 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTDRL: Parameter Tuning using Deep Reinforcement Learning
Jun 19, 2023A variety of autonomous navigation algorithms exist that allow robots to move around in a safe and fast manner. However, many of these algorithms require parameter re-tuning when facing new environments. In this paper, we propose PTDRL, a parameter-tuning strategy that adaptively selects from a fixed set of parameters those that maximize the expected reward for a given navigation system. Our learning strategy can be used for different environments, different platforms, and different user preferences. Specifically, we attend to the problem of social navigation in indoor spaces, using a classical motion planning algorithm as our navigation system and training its parameters to optimize its behavior. Experimental results show that PTDRL can outperform other online parameter-tuning strategies.
Specifying Non-Markovian Rewards in MDPs Using LDL on Finite Traces (Preliminary Version)
Jun 25, 2017In Markov Decision Processes (MDPs), the reward obtained in a state depends on the properties of the last state and action. This state dependency makes it difficult to reward more interesting long-term behaviors, such as always closing a door after it has been opened, or providing coffee only following a request. Extending MDPs to handle such non-Markovian reward function was the subject of two previous lines of work, both using variants of LTL to specify the reward function and then compiling the new model back into a Markovian model. Building upon recent progress in the theories of temporal logics over finite traces, we adopt LDLf for specifying non-Markovian rewards and provide an elegant automata construction for building a Markovian model, which extends that of previous work and offers strong minimality and compositionality guarantees.
Distributed Heuristic Forward Search for Multi-Agent Systems
Jun 25, 2013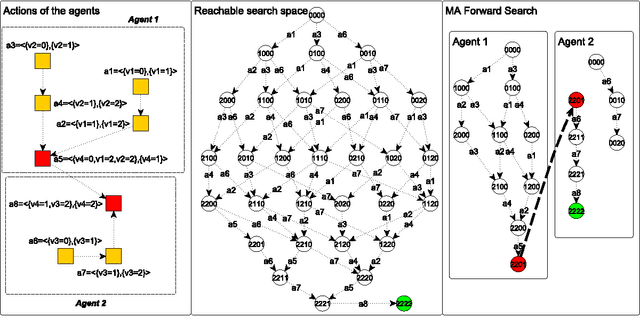
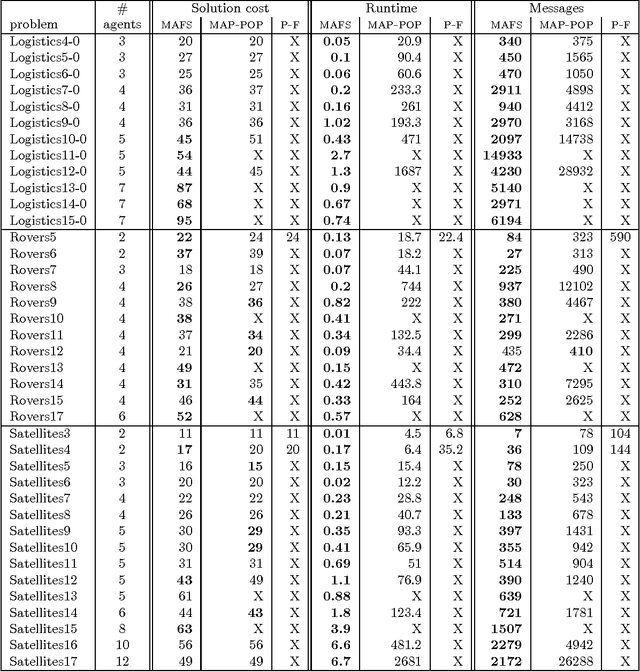
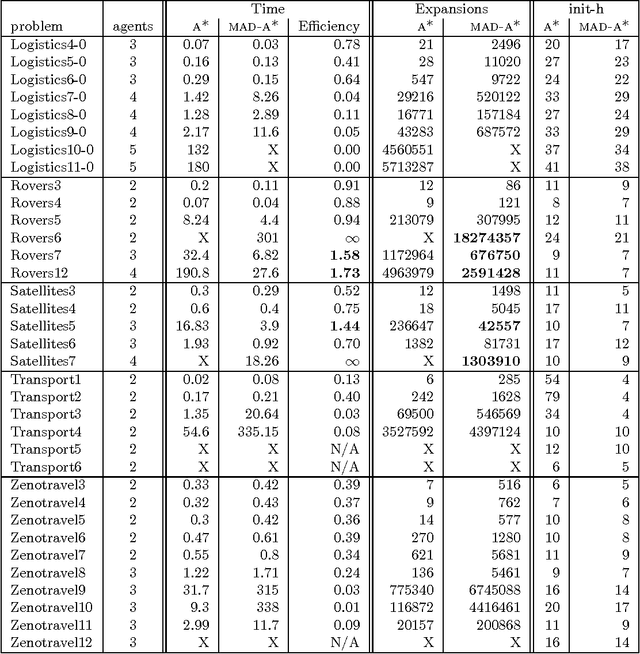
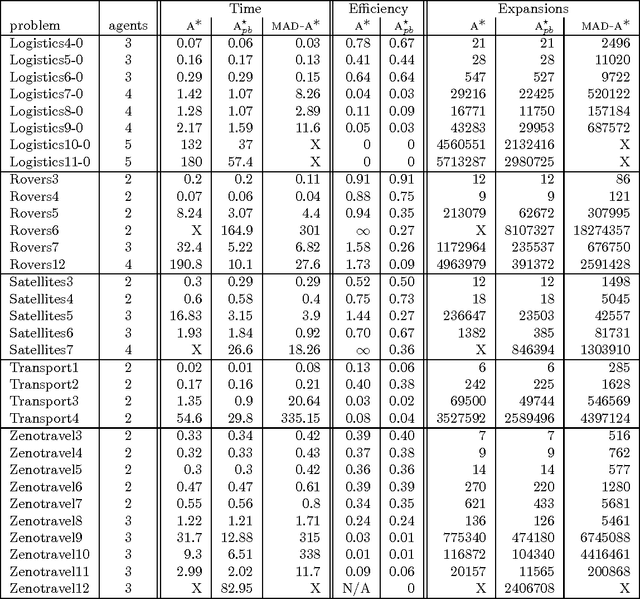
This paper describes a number of distributed forward search algorithms for solving multi-agent planning problems. We introduce a distributed formulation of non-optimal forward search, as well as an optimal version, MAD-A*. Our algorithms exploit the structure of multi-agent problems to not only distribute the work efficiently among different agents, but also to remove symmetries and reduce the overall workload. The algorithms ensure that private information is not shared among agents, yet computation is still efficient -- outperforming current state-of-the-art distributed planners, and in some cases even centralized search -- despite the fact that each agent has access only to partial information.