 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multi-Agent Reinforcement Learning driven Over-The-Counter Market Simulations
Oct 13, 2022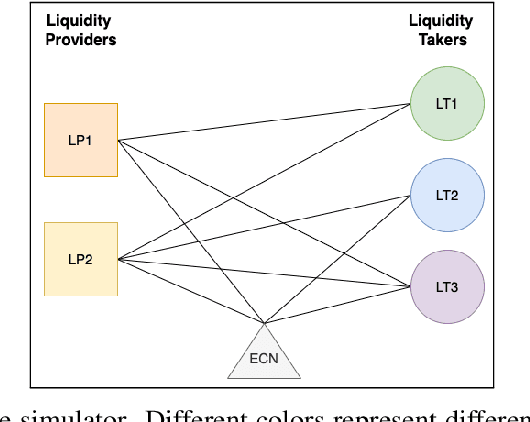


We study a game between liquidity provider and liquidity taker agents interacting in an over-the-counter market, for which the typical example is foreign exchange. We show how a suitable design of parameterized families of reward functions coupled with associated shared policy learning constitutes an efficient solution to this problem. Precisely, we show that our deep-reinforcement-learning-driven agents learn emergent behaviors relative to a wide spectrum of incentives encompassing profit-and-loss, optimal execution and market share, by playing against each other. In particular, we find that liquidity providers naturally learn to balance hedging and skewing as a function of their incentives, where the latter refers to setting their buy and sell prices asymmetrically as a function of their inventory. We further introduce a novel RL-based calibration algorithm which we found performed well at imposing constraints on the game equilibrium, both on toy and real market data.
CTMSTOU driven markets: simulated environment for regime-awareness in trading policies
Feb 03, 2022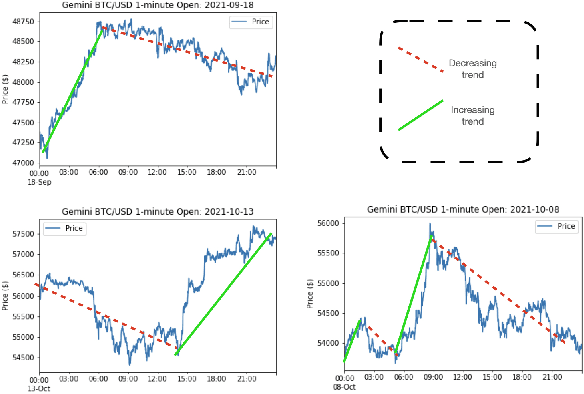
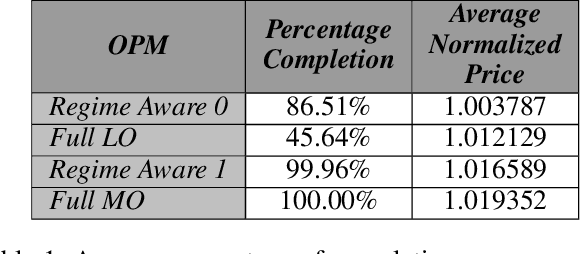
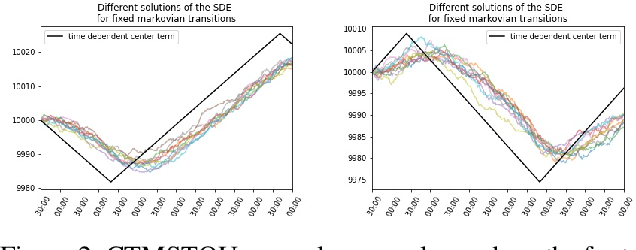
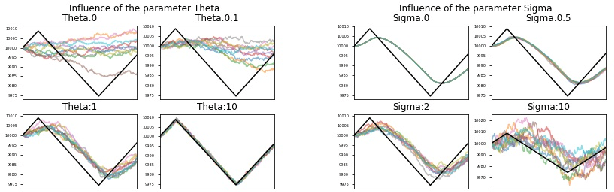
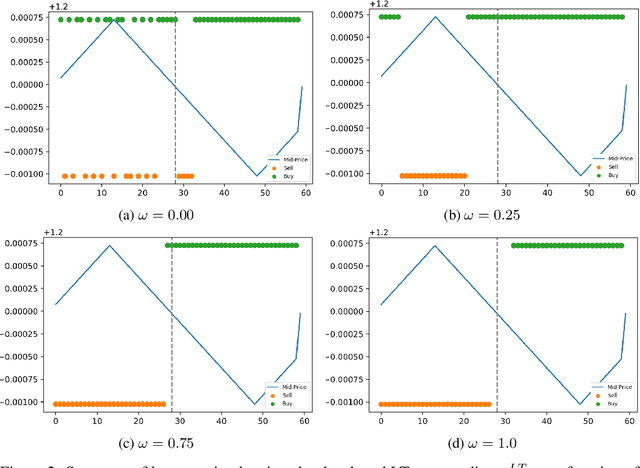
Market regimes is a popular topic in quantitative finance even though there is little consensus on the details of how they should be defined. They arise as a feature both in financial market prediction problems and financial market task performing problems. In this