 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConFoc: Content-Focus Protection Against Trojan Attacks on Neural Networks
Jul 01, 2020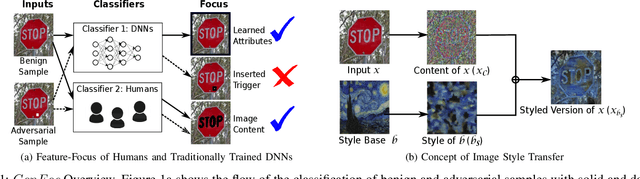
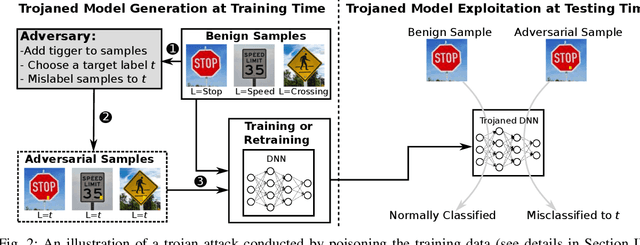
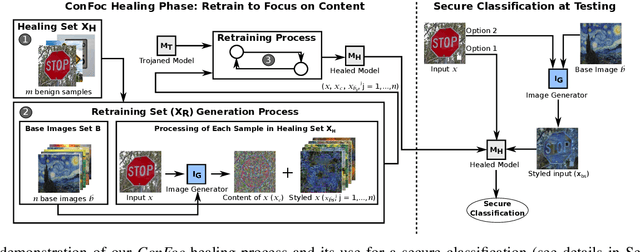
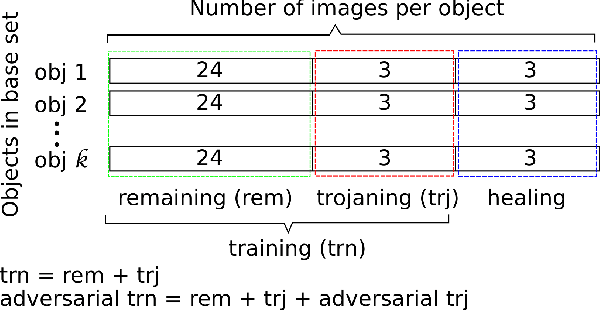
Deep Neural Networks (DNNs) have been applied successfully in computer vision. However, their wide adoption in image-related applications is threatened by their vulnerability to trojan attacks. These attacks insert some misbehavior at training using samples with a mark or trigger, which is exploited at inference or testing time. In this work, we analyze the composition of the features learned by DNNs at training. We identify that they, including those related to the inserted triggers, contain both content (semantic information) and style (texture information), which are recognized as a whole by DNNs at testing time. We then propose a novel defensive technique against trojan attacks, in which DNNs are taught to disregard the styles of inputs and focus on their content only to mitigate the effect of triggers during the classification. The generic applicability of the approach is demonstrated in the context of a traffic sign and a face recognition application. Each of them is exposed to a different attack with a variety of triggers. Results show that the method reduces the attack success rate significantly to values < 1% in all the tested attacks while keeping as well as improving the initial accuracy of the models when processing both benign and adversarial data.