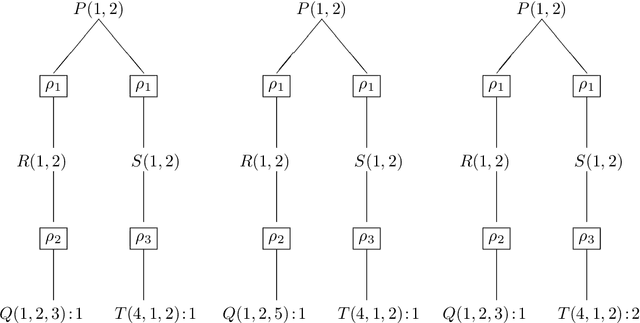
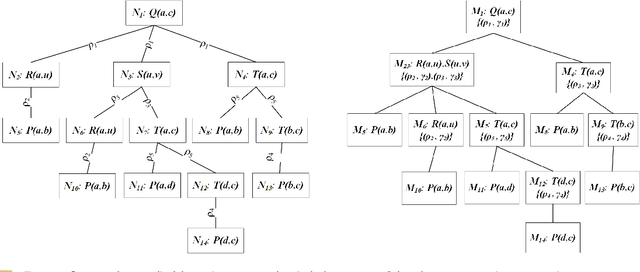
Duplicates in data management are common and problematic. In this work, we present a translation of Datalog under bag semantics into a well-behaved extension of Datalog (the so-called warded Datalog+-) under set semantics. From a theoretical point of view, this allows us to reason on bag semantics by making use of the well-established theoretical foundations of set semantics. From a practical point of view, this allows us to handle the bag semantics of Datalog by powerful, existing query engines for the required extension of Datalog. Moreover, this translation has the potential for further extensions -- above all to capture the bag semantics of the semantic web query language SPARQL.