 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioral Sequence Modeling with Ensemble Learning
Nov 04, 2024



We investigate the use of sequence analysis for behavior modeling, emphasizing that sequential context often outweighs the value of aggregate features in understanding human behavior. We discuss framing common problems in fields like healthcare, finance, and e-commerce as sequence modeling tasks, and address challenges related to constructing coherent sequences from fragmented data and disentangling complex behavior patterns. We present a framework for sequence modeling using Ensembles of Hidden Markov Models, which are lightweight, interpretable, and efficient. Our ensemble-based scoring method enables robust comparison across sequences of different lengths and enhances performance in scenarios with imbalanced or scarce data. The framework scales in real-world scenarios, is compatible with downstream feature-based modeling, and is applicable in both supervised and unsupervised learning settings. We demonstrate the effectiveness of our method with results on a longitudinal human behavior dataset.
Ensemble Methods for Sequence Classification with Hidden Markov Models
Sep 11, 2024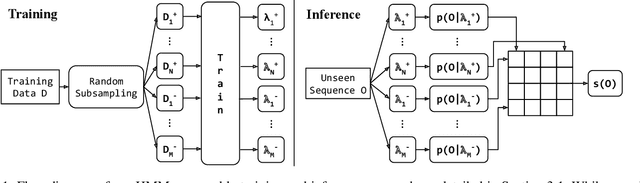


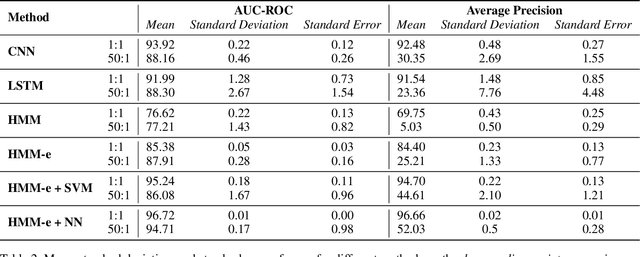
We present a lightweight approach to sequence classification using Ensemble Methods for Hidden Markov Models (HMMs). HMMs offer significant advantages in scenarios with imbalanced or smaller datasets due to their simplicity, interpretability, and efficiency. These models are particularly effective in domains such as finance and biology, where traditional methods struggle with high feature dimensionality and varied sequence lengths. Our ensemble-based scoring method enables the comparison of sequences of any length and improves performance on imbalanced datasets. This study focuses on the binary classification problem, particularly in scenarios with data imbalance, where the negative class is the majority (e.g., normal data) and the positive class is the minority (e.g., anomalous data), often with extreme distribution skews. We propose a novel training approach for HMM Ensembles that generalizes to multi-class problems and supports classification and anomaly detection. Our method fits class-specific groups of diverse models using random data subsets, and compares likelihoods across classes to produce composite scores, achieving high average precisions and AUCs. In addition, we compare our approach with neural network-based methods such as Convolutional Neural Networks (CNNs) and Long Short-Term Memory networks (LSTMs), highlighting the efficiency and robustness of HMMs in data-scarce environments. Motivated by real-world use cases, our method demonstrates robust performance across various benchmarks, offering a flexible framework for diverse applications.
Synthetic Data Applications in Finance
Dec 29, 2023

Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
A Distributed Model-Free Ride-Sharing Approach for Joint Matching, Pricing, and Dispatching using Deep Reinforcement Learning
Oct 05, 2020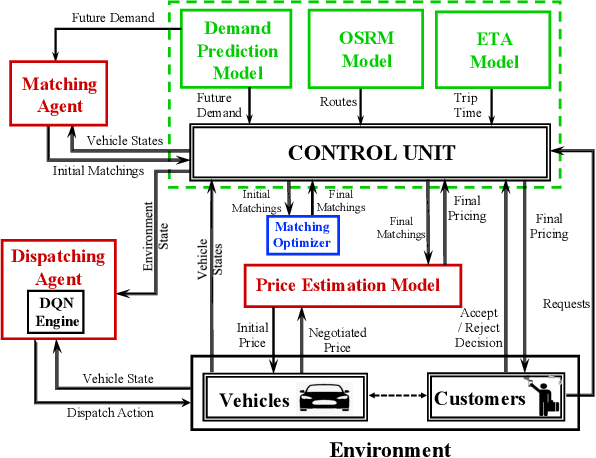
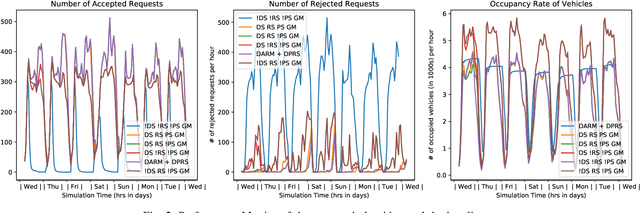
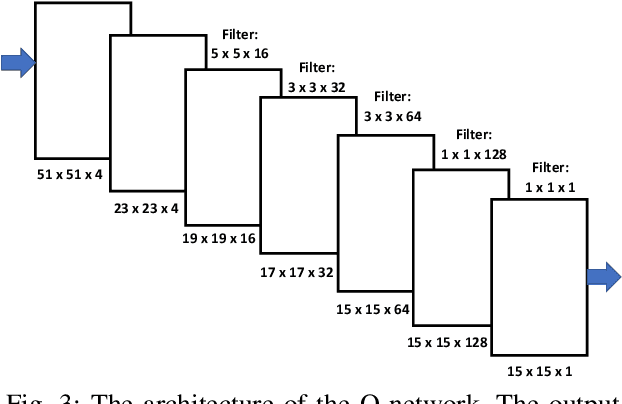
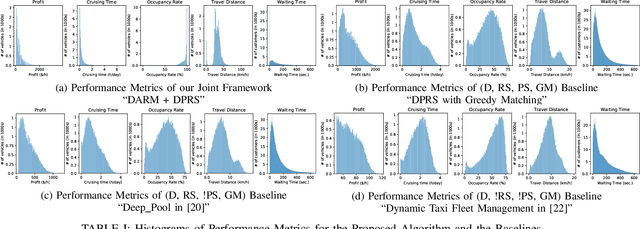
Significant development of ride-sharing services presents a plethora of opportunities to transform urban mobility by providing personalized and convenient transportation while ensuring efficiency of large-scale ride pooling. However, a core problem for such services is route planning for each driver to fulfill the dynamically arriving requests while satisfying given constraints. Current models are mostly limited to static routes with only two rides per vehicle (optimally) or three (with heuristics). In this paper, we present a dynamic, demand aware, and pricing-based vehicle-passenger matching and route planning framework that (1) dynamically generates optimal routes for each vehicle based on online demand, pricing associated with each ride, vehicle capacities and locations. This matching algorithm starts greedily and optimizes over time using an insertion operation, (2) involves drivers in the decision-making process by allowing them to propose a different price based on the expected reward for a particular ride as well as the destination locations for future rides, which is influenced by supply-and demand computed by the Deep Q-network, (3) allows customers to accept or reject rides based on their set of preferences with respect to pricing and delay windows, vehicle type and carpooling preferences, and (4) based on demand prediction, our approach re-balances idle vehicles by dispatching them to the areas of anticipated high demand using deep Reinforcement Learning (RL). Our framework is validated using the New York City Taxi public dataset; however, we consider different vehicle types and designed customer utility functions to validate the setup and study different settings. Experimental results show the effectiveness of our approach in real-time and large scale settings.