 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Deployment Complexity Estimation for Federated Perception Systems
Mar 30, 2026Edge AI systems increasingly rely on federated learning to train perception models in distributed, privacy-preserving, and resource-constrained environments. Yet, before training begins, practitioners often lack practical tools to estimate how difficult a federated learning task will be in terms of achievable accuracy and communication cost. This paper presents a classifier-agnostic, pre-deployment framework for estimating learning complexity in federated perception systems by jointly modeling intrinsic properties of the data and characteristics of the distributed environment. The proposed complexity metric integrates dataset attributes such as dimensionality, sparsity, and heterogeneity with factors related to the composition of participating clients. Using federated learning as a representative distributed training setting, we examine how learning difficulty varies across different federated configurations. Experiments on multiple variants of the MNIST dataset and CIFAR dataset show that the proposed metric strongly correlates with federated learning performance and the communication effort required to reach fixed accuracy targets. These findings suggest that complexity estimation can serve as a practical diagnostic tool for resource planning, dataset assessment, and feasibility evaluation in edge-deployed perception systems.
EMERSK -- Explainable Multimodal Emotion Recognition with Situational Knowledge
Jun 14, 2023Automatic emotion recognition has recently gained significant attention due to the growing popularity of deep learning algorithms. One of the primary challenges in emotion recognition is effectively utilizing the various cues (modalities) available in the data. Another challenge is providing a proper explanation of the outcome of the learning.To address these challenges, we present Explainable Multimodal Emotion Recognition with Situational Knowledge (EMERSK), a generalized and modular system for human emotion recognition and explanation using visual information. Our system can handle multiple modalities, including facial expressions, posture, and gait, in a flexible and modular manner. The network consists of different modules that can be added or removed depending on the available data. We utilize a two-stream network architecture with convolutional neural networks (CNNs) and encoder-decoder style attention mechanisms to extract deep features from face images. Similarly, CNNs and recurrent neural networks (RNNs) with Long Short-term Memory (LSTM) are employed to extract features from posture and gait data. We also incorporate deep features from the background as contextual information for the learning process. The deep features from each module are fused using an early fusion network. Furthermore, we leverage situational knowledge derived from the location type and adjective-noun pair (ANP) extracted from the scene, as well as the spatio-temporal average distribution of emotions, to generate explanations. Ablation studies demonstrate that each sub-network can independently perform emotion recognition, and combining them in a multimodal approach significantly improves overall recognition performance. Extensive experiments conducted on various benchmark datasets, including GroupWalk, validate the superior performance of our approach compared to other state-of-the-art methods.
Continuous Learning Based Novelty Aware Emotion Recognition System
Jun 14, 2023Current works in human emotion recognition follow the traditional closed learning approach governed by rigid rules without any consideration of novelty. Classification models are trained on some collected datasets and expected to have the same data distribution in the real-world deployment. Due to the fluid and constantly changing nature of the world we live in, it is possible to have unexpected and novel sample distribution which can lead the model to fail. Hence, in this work, we propose a continuous learning based approach to deal with novelty in the automatic emotion recognition task.
* Automatic Emotion Detection, Novelty, Deep Learning
SAFER: Situation Aware Facial Emotion Recognition
Jun 14, 2023In this paper, we present SAFER, a novel system for emotion recognition from facial expressions. It employs state-of-the-art deep learning techniques to extract various features from facial images and incorporates contextual information, such as background and location type, to enhance its performance. The system has been designed to operate in an open-world setting, meaning it can adapt to unseen and varied facial expressions, making it suitable for real-world applications. An extensive evaluation of SAFER against existing works in the field demonstrates improved performance, achieving an accuracy of 91.4% on the CAER-S dataset. Additionally, the study investigates the effect of novelty such as face masks during the Covid-19 pandemic on facial emotion recognition and critically examines the limitations of mainstream facial expressions datasets. To address these limitations, a novel dataset for facial emotion recognition is proposed. The proposed dataset and the system are expected to be useful for various applications such as human-computer interaction, security, and surveillance.
