 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-DPO: Vision-Language-Guided Finetuning for Preference-Aligned Autonomous Driving
May 19, 2026The rapid growth of autonomous driving datasets has enabled the scaling of powerful motion forecasting models. While large-scale pretraining provides strong performance, the standard imitation objective may not fully capture the complex nuances of human driving preferences. Meanwhile, recent advances in vision-language models (VLMs) have demonstrated impressive reasoning and commonsense understanding. Building on these capabilities, this paper presents VL-DPO, a vision-language-guided framework that aligns ego-vehicle motion forecasting models with human preferences. Our approach leverages a VLM as a zero-shot reasoner to automatically generate preference pairs from a pretrained model's rollouts, which are then used to finetune the model via Direct Preference Optimization (DPO). We finetune our models on the Waymo Open End-to-End Driving Dataset (WOD-E2E) and evaluate performance against held-out human preference annotations using rater feedback score (RFS) and average displacement error (ADE). Our experiments confirm that the VLM's trajectory selection is a high-quality proxy for human preference. Our final model, VL-DPO, yields an 11.94% increase in RFS and a 10.01% reduction in ADE over the pretrained model.
Multi-agent Deep Covering Option Discovery
Oct 07, 2022
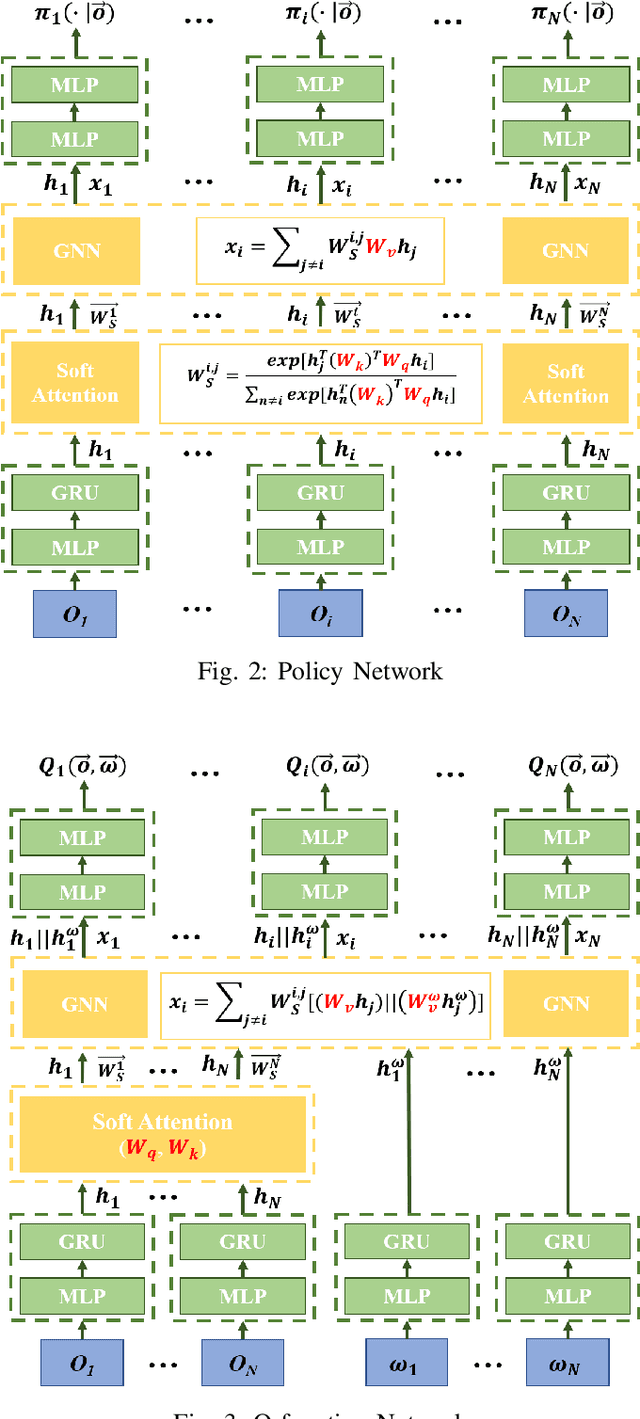

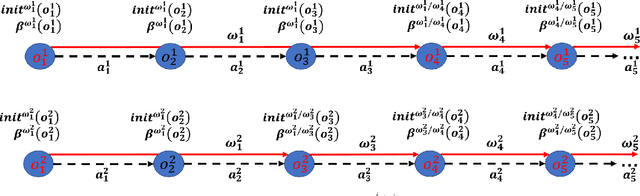
