 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARHN: Answer-Centric Relabeling of Hard Negatives with Open-Source LLMs for Dense Retrieval
Apr 13, 2026Neural retrievers are often trained on large-scale triplet data comprising a query, a positive passage, and a set of hard negatives. In practice, hard-negative mining can introduce false negatives and other ambiguous negatives, including passages that are relevant or contain partial answers to the query. Such label noise yields inconsistent supervision and can degrade retrieval effectiveness. We propose ARHN (Answer-centric Relabeling of Hard Negatives), a two-stage framework that leverages open-source LLMs to refine hard negative samples using answer-centric relevance signals. In the first stage, for each query-passage pair, ARHN prompts the LLM to generate a passage-grounded answer snippet or to indicate that the passage does not support an answer. In the second stage, ARHN applies an LLM-based listwise ranking over the candidate set to order passages by direct answerability to the query. Passages ranked above the original positive are relabeled to additional positives. Among passages ranked below the positive, ARHN excludes any that contain an answer snippet from the negative set to avoid ambiguous supervision. We evaluated ARHN on the BEIR benchmark under three configurations: relabeling only, filtering only, and their combination. Across datasets, the combined strategy consistently improves over either step in isolation, indicating that jointly relabeling false negatives and filtering ambiguous negatives yields cleaner supervision for training neural retrieval models. By relying strictly on open-source models, ARHN establishes a cost-effective and scalable refinement pipeline suitable for large-scale training.
LG-ANNA-Embedding technical report
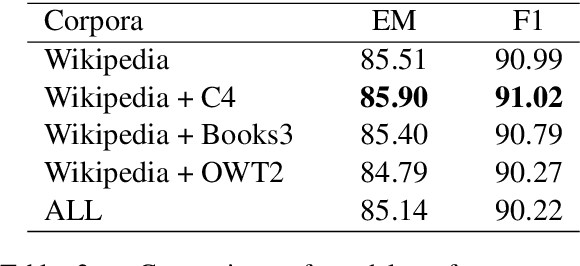
Jun 09, 2025This report presents a unified instruction-based framework for learning generalized text embeddings optimized for both information retrieval (IR) and non-IR tasks. Built upon a decoder-only large language model (Mistral-7B), our approach combines in-context learning, soft supervision, and adaptive hard-negative mining to generate context-aware embeddings without task-specific fine-tuning. Structured instructions and few-shot examples are used to guide the model across diverse tasks, enabling strong performance on classification, semantic similarity, clustering, and reranking benchmarks. To improve semantic discrimination, we employ a soft labeling framework where continuous relevance scores, distilled from a high-performance dense retriever and reranker, serve as fine-grained supervision signals. In addition, we introduce adaptive margin-based hard-negative mining, which filters out semantically ambiguous negatives based on their similarity to positive examples, thereby enhancing training stability and retrieval robustness. Our model is evaluated on the newly introduced MTEB (English, v2) benchmark, covering 41 tasks across seven categories. Results show that our method achieves strong generalization and ranks among the top-performing models by Borda score, outperforming several larger or fully fine-tuned baselines. These findings highlight the effectiveness of combining in-context prompting, soft supervision, and adaptive sampling for scalable, high-quality embedding generation.
Lightweight Deepfake Detection Based on Multi-Feature Fusion
Feb 17, 2025



Deepfake technology utilizes deep learning based face manipulation techniques to seamlessly replace faces in videos creating highly realistic but artificially generated content. Although this technology has beneficial applications in media and entertainment misuse of its capabilities may lead to serious risks including identity theft cyberbullying and false information. The integration of DL with visual cognition has resulted in important technological improvements particularly in addressing privacy risks caused by artificially generated deepfake images on digital media platforms. In this study we propose an efficient and lightweight method for detecting deepfake images and videos making it suitable for devices with limited computational resources. In order to reduce the computational burden usually associated with DL models our method integrates machine learning classifiers in combination with keyframing approaches and texture analysis. Moreover the features extracted with a histogram of oriented gradients (HOG) local binary pattern (LBP) and KAZE bands were integrated to evaluate using random forest extreme gradient boosting extra trees and support vector classifier algorithms. Our findings show a feature-level fusion of HOG LBP and KAZE features improves accuracy to 92% and 96% on FaceForensics++ and Celeb-DFv2 respectively.