AdaPool: A Diurnal-Adaptive Fleet Management Framework using Model-Free Deep Reinforcement Learning and Change Point Detection
Apr 01, 2021
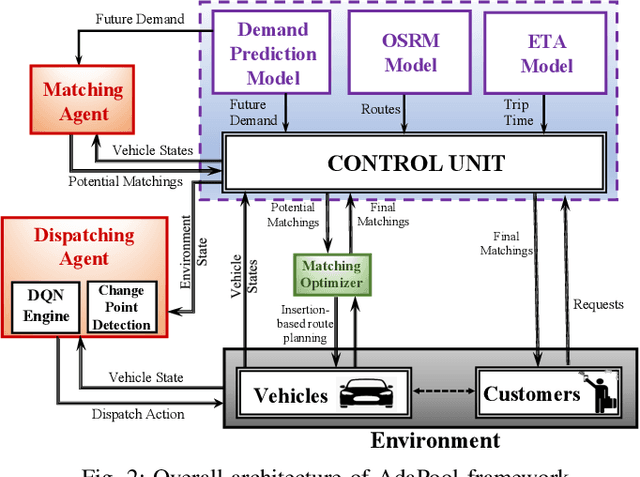
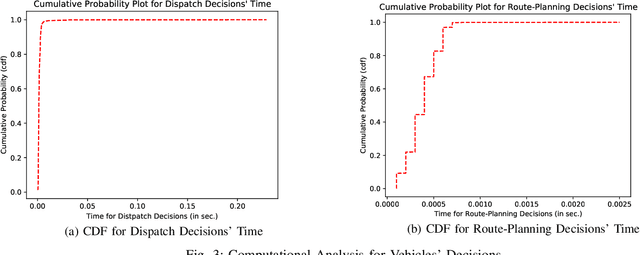
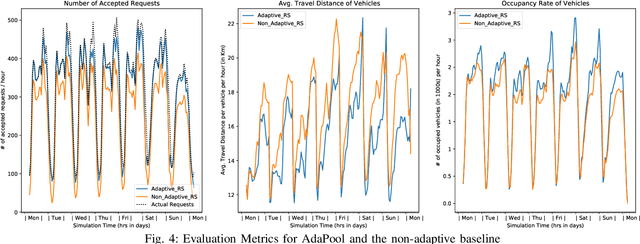
This paper introduces an adaptive model-free deep reinforcement approach that can recognize and adapt to the diurnal patterns in the ride-sharing environment with car-pooling. Deep Reinforcement Learning (RL) suffers from catastrophic forgetting due to being agnostic to the timescale of changes in the distribution of experiences. Although RL algorithms are guaranteed to converge to optimal policies in Markov decision processes (MDPs), this only holds in the presence of static environments. However, this assumption is very restrictive. In many real-world problems like ride-sharing, traffic control, etc., we are dealing with highly dynamic environments, where RL methods yield only sub-optimal decisions. To mitigate this problem in highly dynamic environments, we (1) adopt an online Dirichlet change point detection (ODCP) algorithm to detect the changes in the distribution of experiences, (2) develop a Deep Q Network (DQN) agent that is capable of recognizing diurnal patterns and making informed dispatching decisions according to the changes in the underlying environment. Rather than fixing patterns by time of week, the proposed approach automatically detects that the MDP has changed, and uses the results of the new model. In addition to the adaptation logic in dispatching, this paper also proposes a dynamic, demand-aware vehicle-passenger matching and route planning framework that dynamically generates optimal routes for each vehicle based on online demand, vehicle capacities, and locations. Evaluation on New York City Taxi public dataset shows the effectiveness of our approach in improving the fleet utilization, where less than 50% of the fleet are utilized to serve the demand of up to 90% of the requests, while maximizing profits and minimizing idle times.