The use of options can greatly accelerate exploration in reinforcement learning, especially when only sparse reward signals are available. While option discovery methods have been proposed for individual agents, in multi-agent reinforcement learning settings, discovering collaborative options that can coordinate the behavior of multiple agents and encourage them to visit the under-explored regions of their joint state space has not been considered. In this case, we propose Multi-agent Deep Covering Option Discovery, which constructs the multi-agent options through minimizing the expected cover time of the multiple agents' joint state space. Also, we propose a novel framework to adopt the multi-agent options in the MARL process. In practice, a multi-agent task can usually be divided into some sub-tasks, each of which can be completed by a sub-group of the agents. Therefore, our algorithm framework first leverages an attention mechanism to find collaborative agent sub-groups that would benefit most from coordinated actions. Then, a hierarchical algorithm, namely HA-MSAC, is developed to learn the multi-agent options for each sub-group to complete their sub-tasks first, and then to integrate them through a high-level policy as the solution of the whole task. This hierarchical option construction allows our framework to strike a balance between scalability and effective collaboration among the agents. The evaluation based on multi-agent collaborative tasks shows that the proposed algorithm can effectively capture the agent interactions with the attention mechanism, successfully identify multi-agent options, and significantly outperforms prior works using single-agent options or no options, in terms of both faster exploration and higher task rewards.
AdaPool: A Diurnal-Adaptive Fleet Management Framework using Model-Free Deep Reinforcement Learning and Change Point Detection
Apr 01, 2021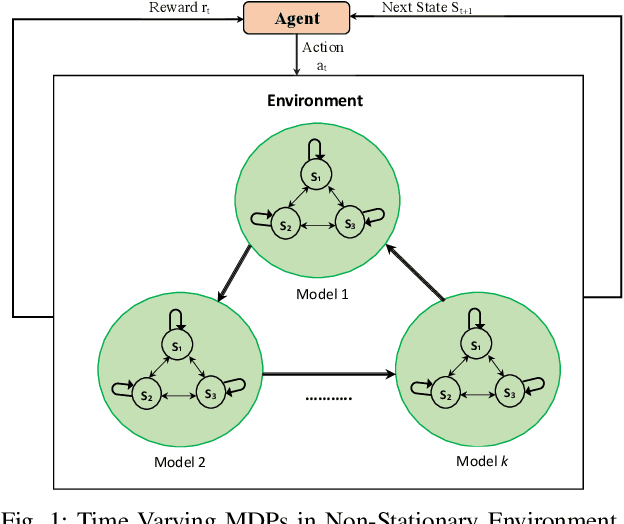
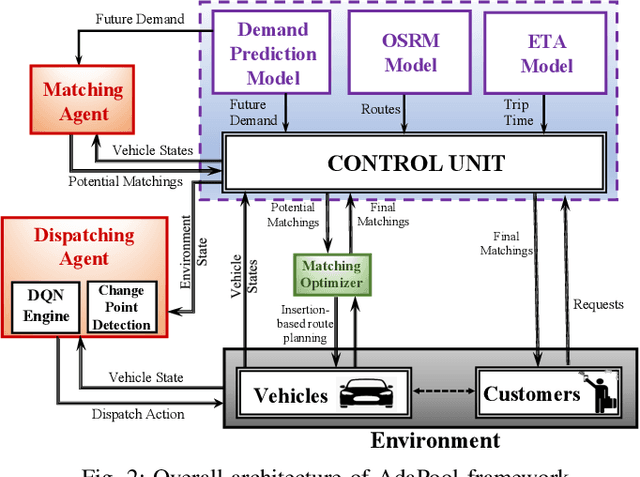