SERN: Simulation-Enhanced Realistic Navigation for Multi-Agent Robotic Systems in Contested Environments
Oct 22, 2024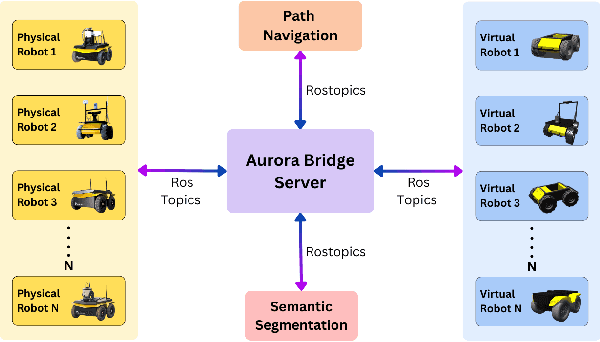
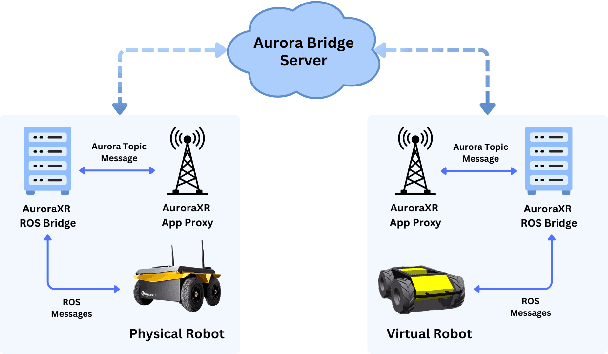
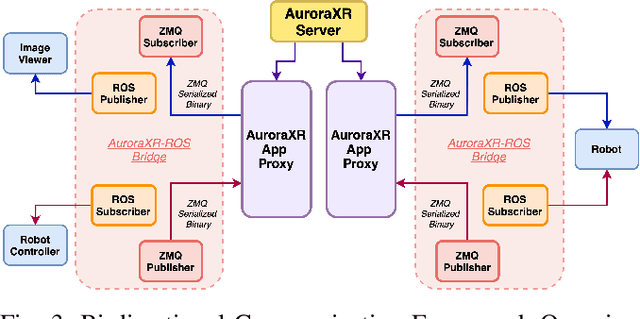
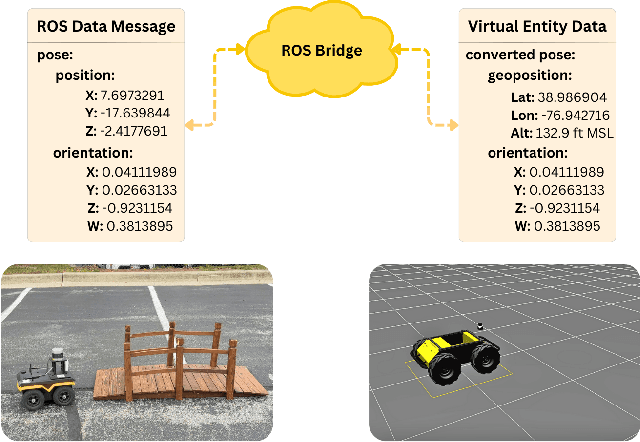
The increasing deployment of autonomous systems in complex environments necessitates efficient communication and task completion among multiple agents. This paper presents SERN (Simulation-Enhanced Realistic Navigation), a novel framework integrating virtual and physical environments for real-time collaborative decision-making in multi-robot systems. SERN addresses key challenges in asset deployment and coordination through a bi-directional communication framework using the AuroraXR ROS Bridge. Our approach advances the SOTA through accurate real-world representation in virtual environments using Unity high-fidelity simulator; synchronization of physical and virtual robot movements; efficient ROS data distribution between remote locations; and integration of SOTA semantic segmentation for enhanced environmental perception. Our evaluations show a 15% to 24% improvement in latency and up to a 15% increase in processing efficiency compared to traditional ROS setups. Real-world and virtual simulation experiments with multiple robots demonstrate synchronization accuracy, achieving less than 5 cm positional error and under 2-degree rotational error. These results highlight SERN's potential to enhance situational awareness and multi-agent coordination in diverse, contested environments.
