 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Injection of LTLf Constraints in Autoregressive Reinforcement Learning Policies
Jun 06, 2026In this work we study offline reinforcement learning (RL) under temporally extended task constraints expressed in Linear Temporal Logic over finite traces (LTLf). Recently, transformer-based approaches such as Trajectory Transformers and Decision Transformers have been adopted to address RL as a sequence modeling problem. However, these methods optimize purely for reward and do not account for high-level temporal requirements. Here, we introduce a neurosymbolic framework that injects LTLf background knowledge into such transformer-based RL policies. Our approach compiles LTLf formulas into deterministic finite automata (DFAs) and integrates them into the learning process through a differentiable representation and a logic-based loss function. In particular, we derive differentiable satisfaction signals from DFA progression and use them as a regularization term during training. The resulting method is architecture-agnostic across different models. We evaluate the proposed framework on navigation environments with specification suites covering combinations of safety and reachability temporal properties. Experimental results show that incorporating background knowledge not only improves constraint satisfaction, but also maintains competitive return compared to vanilla baselines.
Incremental LTLf Synthesis
Mar 01, 2026In this paper, we study incremental LTLf synthesis -- a form of reactive synthesis where the goals are given incrementally while in execution. In other words, the protagonist agent is already executing a strategy for a certain goal when it receives a new goal: at this point, the agent has to abandon the current strategy and synthesize a new strategy still fulfilling the original goal, which was given at the beginning, as well as the new goal, starting from the current instant. In this paper, we formally define the problem of incremental synthesis and study its solution. We propose a solution technique that efficiently performs incremental synthesis for multiple LTLf goals by leveraging auxiliary data structures constructed during automata-based synthesis. We also consider an alternative solution technique based on LTLf formula progression. We show that, in spite of the fact that formula progression can generate formulas that are exponentially larger than the original ones, their minimal automata remain bounded in size by that of the original formula. On the other hand, we show experimentally that, if implemented naively, i.e., by actually computing the automaton of the progressed LTLf formulas from scratch every time a new goal arrives, the solution based on formula progression is not competitive.
Optimal Alignment of Temporal Knowledge Bases
Jul 28, 2023Answering temporal CQs over temporalized Description Logic knowledge bases (TKB) is a main technique to realize ontology-based situation recognition. In case the collected data in such a knowledge base is inaccurate, important query answers can be missed. In this paper we introduce the TKB Alignment problem, which computes a variant of the TKB that minimally changes the TKB, but entails the given temporal CQ and is in that sense (cost-)optimal. We investigate this problem for ALC TKBs and conjunctive queries with LTL operators and devise a solution technique to compute (cost-optimal) alignments of TKBs that extends techniques for the alignment problem for propositional LTL over finite traces.
Exploiting Multiple Abstractions in Episodic RL via Reward Shaping
Feb 28, 2023



One major limitation to the applicability of Reinforcement Learning (RL) to many practical domains is the large number of samples required to learn an optimal policy. To address this problem and improve learning efficiency, we consider a linear hierarchy of abstraction layers of the Markov Decision Process (MDP) underlying the target domain. Each layer is an MDP representing a coarser model of the one immediately below in the hierarchy. In this work, we propose a novel form of Reward Shaping where the solution obtained at the abstract level is used to offer rewards to the more concrete MDP, in such a way that the abstract solution guides the learning in the more complex domain. In contrast with other works in Hierarchical RL, our technique has few requirements in the design of the abstract models and it is also tolerant to modeling errors, thus making the proposed approach practical. We formally analyze the relationship between the abstract models and the exploration heuristic induced in the lower-level domain. Moreover, we prove that the method guarantees optimal convergence and we demonstrate its effectiveness experimentally.
Mimicking Behaviors in Separated Domains
May 18, 2022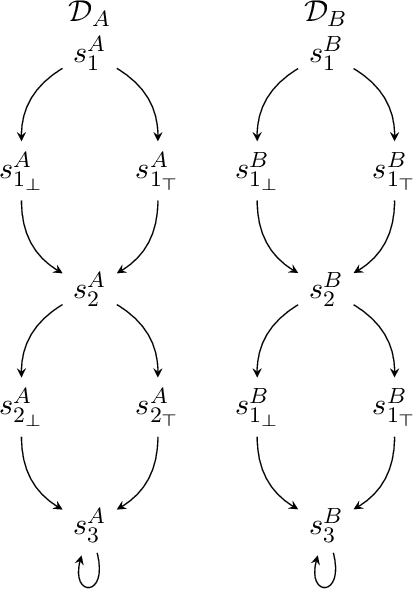
Devising a strategy to make a system mimicking behaviors from another system is a problem that naturally arises in many areas of Computer Science. In this work, we interpret this problem in the context of intelligent agents, from the perspective of LTLf, a formalism commonly used in AI for expressing finite-trace properties. Our model consists of two separated dynamic domains, D_A and D_B, and an LTLf specification that formalizes the notion of mimicking by mapping properties on behaviors (traces) of D_A into properties on behaviors of D_B. The goal is to synthesize a strategy that step-by-step maps every behavior of D_A into a behavior of D_B so that the specification is met. We consider several forms of mapping specifications, ranging from simple ones to full LTLf, and for each we study synthesis algorithms and computational properties.