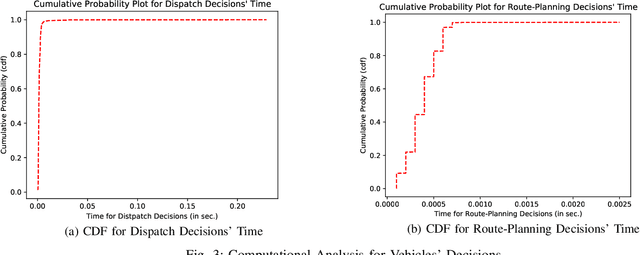
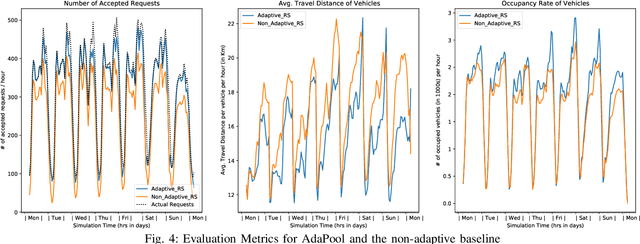
This paper introduces an adaptive model-free deep reinforcement approach that can recognize and adapt to the diurnal patterns in the ride-sharing environment with car-pooling. Deep Reinforcement Learning (RL) suffers from catastrophic forgetting due to being agnostic to the timescale of changes in the distribution of experiences. Although RL algorithms are guaranteed to converge to optimal policies in Markov decision processes (MDPs), this only holds in the presence of static environments. However, this assumption is very restrictive. In many real-world problems like ride-sharing, traffic control, etc., we are dealing with highly dynamic environments, where RL methods yield only sub-optimal decisions. To mitigate this problem in highly dynamic environments, we (1) adopt an online Dirichlet change point detection (ODCP) algorithm to detect the changes in the distribution of experiences, (2) develop a Deep Q Network (DQN) agent that is capable of recognizing diurnal patterns and making informed dispatching decisions according to the changes in the underlying environment. Rather than fixing patterns by time of week, the proposed approach automatically detects that the MDP has changed, and uses the results of the new model. In addition to the adaptation logic in dispatching, this paper also proposes a dynamic, demand-aware vehicle-passenger matching and route planning framework that dynamically generates optimal routes for each vehicle based on online demand, vehicle capacities, and locations. Evaluation on New York City Taxi public dataset shows the effectiveness of our approach in improving the fleet utilization, where less than 50% of the fleet are utilized to serve the demand of up to 90% of the requests, while maximizing profits and minimizing idle times.
