Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceGuider: Enhancing Out-of-Domain Performance in Parameter-Efficient Speaker-Adaptive Text-to-Speech via Autoguidance
Paper and Code
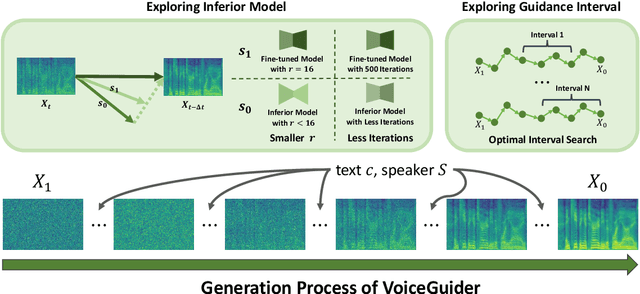
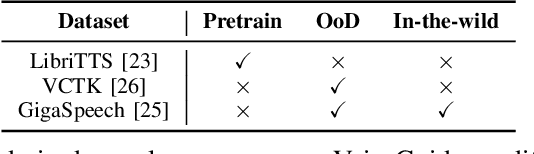
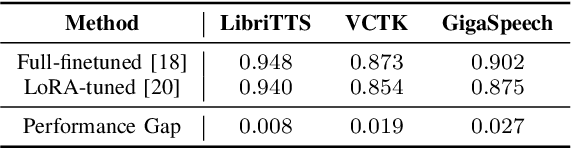
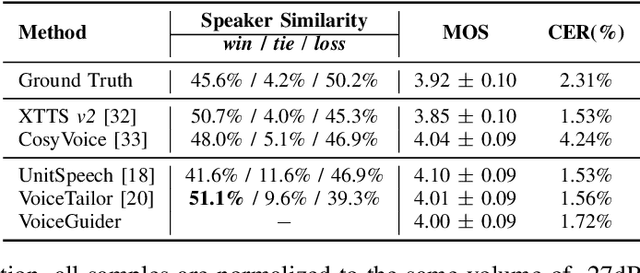
When applying parameter-efficient finetuning via LoRA onto speaker adaptive text-to-speech models, adaptation performance may decline compared to full-finetuned counterparts, especially for out-of-domain speakers. Here, we propose VoiceGuider, a parameter-efficient speaker adaptive text-to-speech system reinforced with autoguidance to enhance the speaker adaptation performance, reducing the gap against full-finetuned models. We carefully explore various ways of strengthening autoguidance, ultimately finding the optimal strategy. VoiceGuider as a result shows robust adaptation performance especially on extreme out-of-domain speech data. We provide audible samples in our demo page.
* Submitted to ICASSP 2025, Demo Page: https://voiceguider.github.io/
View paper on