 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAN-MLP-Mixer: A comprehensive investigation of the usage of Kolmogorov-Arnold Networks (KANs) for improving IMU-based Human Activity Recognition
May 18, 2026Kolmogorov-Arnold Networks (KANs) have demonstrated an exceptional ability to learn complex functions on clean, low-dimensional data but struggle to maintain performance on noisy and imperfect real-world datasets. In contrast, conventional multi-layer perceptrons (MLPs) are far more tolerant to noise and computationally efficient. Replacing all MLP components with KANs in HAR models often degrades accuracy and computation efficiency, highlighting an open challenge: how to combine KANs' precision with MLPs' noise robustness and efficiency. To address this, we systematically explore various placements of KAN modules within deep HAR networks and propose a hybrid architecture that strategically synergizes the strengths of both paradigms, which uses a KAN-based input embedding layer, retains MLP layers for intermediate feature mixing, and introduces a specialized LarctanKAN module for final activity classification. Across eight public HAR datasets, the hybrid KAN-MLP model achieves an average macro F1 score relative improvement of 5.33\% compared pure-MLP model, significantly outperforming standalone KAN and MLP baselines. Furthermore, integrating this hybrid strategy into other state-of-the-art HAR architectures consistently boosts their performance. Our findings demonstrate that a carefully orchestrated combination of KAN, MLP, or other conventional neural components yields more robust and accurate HAR models for real-world wearable sensing environments.
Foundation Models Defining A New Era In Sensor-based Human Activity Recognition: A Survey And Outlook
Apr 03, 2026Sensor-based Human Activity Recognition (HAR) underpins many ubiquitous and wearable computing applications, yet current models remain limited by scarce labels, sensor heterogeneity, and weak generalization across users, devices, and contexts. Foundation models, which are generally pretrained at scale using self-supervised and multimodal learning, offer a unifying paradigm to address these challenges by learning reusable, adaptable representations for activity understanding. This survey synthesizes emerging foundation models for sensor-based HAR. We first clarify foundational concepts, definitions, and evaluation criteria, then organize existing work using a lifecycle-oriented taxonomy spanning input design, pretraining, adaptation, and utilization. Rather than enumerating individual models, we analyze recurring design patterns and trade-offs across nine technical axes, including modality scope, tokenization, architectures, learning paradigms, adaptation mechanisms, and deployment settings. From this synthesis, we identify three dominant development trajectories: (1) HAR-specific foundation models trained from scratch on large sensor corpora, (2) adaptation of general time-series or multimodal foundation models to sensor-based HAR, and (3) integration of large language models for reasoning, annotation, and human-AI interaction. We conclude by highlighting open challenges in data curation, multimodal alignment, personalization, privacy, and responsible deployment, and outline directions toward general-purpose, interpretable, and human-centered foundation models for activity understanding. A complete, continuously updated index of papers and models is available in our companion repository: https://github.com/zhaxidele/Foundation-Models-Defining-A-New-Era-In-Human-Activity-Recognition.
ActivityNarrated: An Open-Ended Narrative Paradigm for Wearable Human Activity Understanding
Apr 01, 2026Wearable HAR has improved steadily, but most progress still relies on closed-set classification, which limits real-world use. In practice, human activity is open-ended, unscripted, personalized, and often compositional, unfolding as narratives rather than instances of fixed classes. We argue that addressing this gap does not require simply scaling datasets or models. It requires a fundamental shift in how wearable HAR is formulated, supervised, and evaluated. This work shows how to model open-ended activity narratives by aligning wearable sensor data with natural-language descriptions in an open-vocabulary setting. Our framework has three core components. First, we introduce a naturalistic data collection and annotation pipeline that combines multi-position wearable sensing with free-form, time-aligned narrative descriptions of ongoing behavior, allowing activity semantics to emerge without a predefined vocabulary. Second, we define a retrieval-based evaluation framework that measures semantic alignment between sensor data and language, enabling principled evaluation without fixed classes while also subsuming closed-set classification as a special case. Third, we present a language-conditioned learning architecture that supports sensor-to-text inference over variable-length sensor streams and heterogeneous sensor placements. Experiments show that models trained with fixed-label objectives degrade sharply under real-world variability, while open-vocabulary sensor-language alignment yields robust and semantically grounded representations. Once this alignment is learned, closed-set activity recognition becomes a simple downstream task. Under cross-participant evaluation, our method achieves 65.3% Macro-F1, compared with 31-34% for strong closed-set HAR baselines. These results establish open-ended narrative modeling as a practical and effective foundation for real-world wearable HAR.