Learning Monopoly Gameplay: A Hybrid Model-Free Deep Reinforcement Learning and Imitation Learning Approach
Mar 01, 2021

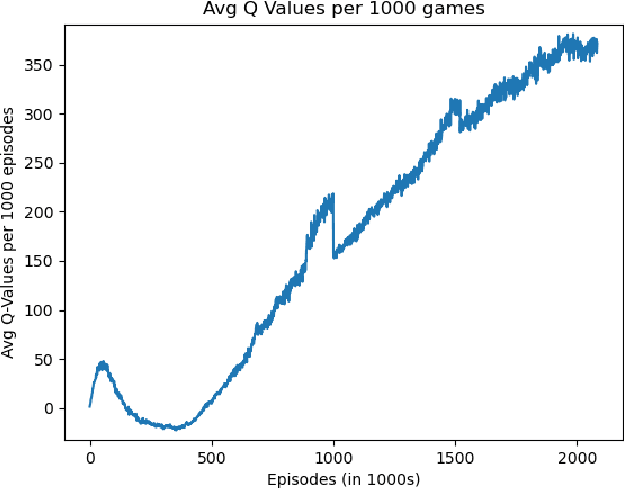
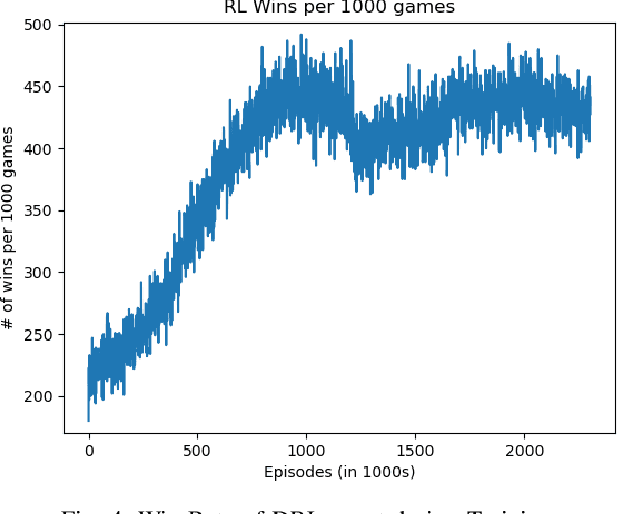
Learning how to adapt and make real-time informed decisions in dynamic and complex environments is a challenging problem. To learn this task, Reinforcement Learning (RL) relies on an agent interacting with an environment and learning through trial and error to maximize the cumulative sum of rewards received by it. In multi-player Monopoly game, players have to make several decisions every turn which involves complex actions, such as making trades. This makes the decision-making harder and thus, introduces a highly complicated task for an RL agent to play and learn its winning strategies. In this paper, we introduce a Hybrid Model-Free Deep RL (DRL) approach that is capable of playing and learning winning strategies of the popular board game, Monopoly. To achieve this, our DRL agent (1) starts its learning process by imitating a rule-based agent (that resembles the human logic) to initialize its policy, (2) learns the successful actions, and improves its policy using DRL. Experimental results demonstrate an intelligent behavior of our proposed agent as it shows high win rates against different types of agent-players.