work we use discrete event time multi-agent market simulation to freely experiment in a reproducible and understandable environment where regimes can be explicitly switched and enforced. We introduce a novel stochastic process to model the fundamental value perceived by market participants: Continuous-Time Markov Switching Trending Ornstein-Uhlenbeck (CTMSTOU), which facilitates the study of trading policies in regime switching markets. We define the notion of regime-awareness for a trading agent as well and illustrate its importance through the study of different order placement strategies in the context of order execution problems.
ABIDES-Gym: Gym Environments for Multi-Agent Discrete Event Simulation and Application to Financial Markets
Oct 27, 2021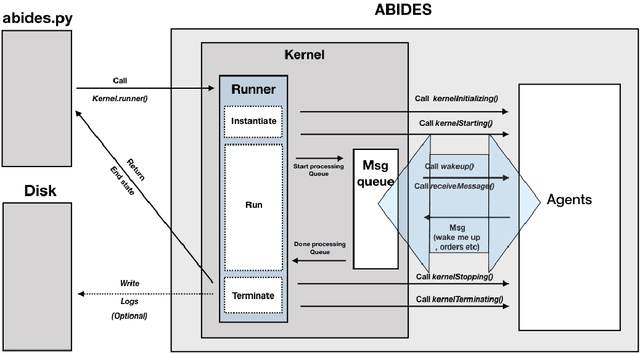
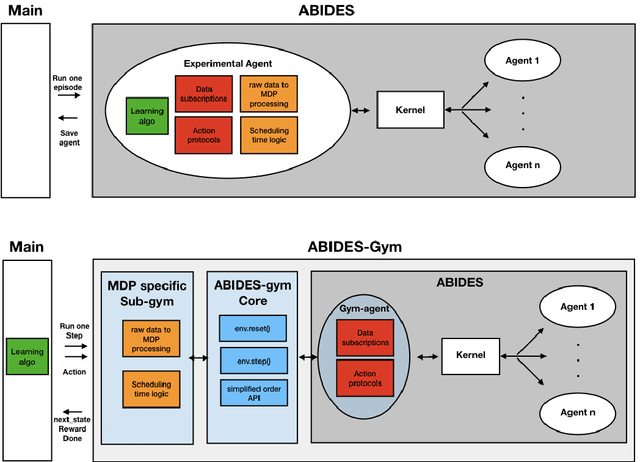
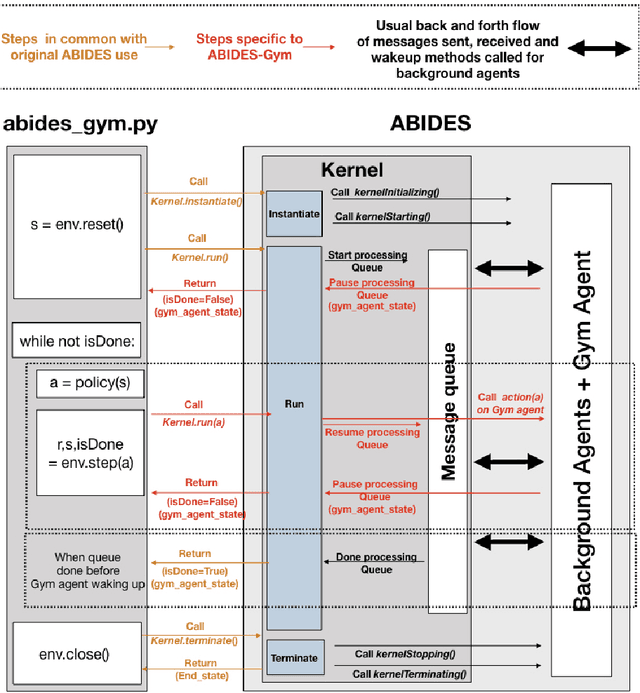
Model-free Reinforcement Learning (RL) requires the ability to sample trajectories by taking actions in the original problem environment or a simulated version of it. Breakthroughs in the field of RL have been largely facilitated by the development of dedicated open source simulators with easy to use frameworks such as OpenAI Gym and its Atari environments. In this paper we propose to use the OpenAI Gym framework on discrete event time based Discrete Event Multi-Agent Simulation (DEMAS). We introduce a general technique to wrap a DEMAS simulator into the Gym framework. We expose the technique in detail and implement it using the simulator ABIDES as a base. We apply this work by specifically using the markets extension of ABIDES, ABIDES-Markets, and develop two benchmark financial markets OpenAI Gym environments for training daily investor and execution agents. As a result, these two environments describe classic financial problems with a complex interactive market behavior response to the experimental agent's action.
