 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceTailor: Lightweight Plug-In Adapter for Diffusion-Based Personalized Text-to-Speech
Paper and Code
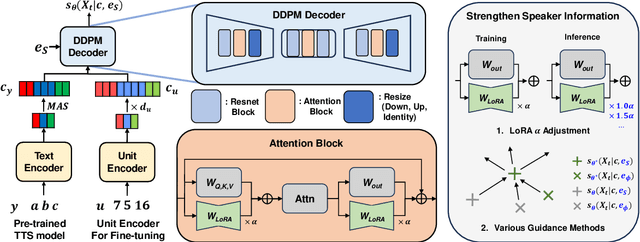
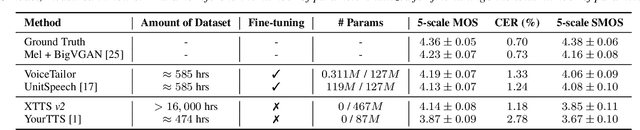
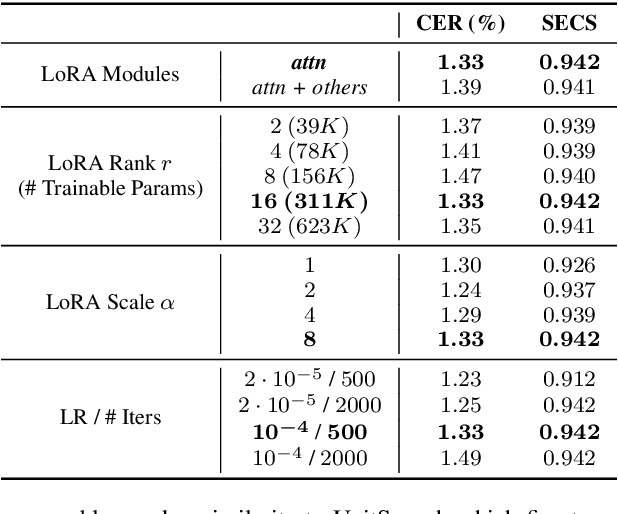
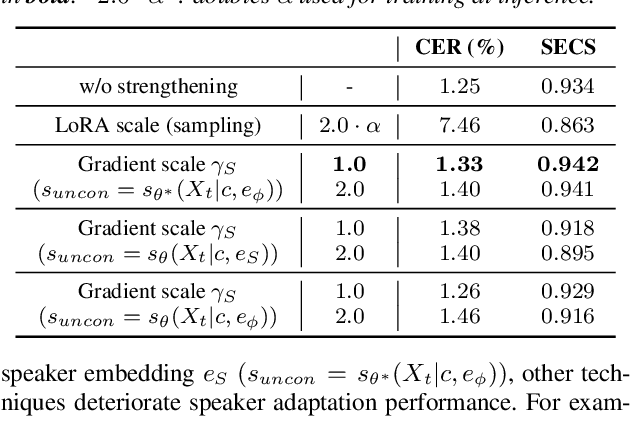
We propose VoiceTailor, a parameter-efficient speaker-adaptive text-to-speech (TTS) system, by equipping a pre-trained diffusion-based TTS model with a personalized adapter. VoiceTailor identifies pivotal modules that benefit from the adapter based on a weight change ratio analysis. We utilize Low-Rank Adaptation (LoRA) as a parameter-efficient adaptation method and incorporate the adapter into pivotal modules of the pre-trained diffusion decoder. To achieve powerful adaptation performance with few parameters, we explore various guidance techniques for speaker adaptation and investigate the best strategies to strengthen speaker information. VoiceTailor demonstrates comparable speaker adaptation performance to existing adaptive TTS models by fine-tuning only 0.25\% of the total parameters. VoiceTailor shows strong robustness when adapting to a wide range of real-world speakers, as shown in the demo.