 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposition of Nondeterministic and Stochastic Services for LTLf Task Specifications
Nov 29, 2023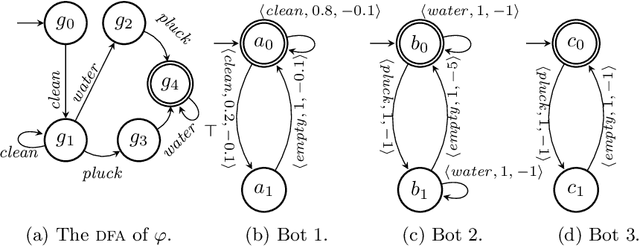
In this paper, we study the composition of services so as to obtain runs satisfying a task specification in Linear Temporal Logic on finite traces (LTLf). We study the problem in the case services are nondeterministic and the LTLf specification can be exactly met, and in the case services are stochastic, where we are interested in maximizing the probability of satisfaction of the LTLf specification and, simultaneously, minimizing the utilization cost of the services. To do so, we combine techniques from LTLf synthesis, service composition \`a la Roman Model, reactive synthesis, and bi-objective lexicographic optimization on MDPs. This framework has several interesting applications, including Smart Manufacturing and Digital Twins.
Ontological Reasoning over Shy and Warded Datalog$+/-$ for Streaming-based Architectures (technical report)
Nov 20, 2023



Recent years witnessed a rising interest towards Datalog-based ontological reasoning systems, both in academia and industry. These systems adopt languages, often shared under the collective name of Datalog$+/-$, that extend Datalog with the essential feature of existential quantification, while introducing syntactic limitations to sustain reasoning decidability and achieve a good trade-off between expressive power and computational complexity. From an implementation perspective, modern reasoners borrow the vast experience of the database community in developing streaming-based data processing systems, such as volcano-iterator architectures, that sustain a limited memory footprint and good scalability. In this paper, we focus on two extremely promising, expressive, and tractable languages, namely, Shy and Warded Datalog$+/-$. We leverage their theoretical underpinnings to introduce novel reasoning techniques, technically, "chase variants", that are particularly fit for efficient reasoning in streaming-based architectures. We then implement them in Vadalog, our reference streaming-based engine, to efficiently solve ontological reasoning tasks over real-world settings.
Exploiting Multiple Abstractions in Episodic RL via Reward Shaping
Feb 28, 2023



One major limitation to the applicability of Reinforcement Learning (RL) to many practical domains is the large number of samples required to learn an optimal policy. To address this problem and improve learning efficiency, we consider a linear hierarchy of abstraction layers of the Markov Decision Process (MDP) underlying the target domain. Each layer is an MDP representing a coarser model of the one immediately below in the hierarchy. In this work, we propose a novel form of Reward Shaping where the solution obtained at the abstract level is used to offer rewards to the more concrete MDP, in such a way that the abstract solution guides the learning in the more complex domain. In contrast with other works in Hierarchical RL, our technique has few requirements in the design of the abstract models and it is also tolerant to modeling errors, thus making the proposed approach practical. We formally analyze the relationship between the abstract models and the exploration heuristic induced in the lower-level domain. Moreover, we prove that the method guarantees optimal convergence and we demonstrate its effectiveness experimentally.
Forward LTLf Synthesis: DPLL At Work
Feb 27, 2023This paper proposes a new AND-OR graph search framework for synthesis of Linear Temporal Logic on finite traces (LTLf), that overcomes some limitations of previous approaches. Within such framework, I devise a procedure inspired by the Davis-Putnam-Logemann-Loveland (DPLL) algorithm to generate the next available agent-environment moves in a truly depth-first fashion, possibly avoiding exhaustive enumeration or costly compilations. I also propose a novel equivalence check for search nodes based on syntactic equivalence of state formulas. Since the resulting procedure is not guaranteed to terminate, I identify a stopping condition to abort execution and restart the search with state-equivalence checking based on Binary Decision Diagrams (BDD), which I show to be correct. The experimental results show that in many cases the proposed techniques outperform other state-of-the-art approaches.