Learning Monopoly Gameplay: A Hybrid Model-Free Deep Reinforcement Learning and Imitation Learning Approach
Mar 01, 2021

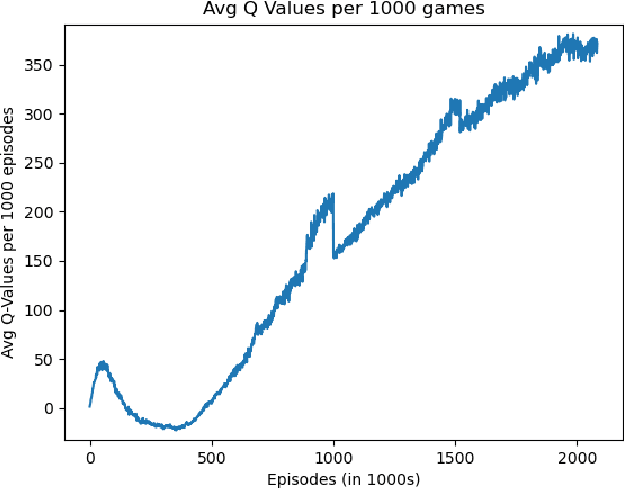
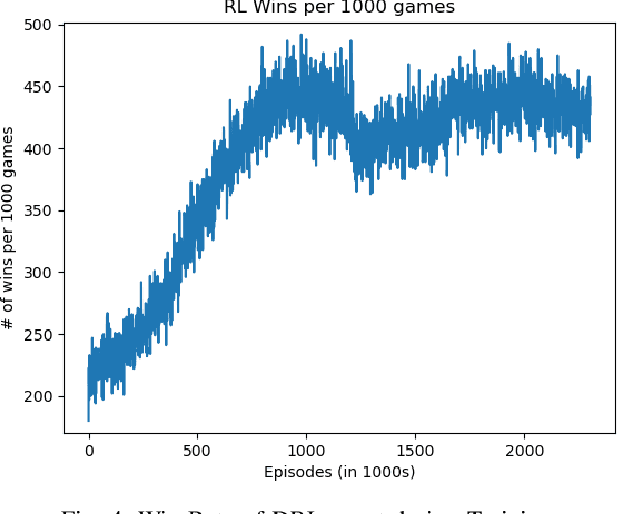
Learning how to adapt and make real-time informed decisions in dynamic and complex environments is a challenging problem. To learn this task, Reinforcement Learning (RL) relies on an agent interacting with an environment and learning through trial and error to maximize the cumulative sum of rewards received by it. In multi-player Monopoly game, players have to make several decisions every turn which involves complex actions, such as making trades. This makes the decision-making harder and thus, introduces a highly complicated task for an RL agent to play and learn its winning strategies. In this paper, we introduce a Hybrid Model-Free Deep RL (DRL) approach that is capable of playing and learning winning strategies of the popular board game, Monopoly. To achieve this, our DRL agent (1) starts its learning process by imitating a rule-based agent (that resembles the human logic) to initialize its policy, (2) learns the successful actions, and improves its policy using DRL. Experimental results demonstrate an intelligent behavior of our proposed agent as it shows high win rates against different types of agent-players.
PassGoodPool: Joint Passengers and Goods Fleet Management with Reinforcement Learning aided Pricing, Matching, and Route Planning
Nov 17, 2020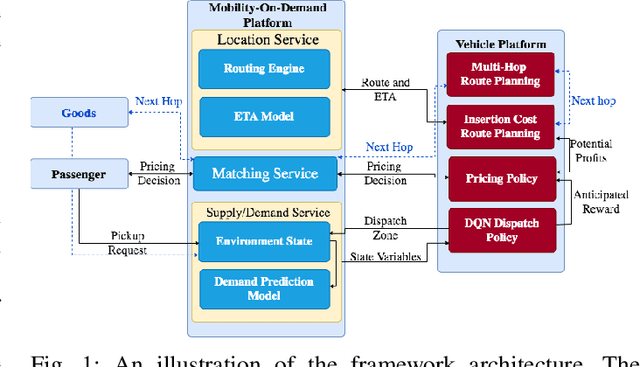
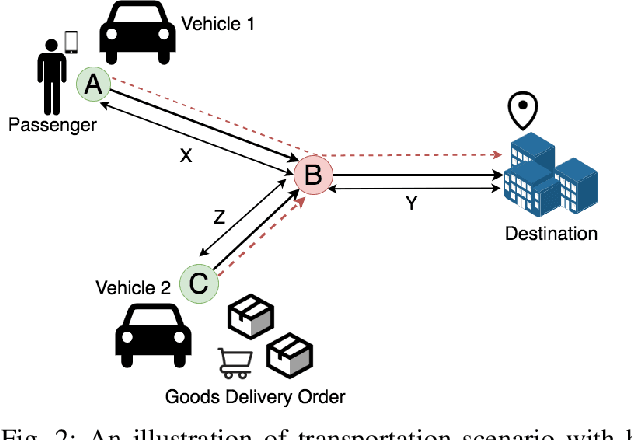
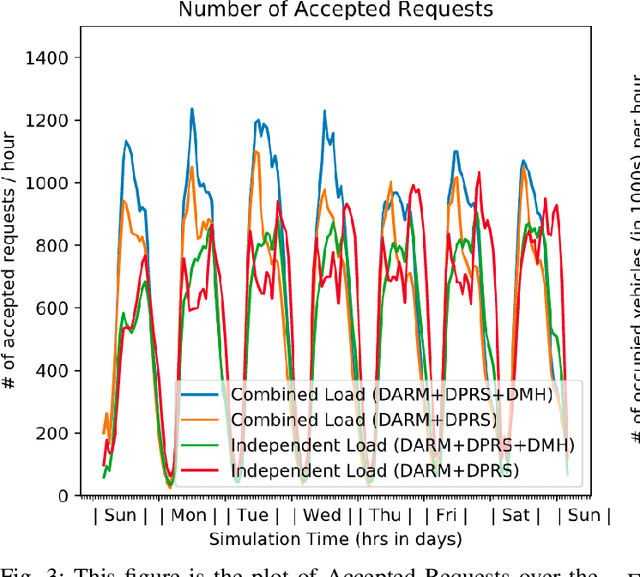
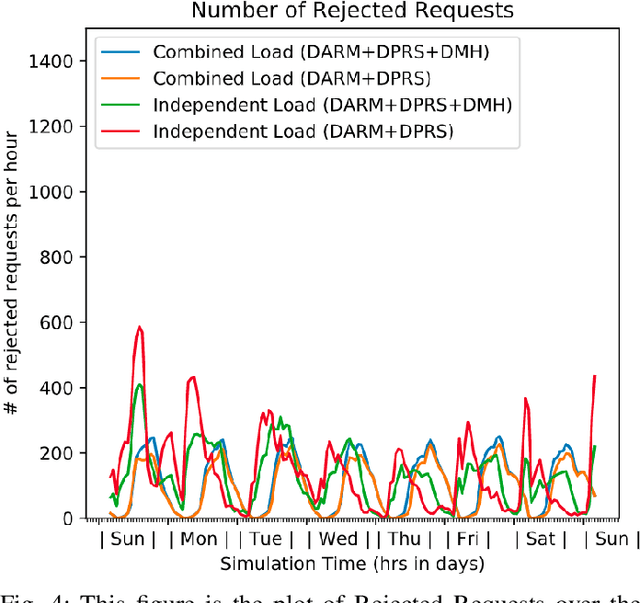