PassGoodPool: Joint Passengers and Goods Fleet Management with Reinforcement Learning aided Pricing, Matching, and Route Planning
Nov 17, 2020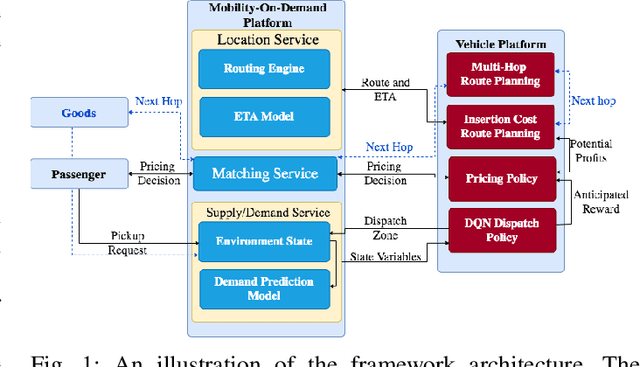
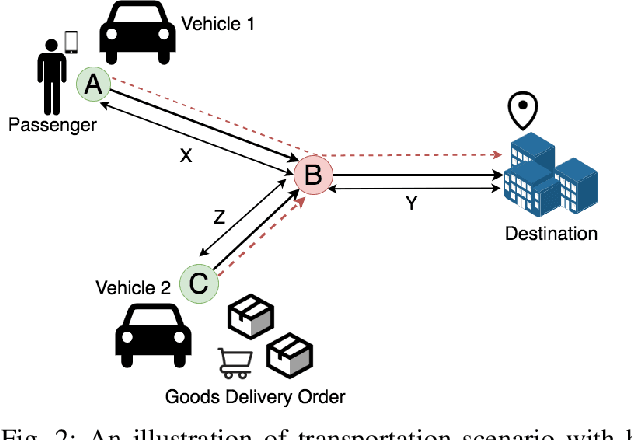
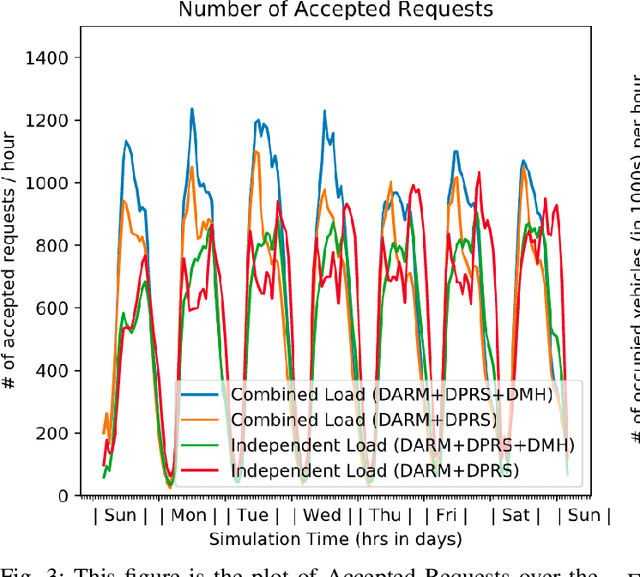
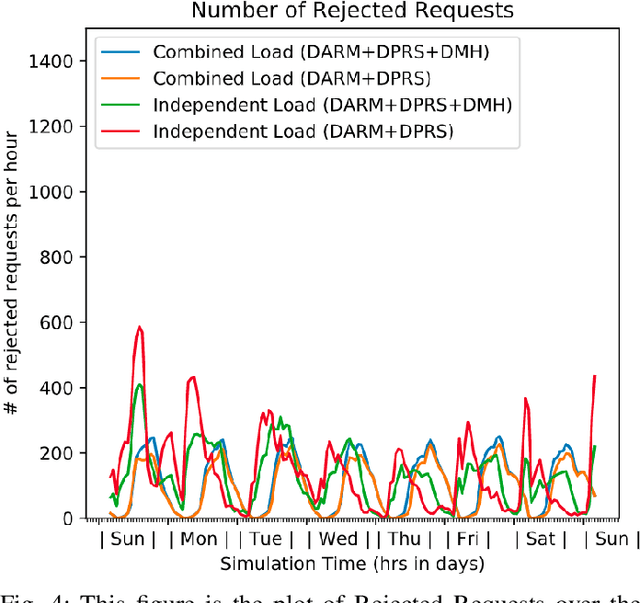
In this paper, we present a dynamic, demand aware, and pricing-based matching and route planning framework that allows efficient pooling of multiple passengers and goods in each vehicle. This approach includes the flexibility for transferring goods through multiple hops from source to destination as well as pooling of passengers. The key components of the proposed approach include (i) Pricing by the vehicles to passengers which is based on the insertion cost, which determines the matching based on passenger's acceptance/rejection, (ii) Matching of goods to vehicles, and the multi-hop routing of goods, (iii) Route planning of the vehicles to pick. up and drop passengers and goods, (i) Dispatching idle vehicles to areas of anticipated high passenger and goods demand using Deep Reinforcement Learning, and (v) Allowing for distributed inference at each vehicle while collectively optimizing fleet objectives. Our proposed framework can be deployed independently within each vehicle as this minimizes computational costs associated with the gorwth of distributed systems and democratizes decision-making to each individual. The proposed framework is validated in a simulated environment, where we leverage realistic delivery datasets such as the New York City Taxi public dataset and Google Maps traffic data from delivery offering businesses.Simulations on a variety of vehicle types, goods, and passenger utility functions show the effectiveness of our approach as compared to baselines that do not consider combined load transportation or dynamic multi-hop route planning. Our proposed method showed improvements over the next best baseline in various aspects including a 15% increase in fleet utilization and 20% increase in average vehicle profits.