FieldHAR: A Fully Integrated End-to-end RTL Framework for Human Activity Recognition with Neural Networks from Heterogeneous Sensors
May 22, 2023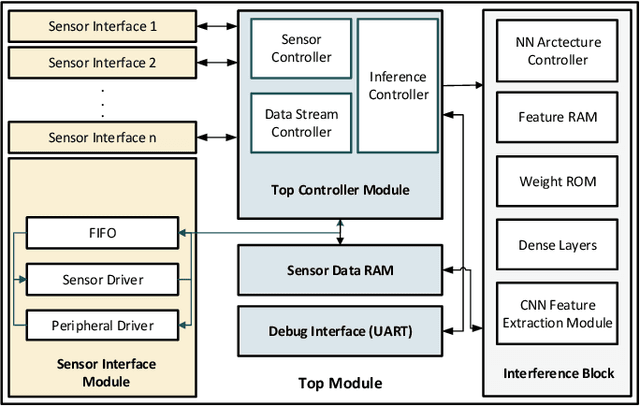
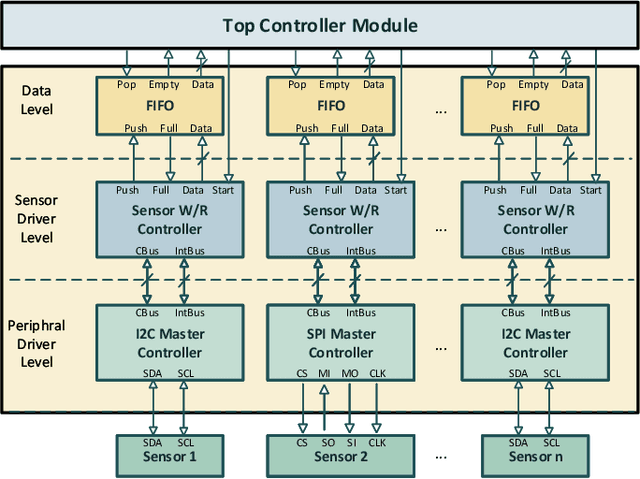
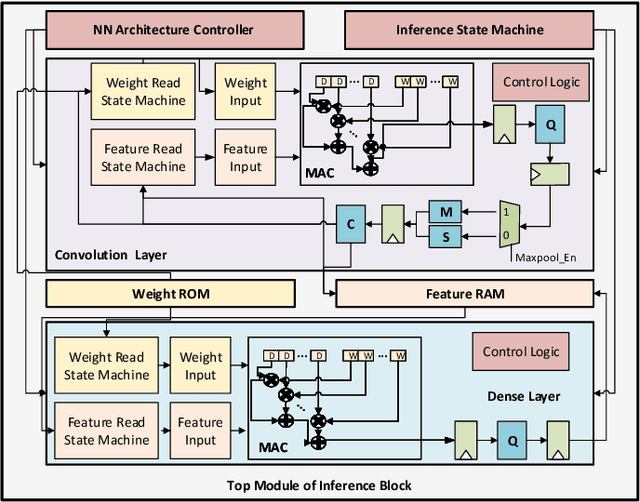
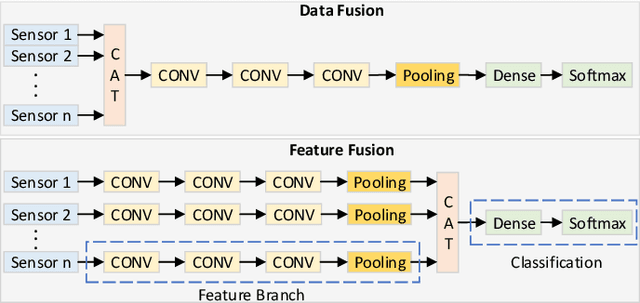
In this work, we propose an open-source scalable end-to-end RTL framework FieldHAR, for complex human activity recognition (HAR) from heterogeneous sensors using artificial neural networks (ANN) optimized for FPGA or ASIC integration. FieldHAR aims to address the lack of apparatus to transform complex HAR methodologies often limited to offline evaluation to efficient run-time edge applications. The framework uses parallel sensor interfaces and integer-based multi-branch convolutional neural networks (CNNs) to support flexible modality extensions with synchronous sampling at the maximum rate of each sensor. To validate the framework, we used a sensor-rich kitchen scenario HAR application which was demonstrated in a previous offline study. Through resource-aware optimizations, with FieldHAR the entire RTL solution was created from data acquisition to ANN inference taking as low as 25\% logic elements and 2\% memory bits of a low-end Cyclone IV FPGA and less than 1\% accuracy loss from the original FP32 precision offline study. The RTL implementation also shows advantages over MCU-based solutions, including superior data acquisition performance and virtually eliminating ANN inference bottleneck.