Combining search strategies to improve performance in the calibration of economic ABMs
Feb 23, 2023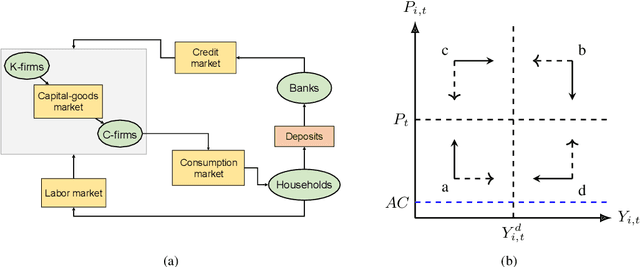

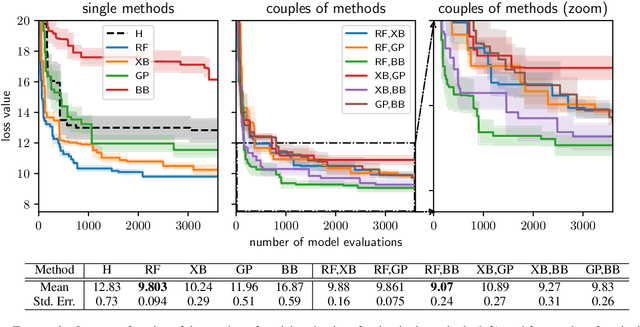
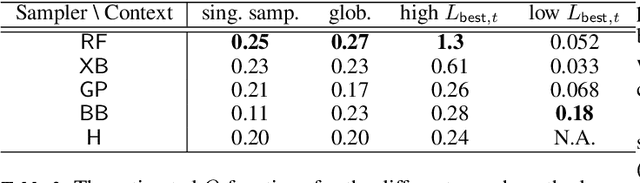
Calibrating agent-based models (ABMs) in economics and finance typically involves a derivative-free search in a very large parameter space. In this work, we benchmark a number of search methods in the calibration of a well-known macroeconomic ABM on real data, and further assess the performance of "mixed strategies" made by combining different methods. We find that methods based on random-forest surrogates are particularly efficient, and that combining search methods generally increases performance since the biases of any single method are mitigated. Moving from these observations, we propose a reinforcement learning (RL) scheme to automatically select and combine search methods on-the-fly during a calibration run. The RL agent keeps exploiting a specific method only as long as this keeps performing well, but explores new strategies when the specific method reaches a performance plateau. The resulting RL search scheme outperforms any other method or method combination tested, and does not rely on any prior information or trial and error procedure.
Planning for Temporally Extended Goals in Pure-Past Linear Temporal Logic: A Polynomial Reduction to Standard Planning
Apr 22, 2022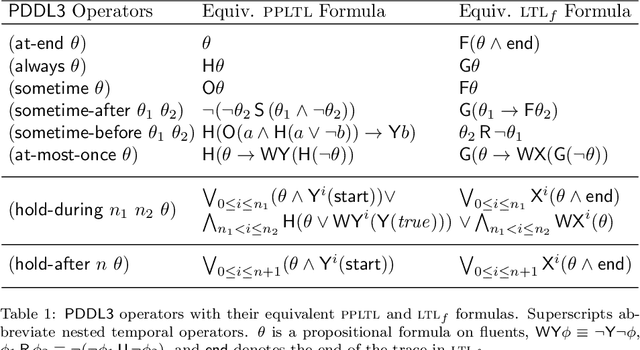
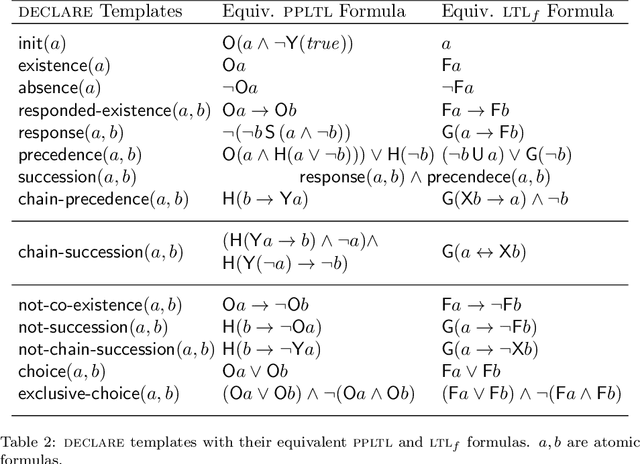
We study temporally extended goals expressed in Pure-Past LTL (PPLTL). PPLTL is particularly interesting for expressing goals since it allows to express sophisticated tasks as in the Formal Methods literature, while the worst-case computational complexity of Planning in both deterministic and nondeterministic domains (FOND) remains the same as for classical reachability goals. However, while the theory of planning for PPLTL goals is well understood, practical tools have not been specifically investigated. In this paper, we make a significant leap forward in the construction of actual tools to handle PPLTL goals. We devise a technique to polynomially translate planning for PPLTL goals into standard planning. We show the formal correctness of the translation, its complexity, and its practical effectiveness through some comparative experiments. As a result, our translation enables state-of-the-art tools, such as FD or MyND, to handle PPLTL goals seamlessly, maintaining the impressive performances they have for classical reachability goals.