A Distributed Model-Free Ride-Sharing Approach for Joint Matching, Pricing, and Dispatching using Deep Reinforcement Learning
Oct 05, 2020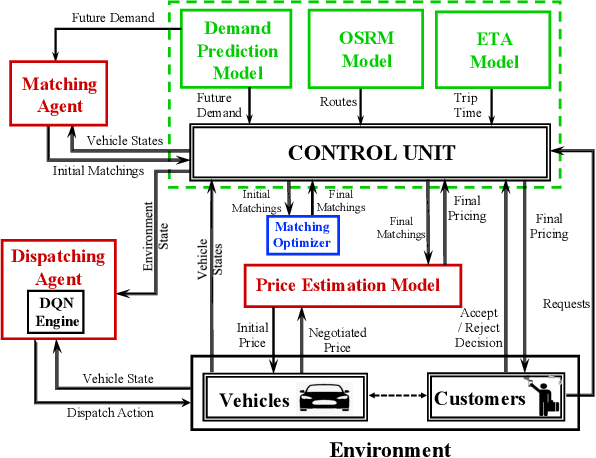
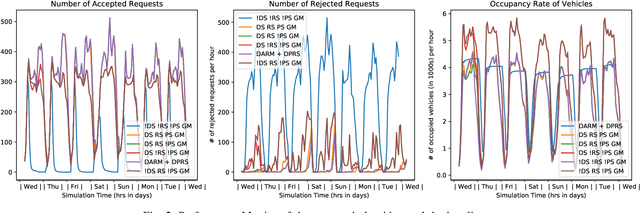
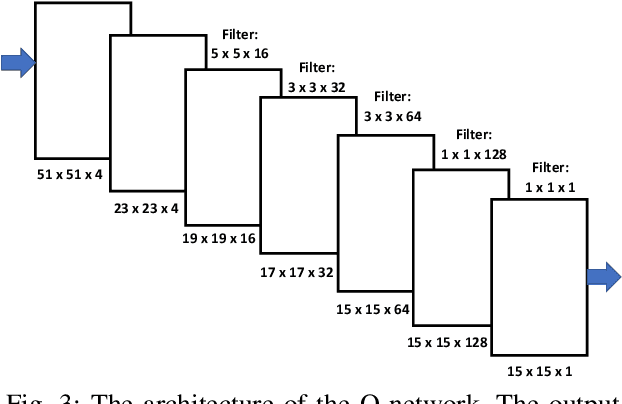
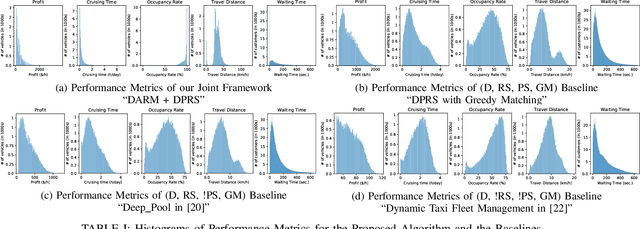
Significant development of ride-sharing services presents a plethora of opportunities to transform urban mobility by providing personalized and convenient transportation while ensuring efficiency of large-scale ride pooling. However, a core problem for such services is route planning for each driver to fulfill the dynamically arriving requests while satisfying given constraints. Current models are mostly limited to static routes with only two rides per vehicle (optimally) or three (with heuristics). In this paper, we present a dynamic, demand aware, and pricing-based vehicle-passenger matching and route planning framework that (1) dynamically generates optimal routes for each vehicle based on online demand, pricing associated with each ride, vehicle capacities and locations. This matching algorithm starts greedily and optimizes over time using an insertion operation, (2) involves drivers in the decision-making process by allowing them to propose a different price based on the expected reward for a particular ride as well as the destination locations for future rides, which is influenced by supply-and demand computed by the Deep Q-network, (3) allows customers to accept or reject rides based on their set of preferences with respect to pricing and delay windows, vehicle type and carpooling preferences, and (4) based on demand prediction, our approach re-balances idle vehicles by dispatching them to the areas of anticipated high demand using deep Reinforcement Learning (RL). Our