AI pptX: Robust Continuous Learning for Document Generation with AI Insights
Oct 02, 2020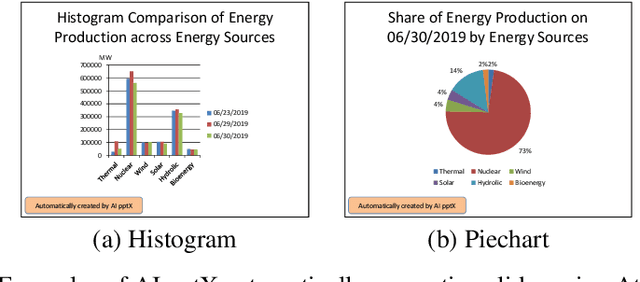
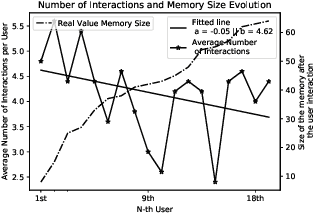
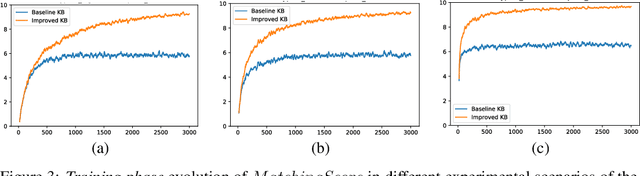
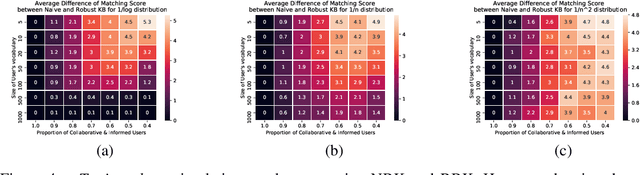
Business analysts create billions of slide decks, reports and documents annually. Most of these documents have well-defined structure comprising of similar content generated from data. We present 'AI pptX', a novel AI framework for creating and modifying documents as well as extract insights in the form of natural language sentences from data. AI pptX has three main components: (i) a component that translates users' natural language input into 'skills' that encapsulate content editing and formatting commands, (ii) a robust continuously learning component that interacts with users, and (iii) a component that automatically generates hierarchical insights in the form of natural language sentences. We illustrate (i) and (ii) with a study of 18 human users tasked to create a presentation deck and observe the learning capability from a decrease in user-input commands by up to 45%. We demonstrate the robust learning capability of AI pptX with experimental simulations of non-collaborative users. We illustrate (i) and (iii) by automatically generating insights in natural language using a data set from the Electricity Transmission Network of France (RTE); we show that a complex statistical analysis of series can automatically be distilled into easily interpretable explanations called AI Insights.