In this paper, we present a dynamic, demand aware, and pricing-based matching and route planning framework that allows efficient pooling of multiple passengers and goods in each vehicle. This approach includes the flexibility for transferring goods through multiple hops from source to destination as well as pooling of passengers. The key components of the proposed approach include (i) Pricing by the vehicles to passengers which is based on the insertion cost, which determines the matching based on passenger's acceptance/rejection, (ii) Matching of goods to vehicles, and the multi-hop routing of goods, (iii) Route planning of the vehicles to pick. up and drop passengers and goods, (i) Dispatching idle vehicles to areas of anticipated high passenger and goods demand using Deep Reinforcement Learning, and (v) Allowing for distributed inference at each vehicle while collectively optimizing fleet objectives. Our proposed framework can be deployed independently within each vehicle as this minimizes computational costs associated with the gorwth of distributed systems and democratizes decision-making to each individual. The proposed framework is validated in a simulated environment, where we leverage realistic delivery datasets such as the New York City Taxi public dataset and Google Maps traffic data from delivery offering businesses.Simulations on a variety of vehicle types, goods, and passenger utility functions show the effectiveness of our approach as compared to baselines that do not consider combined load transportation or dynamic multi-hop route planning. Our proposed method showed improvements over the next best baseline in various aspects including a 15% increase in fleet utilization and 20% increase in average vehicle profits.