ANNA: Enhanced Language Representation for Question Answering
Apr 04, 2022
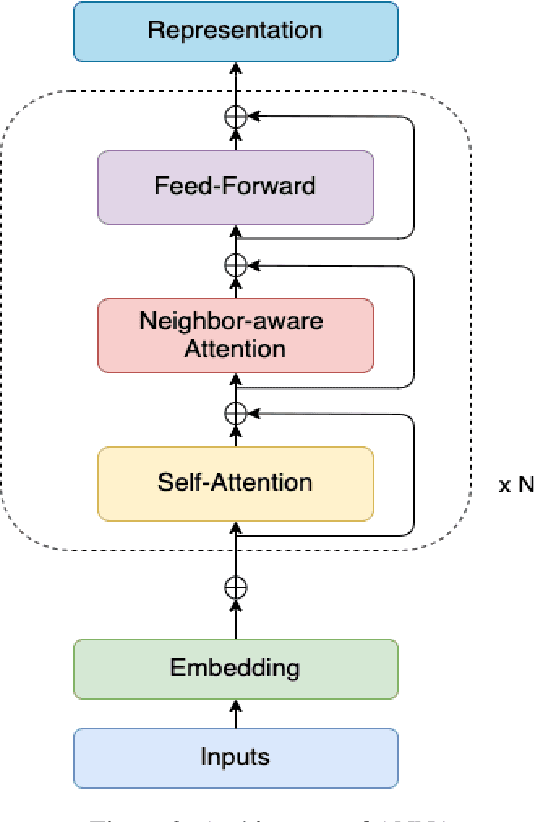
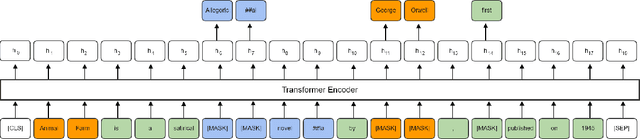
Pre-trained language models have brought significant improvements in performance in a variety of natural language processing tasks. Most existing models performing state-of-the-art results have shown their approaches in the separate perspectives of data processing, pre-training tasks, neural network modeling, or fine-tuning. In this paper, we demonstrate how the approaches affect performance individually, and that the language model performs the best results on a specific question answering task when those approaches are jointly considered in pre-training models. In particular, we propose an extended pre-training task, and a new neighbor-aware mechanism that attends neighboring tokens more to capture the richness of context for pre-training language modeling. Our best model achieves new state-of-the-art results of 95.7\% F1 and 90.6\% EM on SQuAD 1.1 and also outperforms existing pre-trained language models such as RoBERTa, ALBERT, ELECTRA, and XLNet on the SQuAD 2.0 benchmark.