On the Relationship between Shy and Warded Datalog+/-
Feb 13, 2022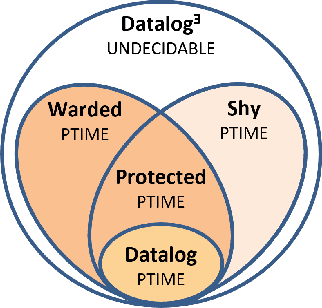
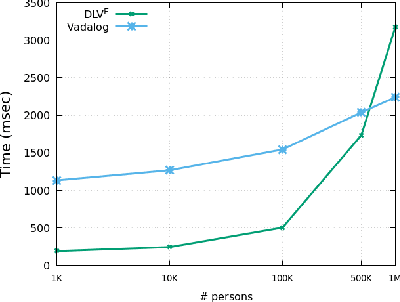
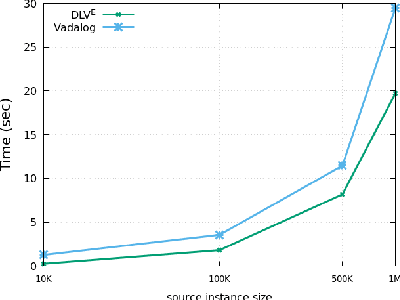
Datalog^E is the extension of Datalog with existential quantification. While its high expressive power, underpinned by a simple syntax and the support for full recursion, renders it particularly suitable for modern applications on knowledge graphs, query answering (QA) over such language is known to be undecidable in general. For this reason, different fragments have emerged, introducing syntactic limitations to Datalog^E that strike a balance between its expressive power and the computational complexity of QA, to achieve decidability. In this short paper, we focus on two promising tractable candidates, namely Shy and Warded Datalog+/-. Reacting to an explicit interest from the community, we shed light on the relationship between these fragments. Moreover, we carry out an experimental analysis of the systems implementing Shy and Warded, respectively DLV^E and Vadalog.
Reinforcement Learning for LTLf/LDLf Goals
Jul 17, 2018



MDPs extended with LTLf/LDLf non-Markovian rewards have recently attracted interest as a way to specify rewards declaratively. In this paper, we discuss how a reinforcement learning agent can learn policies fulfilling LTLf/LDLf goals. In particular we focus on the case where we have two separate representations of the world: one for the agent, using the (predefined, possibly low-level) features available to it, and one for the goal, expressed in terms of high-level (human-understandable) fluents. We formally define the problem and show how it can be solved. Moreover, we provide experimental evidence that keeping the RL agent feature space separated from the goal's can work in practice, showing interesting cases where the agent can indeed learn a policy that fulfills the LTLf/LDLf goal using only its features (augmented with additional memory).