A Distributed Model-Free Ride-Sharing Approach for Joint Matching, Pricing, and Dispatching using Deep Reinforcement Learning
Oct 05, 2020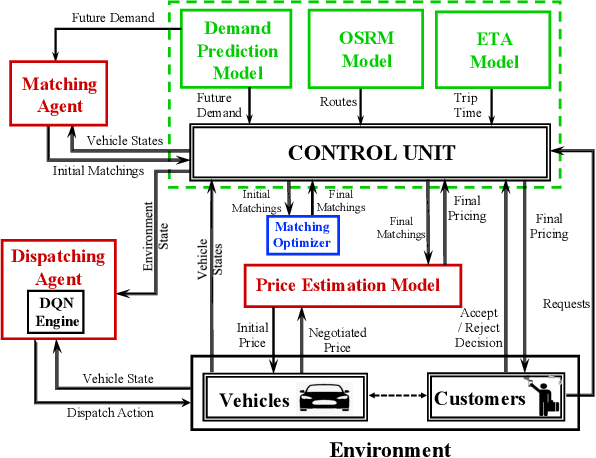
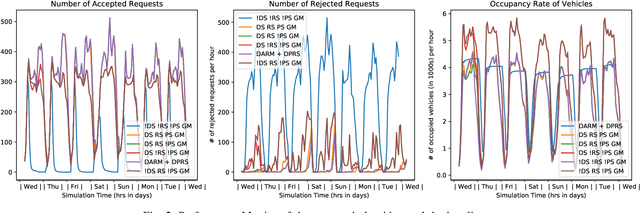
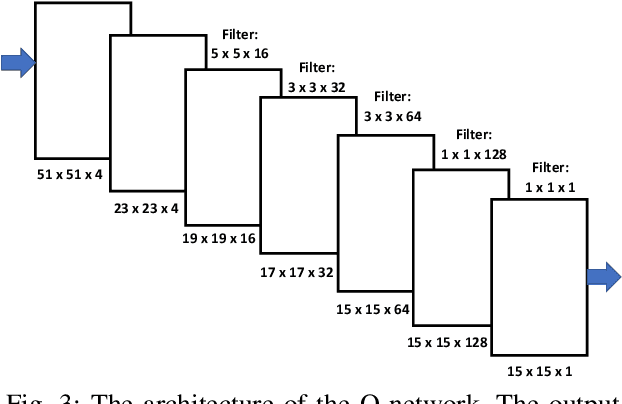
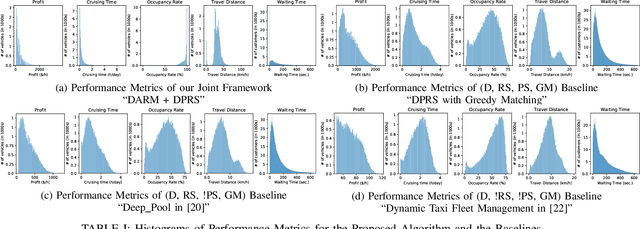
Significant development of ride-sharing services presents a plethora of opportunities to transform urban mobility by providing personalized and convenient transportation while ensuring efficiency of large-scale ride pooling. However, a core problem for such services is route planning for each driver to fulfill the dynamically arriving requests while satisfying given constraints. Current models are mostly limited to static routes with only two rides per vehicle (optimally) or three (with heuristics). In this paper, we present a dynamic, demand aware, and pricing-based vehicle-passenger matching and route planning framework that (1) dynamically generates optimal routes for each vehicle based on online demand, pricing associated with each ride, vehicle capacities and locations. This matching algorithm starts greedily and optimizes over time using an insertion operation, (2) involves drivers in the decision-making process by allowing them to propose a different price based on the expected reward for a particular ride as well as the destination locations for future rides, which is influenced by supply-and demand computed by the Deep Q-network, (3) allows customers to accept or reject rides based on their set of preferences with respect to pricing and delay windows, vehicle type and carpooling preferences, and (4) based on demand prediction, our approach re-balances idle vehicles by dispatching them to the areas of anticipated high demand using deep Reinforcement Learning (RL). Our framework is validated using the New York City Taxi public dataset; however, we consider different vehicle types and designed customer utility functions to validate the setup and study different settings. Experimental results show the effectiveness of our approach in real-time and large scale settings.