 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-specific Optimization for Mixed Data Flow with Mixed Precision in FPGA Design for CNN-based Object Detectors
Paper and Code
Sep 03, 2020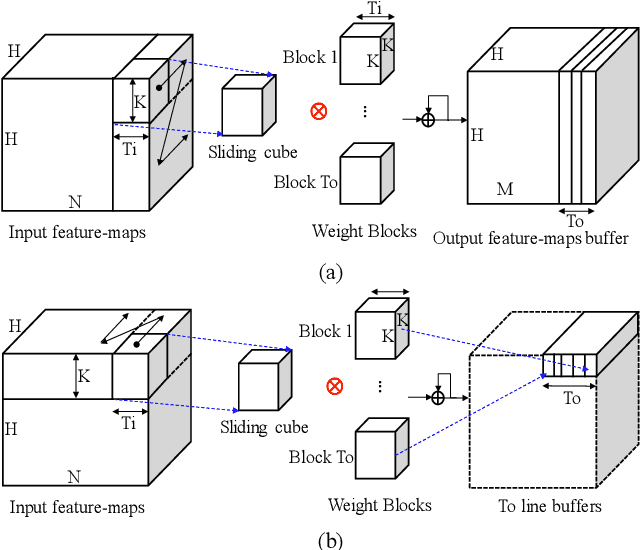
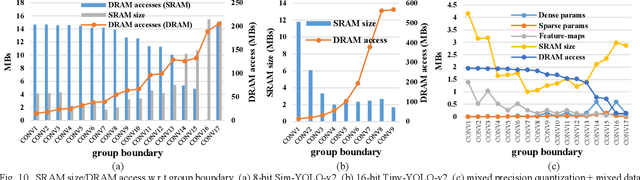
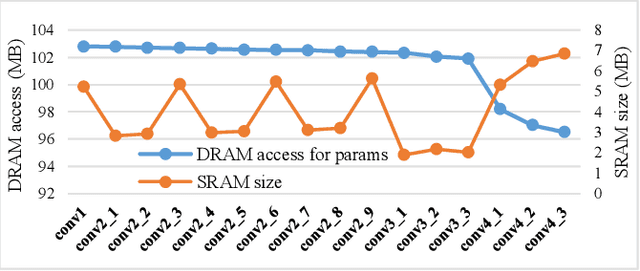
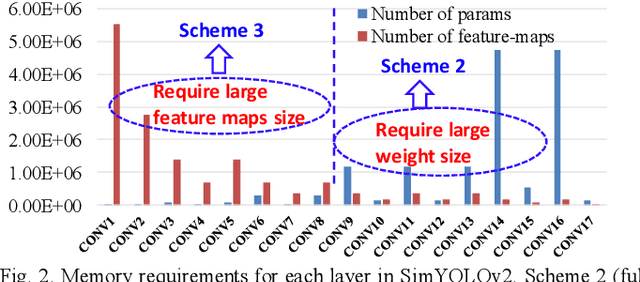
Convolutional neural networks (CNNs) require both intensive computation and frequent memory access, which lead to a low processing speed and large power dissipation. Although the characteristics of the different layers in a CNN are frequently quite different, previous hardware designs have employed common optimization schemes for them. This paper proposes a layer-specific design that employs different organizations that are optimized for the different layers. The proposed design employs two layer-specific optimizations: layer-specific mixed data flow and layer-specific mixed precision. The mixed data flow aims to minimize the off-chip access while demanding a minimal on-chip memory (BRAM) resource of an FPGA device. The mixed precision quantization is to achieve both a lossless accuracy and an aggressive model compression, thereby further reducing the off-chip access. A Bayesian optimization approach is used to select the best sparsity for each layer, achieving the best trade-off between the accuracy and compression. This mixing scheme allows the entire network model to be stored in BRAMs of the FPGA to aggressively reduce the off-chip access, and thereby achieves a significant performance enhancement. The model size is reduced by 22.66-28.93 times compared to that in a full-precision network with a negligible degradation of accuracy on VOC, COCO, and ImageNet datasets. Furthermore, the combination of mixed dataflow and mixed precision significantly outperforms the previous works in terms of both throughput, off-chip access, and on-chip memory requirement.