framework is validated using the New York City Taxi public dataset; however, we consider different vehicle types and designed customer utility functions to validate the setup and study different settings. Experimental results show the effectiveness of our approach in real-time and large scale settings.
ConFoc: Content-Focus Protection Against Trojan Attacks on Neural Networks
Jul 01, 2020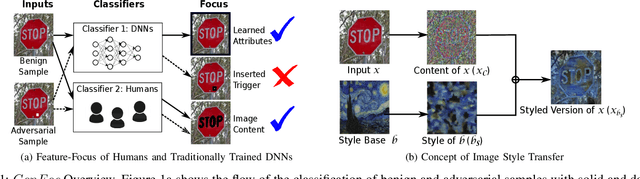
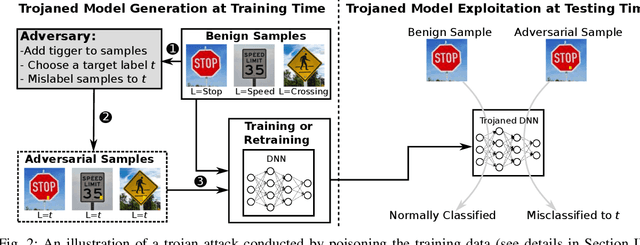
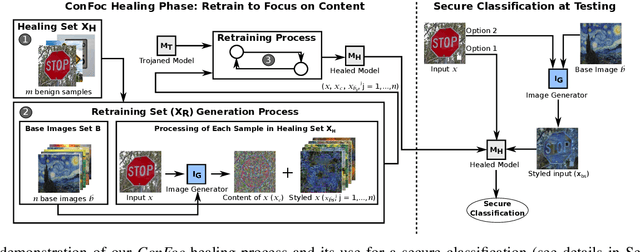
Deep Neural Networks (DNNs) have been applied successfully in computer vision. However, their wide adoption in image-related applications is threatened by their vulnerability to trojan attacks. These attacks insert some misbehavior at training using samples with a mark or trigger, which is exploited at inference or testing time. In this work, we analyze the composition of the features learned by DNNs at training. We identify that they, including those related to the inserted triggers, contain both content (semantic information) and style (texture information), which are recognized as a whole by DNNs at testing time. We then propose a novel defensive technique against trojan attacks, in which DNNs are taught to disregard the styles of inputs and focus on their content only to mitigate the effect of triggers during the classification. The generic applicability of the approach is demonstrated in the context of a traffic sign and a face recognition application. Each of them is exposed to a different attack with a variety of triggers. Results show that the method reduces the attack success rate significantly to values < 1% in all the tested attacks while keeping as well as improving the initial accuracy of the models when processing both benign and adversarial data.