ASP-Based Declarative Process Mining
May 04, 2022
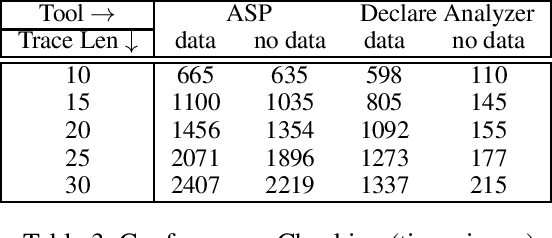
We put forward Answer Set Programming (ASP) as a solution approach for three classical problems in Declarative Process Mining: Log Generation, Query Checking, and Conformance Checking. These problems correspond to different ways of analyzing business processes under execution, starting from sequences of recorded events, a.k.a. event logs. We tackle them in their data-aware variant, i.e., by considering events that carry a payload (set of attribute-value pairs), in addition to the performed activity, specifying processes declaratively with an extension of linear-time temporal logic over finite traces (LTLf). The data-aware setting is significantly more challenging than the control-flow one: Query Checking is still open, while the existing approaches for the other two problems do not scale well. The contributions of the work include an ASP encoding schema for the three problems, their solution, and experiments showing the feasibility of the approach.
Monitoring Hybrid Process Specifications with Conflict Management: The Automata-theoretic Approach
Nov 25, 2021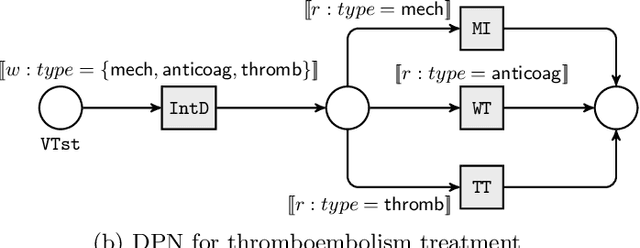
Business process monitoring approaches have thus far mainly focused on monitoring the execution of a process with respect to a single process model. However, in some cases it is necessary to consider multiple process specifications simultaneously. In addition, these specifications can be procedural, declarative, or a combination of both. For example, in the medical domain, a clinical guideline describing the treatment of a specific disease cannot account for all possible co-factors that can coexist for a specific patient and therefore additional constraints may need to be considered. In some cases, these constraints may be incompatible with clinical guidelines, therefore requiring the violation of either the guidelines or the constraints. In this paper, we propose a solution for monitoring the interplay of hybrid process specifications expressed as a combination of (data-aware) Petri nets and temporal logic rules. During the process execution, if these specifications are in conflict with each other, it is possible to violate some of them. The monitoring system is equipped with a violation cost model according to which the system can recommend the next course of actions in a way that would either avoid possible violations or minimize the total cost of violations.
Reinforcement Learning for LTLf/LDLf Goals
Jul 17, 2018



MDPs extended with LTLf/LDLf non-Markovian rewards have recently attracted interest as a way to specify rewards declaratively. In this paper, we discuss how a reinforcement learning agent can learn policies fulfilling LTLf/LDLf goals. In particular we focus on the case where we have two separate representations of the world: one for the agent, using the (predefined, possibly low-level) features available to it, and one for the goal, expressed in terms of high-level (human-understandable) fluents. We formally define the problem and show how it can be solved. Moreover, we provide experimental evidence that keeping the RL agent feature space separated from the goal's can work in practice, showing interesting cases where the agent can indeed learn a policy that fulfills the LTLf/LDLf goal using only its features (augmented with additional memory).
Situation Calculus for Synthesis of Manufacturing Controllers
Jul 12, 2018
Manufacturing is transitioning from a mass production model to a manufacturing as a service model in which manufacturing facilities 'bid' to produce products. To decide whether to bid for a complex, previously unseen product, a manufacturing facility must be able to synthesize, 'on the fly', a process plan controller that delegates abstract manufacturing tasks in the supplied process recipe to the appropriate manufacturing resources, e.g., CNC machines, robots etc. Previous work in applying AI behaviour composition to synthesize process plan controllers has considered only finite state ad-hoc representations. Here, we study the problem in the relational setting of the Situation Calculus. By taking advantage of recent work on abstraction in the Situation Calculus, process recipes and available resources are represented by ConGolog programs over, respectively, an abstract and a concrete action theory. This allows us to capture the problem in a formal, general framework, and show decidability for the case of bounded action theories. We also provide techniques for actually synthesizing the controller.
Specifying Non-Markovian Rewards in MDPs Using LDL on Finite Traces (Preliminary Version)
Jun 25, 2017In Markov Decision Processes (MDPs), the reward obtained in a state depends on the properties of the last state and action. This state dependency makes it difficult to reward more interesting long-term behaviors, such as always closing a door after it has been opened, or providing coffee only following a request. Extending MDPs to handle such non-Markovian reward function was the subject of two previous lines of work, both using variants of LTL to specify the reward function and then compiling the new model back into a Markovian model. Building upon recent progress in the theories of temporal logics over finite traces, we adopt LDLf for specifying non-Markovian rewards and provide an elegant automata construction for building a Markovian model, which extends that of previous work and offers strong minimality and compositionality guarantees.