SPECTRA: An Efficient Spectral-Informed Neural Network for Sensor-Based Activity Recognition
Mar 27, 2026Real time sensor based applications in pervasive computing require edge deployable models to ensure low latency privacy and efficient interaction. A prime example is sensor based human activity recognition where models must balance accuracy with stringent resource constraints. Yet many deep learning approaches treat temporal sensor signals as black box sequences overlooking spectral temporal structure while demanding excessive computation. We present SPECTRA a deployment first co designed spectral temporal architecture that integrates short time Fourier transform STFT feature extraction depthwise separable convolutions and channel wise self attention to capture spectral temporal dependencies under real edge runtime and memory constraints. A compact bidirectional GRU with attention pooling summarizes within window dynamics at low cost reducing downstream model burden while preserving accuracy. Across five public HAR datasets SPECTRA matches or approaches larger CNN LSTM and Transformer baselines while substantially reducing parameters latency and energy. Deployments on a Google Pixel 9 smartphone and an STM32L4 microcontroller further demonstrate end to end deployable realtime private and efficient HAR.
Calibration-Free Induced Magnetic Field Indoor and Outdoor Positioning via Data-Driven Modeling
Jan 31, 2026Induced magnetic field (IMF)-based localization offers a robust alternative to wave-based positioning technologies due to its resilience to non-line-of-sight conditions, environmental dynamics, and wireless interference. However, existing magnetic localization systems typically rely on analytical field inversion, manual calibration, or environment-specific fingerprinting, limiting their scalability and transferability. This paper presents a data-driven IMF localization framework that directly maps induced magnetic field measurements to spatial coordinates using supervised learning, eliminating explicit environment-specific calibration. By replacing explicit field modeling with learning-based inference, the proposed approach captures nonlinear field interactions and environmental effects. An orientation-invariant feature representation enables rotation-independent deployment. The system is evaluated across multiple indoor environments and an outdoor deployment. Benchmarking against classical and deep learning baselines shows that a Random Forest regressor achieves sub-20 cm accuracy in 2D and sub-30 cm in 3D localization. Cross-environment validation demonstrates that models trained indoors generalize to outdoor environments without retraining. We further analyze scalability by varying transmitter spacing, showing that coverage and accuracy can be balanced through deployment density. Overall, this work demonstrates that data-driven IMF localization is a scalable and transferable solution for real-world positioning.
Passive Body-Area Electrostatic Field (Human Body Capacitance) for Ubiquitous Computing
Jul 17, 2025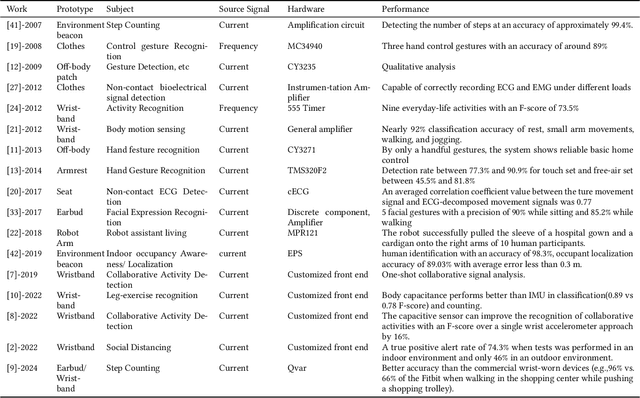
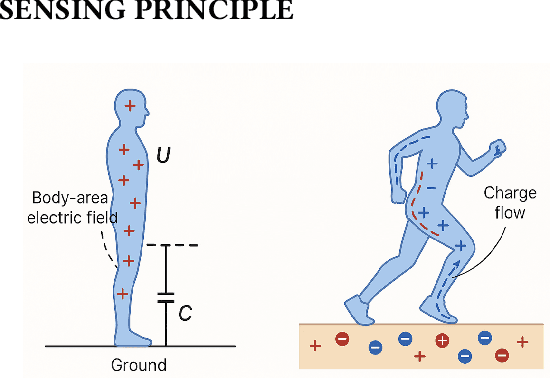

Passive body-area electrostatic field sensing, also referred to as human body capacitance (HBC), is an energy-efficient and non-intrusive sensing modality that exploits the human body's inherent electrostatic properties to perceive human behaviors. This paper presents a focused overview of passive HBC sensing, including its underlying principles, historical evolution, hardware architectures, and applications across research domains. Key challenges, such as susceptibility to environmental variation, are discussed to trigger mitigation techniques. Future research opportunities in sensor fusion and hardware enhancement are highlighted. To support continued innovation, this work provides open-source resources and aims to empower researchers and developers to leverage passive electrostatic sensing for next-generation wearable and ambient intelligence systems.
