 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntological Reasoning over Shy and Warded Datalog$+/-$ for Streaming-based Architectures (technical report)
Nov 20, 2023



Recent years witnessed a rising interest towards Datalog-based ontological reasoning systems, both in academia and industry. These systems adopt languages, often shared under the collective name of Datalog$+/-$, that extend Datalog with the essential feature of existential quantification, while introducing syntactic limitations to sustain reasoning decidability and achieve a good trade-off between expressive power and computational complexity. From an implementation perspective, modern reasoners borrow the vast experience of the database community in developing streaming-based data processing systems, such as volcano-iterator architectures, that sustain a limited memory footprint and good scalability. In this paper, we focus on two extremely promising, expressive, and tractable languages, namely, Shy and Warded Datalog$+/-$. We leverage their theoretical underpinnings to introduce novel reasoning techniques, technically, "chase variants", that are particularly fit for efficient reasoning in streaming-based architectures. We then implement them in Vadalog, our reference streaming-based engine, to efficiently solve ontological reasoning tasks over real-world settings.
Fine-tuning Large Enterprise Language Models via Ontological Reasoning
Jun 19, 2023


Large Language Models (LLMs) exploit fine-tuning as a technique to adapt to diverse goals, thanks to task-specific training data. Task specificity should go hand in hand with domain orientation, that is, the specialization of an LLM to accurately address the tasks of a given realm of interest. However, models are usually fine-tuned over publicly available data or, at most, over ground data from databases, ignoring business-level definitions and domain experience. On the other hand, Enterprise Knowledge Graphs (EKGs) are able to capture and augment such domain knowledge via ontological reasoning. With the goal of combining LLM flexibility with the domain orientation of EKGs, we propose a novel neurosymbolic architecture that leverages the power of ontological reasoning to build task- and domain-specific corpora for LLM fine-tuning.
On the Relationship between Shy and Warded Datalog+/-
Feb 13, 2022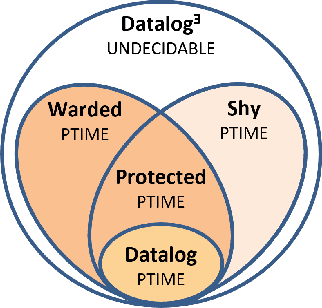
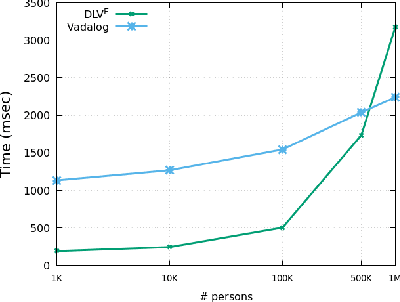
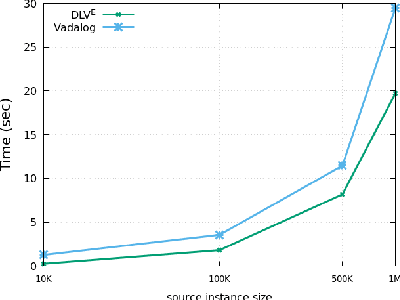
Datalog^E is the extension of Datalog with existential quantification. While its high expressive power, underpinned by a simple syntax and the support for full recursion, renders it particularly suitable for modern applications on knowledge graphs, query answering (QA) over such language is known to be undecidable in general. For this reason, different fragments have emerged, introducing syntactic limitations to Datalog^E that strike a balance between its expressive power and the computational complexity of QA, to achieve decidability. In this short paper, we focus on two promising tractable candidates, namely Shy and Warded Datalog+/-. Reacting to an explicit interest from the community, we shed light on the relationship between these fragments. Moreover, we carry out an experimental analysis of the systems implementing Shy and Warded, respectively DLV^E and Vadalog.
iWarded: A System for Benchmarking Datalog+/- Reasoning (technical report)
Mar 15, 2021
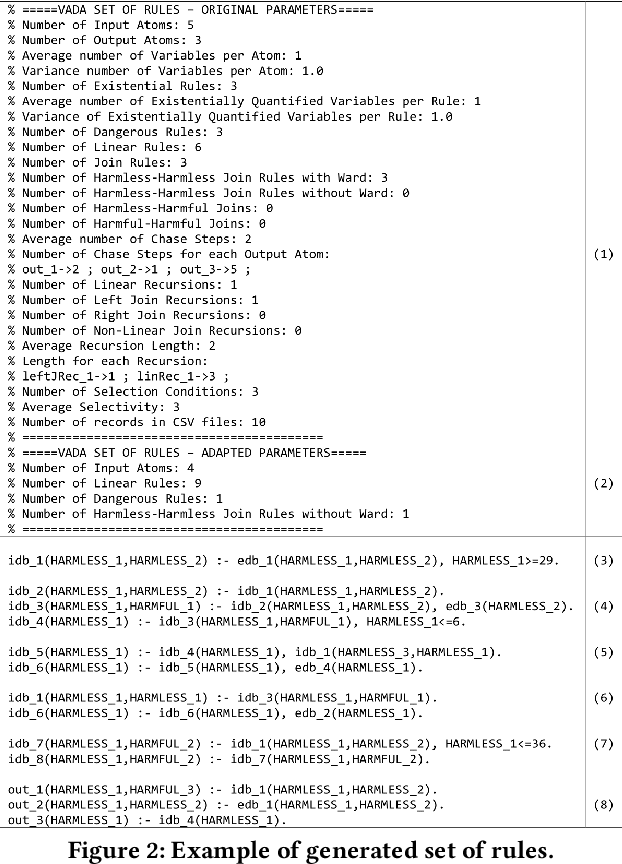


Recent years have seen increasing popularity of logic-based reasoning systems, with research and industrial interest as well as many flourishing applications in the area of Knowledge Graphs. Despite that, one can observe a substantial lack of specific tools able to generate nontrivial reasoning settings and benchmark scenarios. As a consequence, evaluating, analysing and comparing reasoning systems is a complex task, especially when they embody sophisticated optimizations and execution techniques that leverage the theoretical underpinnings of the adopted logic fragment. In this paper, we aim at filling this gap by introducing iWarded, a system that can generate very large, complex, realistic reasoning settings to be used for the benchmarking of logic-based reasoning systems adopting Datalog+/-, a family of extensions of Datalog that has seen a resurgence in the last few years. In particular, iWarded generates reasoning settings for Warded Datalog+/-, a language with a very good tradeoff between computational complexity and expressive power. In the paper, we present the iWarded system and a set of novel theoretical results adopted to generate effective scenarios. As Datalog-based languages are of general interest and see increasing adoption, we believe that iWarded is a step forward in the empirical evaluation of current and future systems.