* 11 pages, 3 figures
Korean-Specific Dataset for Table Question Answering
Jan 17, 2022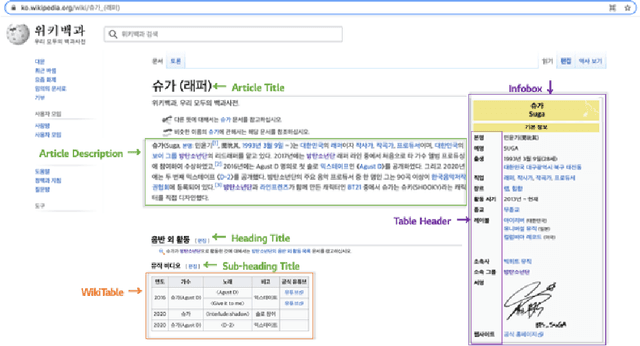
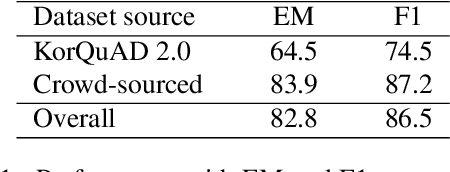

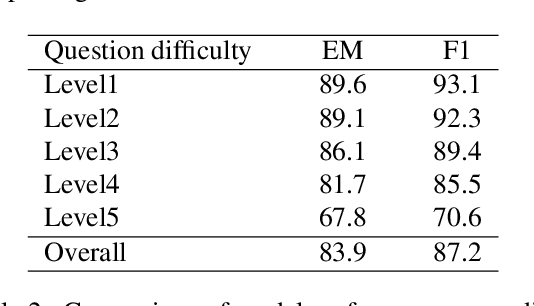
Existing question answering systems mainly focus on dealing with text data. However, much of the data produced daily is stored in the form of tables that can be found in documents and relational databases, or on the web. To solve the task of question answering over tables, there exist many datasets for table question answering written in English, but few Korean datasets. In this paper, we demonstrate how we construct Korean-specific datasets for table question answering: Korean tabular dataset is a collection of 1.4M tables with corresponding descriptions for unsupervised pre-training language models. Korean table question answering corpus consists of 70k pairs of questions and answers created by crowd-sourced workers. Subsequently, we then build a pre-trained language model based on Transformer, and fine-tune the model for table question answering with these datasets. We then report the evaluation results of our model. We make our datasets publicly available via our GitHub repository, and hope that those datasets will help further studies for question answering over tables, and for transformation of table formats.
SMORES-EP, a Modular Robot with Parallel Self-assembly
Apr 01, 2021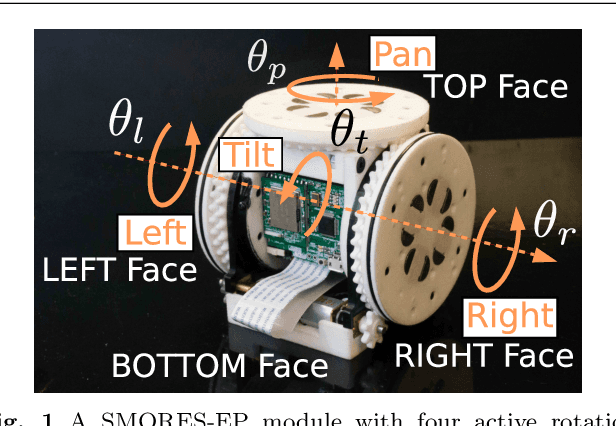

Self-assembly of modular robotic systems enables the construction of complex robotic configurations to adapt to different tasks. This paper presents a framework for SMORES types of modular robots to efficiently self-assemble into tree topologies. These modular robots form kinematic chains that have been shown to be capable of a large variety of manipulation and locomotion tasks, yet they can reconfigure using a mobile reconfiguration. A desired kinematic topology can be mapped onto a planar pattern with optimal module assignment based on the modules' locations, then the mobile reconfiguration assembly process can be executed in parallel. A docking controller is developed to guarantee the success of docking processes. A hybrid control architecture is designed to handle a large number of modules and complex behaviors of each individual, and achieve efficient and robust self-assembly actions. The framework is demonstrated in hardware on the SMORES-EP platform.
Layer-specific Optimization for Mixed Data Flow with Mixed Precision in FPGA Design for CNN-based Object Detectors
Sep 03, 2020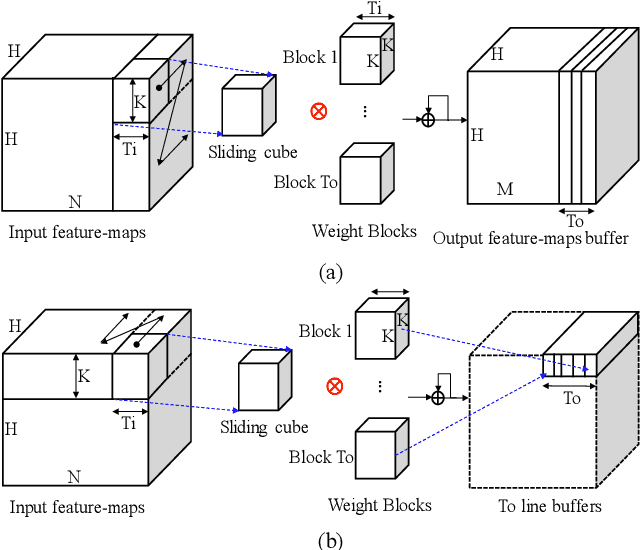
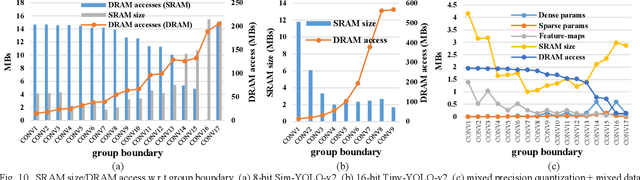
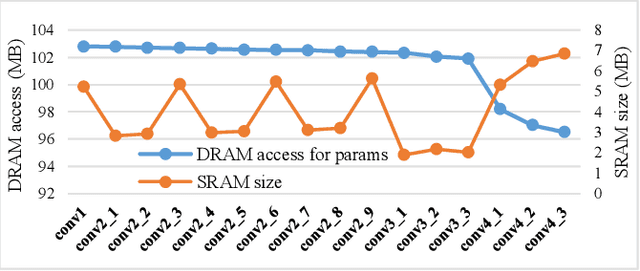
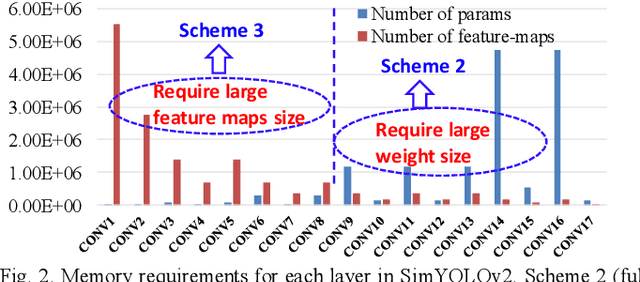
Convolutional neural networks (CNNs) require both intensive computation and frequent memory access, which lead to a low processing speed and large power dissipation. Although the characteristics of the different layers in a CNN are frequently quite different, previous hardware designs have employed common optimization schemes for them. This paper proposes a layer-specific design that employs different organizations that are optimized for the different layers. The proposed design employs two layer-specific optimizations: layer-specific mixed data flow and layer-specific mixed precision. The mixed data flow aims to minimize the off-chip access while demanding a minimal on-chip memory (BRAM) resource of an FPGA device. The mixed precision quantization is to achieve both a lossless accuracy and an aggressive model compression, thereby further reducing the off-chip access. A Bayesian optimization approach is used to select the best sparsity for each layer, achieving the best trade-off between the accuracy and compression. This mixing scheme allows the entire network model to be stored in BRAMs of the FPGA to aggressively reduce the off-chip access, and thereby achieves a significant performance enhancement. The model size is reduced by 22.66-28.93 times compared to that in a full-precision network with a negligible degradation of accuracy on VOC, COCO, and ImageNet datasets. Furthermore, the combination of mixed dataflow and mixed precision significantly outperforms the previous works in terms of both throughput, off-chip access, and on-chip memory requirement.
Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty for Autonomous Driving
Apr 09, 2019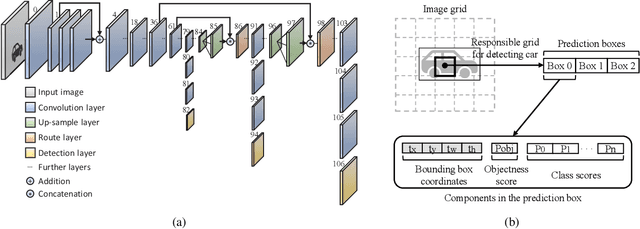
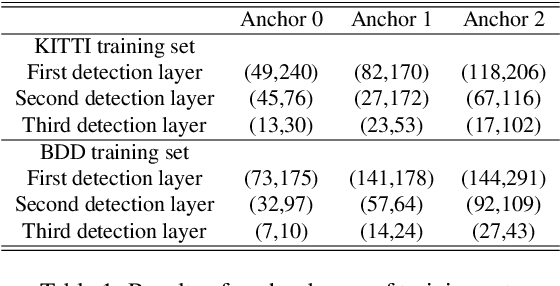
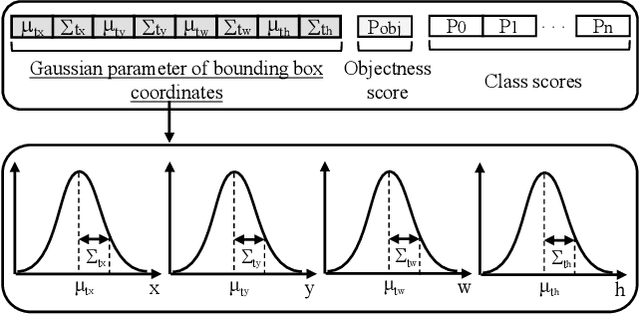
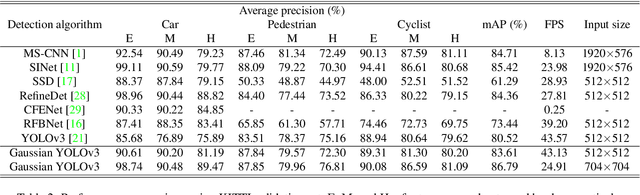
The use of object detection algorithms is becoming increasingly important in autonomous vehicles, and object detection at high accuracy and a fast inference speed is essential for safe autonomous driving. A false positive (FP) from a false localization during autonomous driving can lead to fatal accidents and hinder safe and efficient driving. Therefore, a detection algorithm that can cope with mislocalizations is required in autonomous driving applications. This paper proposes a method for improving the detection accuracy while supporting a real-time operation by modeling the bounding box (bbox) of YOLOv3, which is the most representative of one-stage detectors, with a Gaussian parameter and redesigning the loss function. In addition, this paper proposes a method for predicting the localization uncertainty that indicates the reliability of bbox. By using the predicted localization uncertainty during the detection process, the proposed schemes can significantly reduce the FP and increase the true positive (TP), thereby improving the accuracy. Compared to a conventional YOLOv3, the proposed algorithm, Gaussian YOLOv3, improves the mean average precision (mAP) by 3.09 and 3.5 on the KITTI and Berkeley deep drive (BDD) datasets, respectively. In addition, on the same datasets, the proposed algorithm can reduce the FP by 41.40% and 40.62%, and increase the TP by 7.26% and 4.3%, respectively. Nevertheless, the proposed algorithm is capable of real-time detection at faster than 42 frames per second (fps).