TinierHAR: Towards Ultra-Lightweight Deep Learning Models for Efficient Human Activity Recognition on Edge Devices
Jul 10, 2025Human Activity Recognition (HAR) on resource-constrained wearable devices demands inference models that harmonize accuracy with computational efficiency. This paper introduces TinierHAR, an ultra-lightweight deep learning architecture that synergizes residual depthwise separable convolutions, gated recurrent units (GRUs), and temporal aggregation to achieve SOTA efficiency without compromising performance. Evaluated across 14 public HAR datasets, TinierHAR reduces Parameters by 2.7x (vs. TinyHAR) and 43.3x (vs. DeepConvLSTM), and MACs by 6.4x and 58.6x, respectively, while maintaining the averaged F1-scores. Beyond quantitative gains, this work provides the first systematic ablation study dissecting the contributions of spatial-temporal components across proposed TinierHAR, prior SOTA TinyHAR, and the classical DeepConvLSTM, offering actionable insights for designing efficient HAR systems. We finally discussed the findings and suggested principled design guidelines for future efficient HAR. To catalyze edge-HAR research, we open-source all materials in this work for future benchmarking\footnote{https://github.com/zhaxidele/TinierHAR}
SImpHAR: Advancing impedance-based human activity recognition using 3D simulation and text-to-motion models
Jul 08, 2025


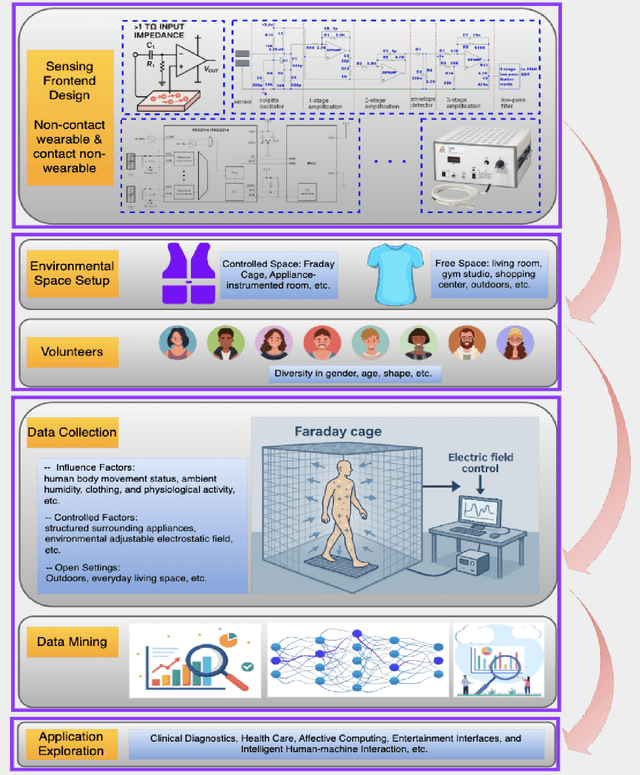
Human Activity Recognition (HAR) with wearable sensors is essential for applications in healthcare, fitness, and human-computer interaction. Bio-impedance sensing offers unique advantages for fine-grained motion capture but remains underutilized due to the scarcity of labeled data. We introduce SImpHAR, a novel framework addressing this limitation through two core contributions. First, we propose a simulation pipeline that generates realistic bio-impedance signals from 3D human meshes using shortest-path estimation, soft-body physics, and text-to-motion generation serving as a digital twin for data augmentation. Second, we design a two-stage training strategy with decoupled approach that enables broader activity coverage without requiring label-aligned synthetic data. We evaluate SImpHAR on our collected ImpAct dataset and two public benchmarks, showing consistent improvements over state-of-the-art methods, with gains of up to 22.3% and 21.8%, in terms of accuracy and macro F1 score, respectively. Our results highlight the promise of simulation-driven augmentation and modular training for impedance-based HAR.
Assessing the Impact of Sampling Irregularity in Time Series Data: Human Activity Recognition As A Case Study
Jan 25, 2025



Human activity recognition (HAR) ideally relies on data from wearable or environment-instrumented sensors sampled at regular intervals, enabling standard neural network models optimized for consistent time-series data as input. However, real-world sensor data often exhibits irregular sampling due to, for example, hardware constraints, power-saving measures, or communication delays, posing challenges for deployed static HAR models. This study assesses the impact of sampling irregularities on HAR by simulating irregular data through two methods: introducing slight inconsistencies in sampling intervals (timestamp variations) to mimic sensor jitter, and randomly removing data points (random dropout) to simulate missing values due to packet loss or sensor failure. We evaluate both discrete-time neural networks and continuous-time neural networks, which are designed to handle continuous-time data, on three public datasets. We demonstrate that timestamp variations do not significantly affect the performance of discrete-time neural networks, and the continuous-time neural network is also ineffective in addressing the challenges posed by irregular sampling, possibly due to limitations in modeling complex temporal patterns with missing data. Our findings underscore the necessity for new models or approaches that can robustly handle sampling irregularity in time-series data, like the reading in human activity recognition, paving the way for future research in this domain.
Enhancing Interpretability Through Loss-Defined Classification Objective in Structured Latent Spaces
Dec 11, 2024



Supervised machine learning often operates on the data-driven paradigm, wherein internal model parameters are autonomously optimized to converge predicted outputs with the ground truth, devoid of explicitly programming rules or a priori assumptions. Although data-driven methods have yielded notable successes across various benchmark datasets, they inherently treat models as opaque entities, thereby limiting their interpretability and yielding a lack of explanatory insights into their decision-making processes. In this work, we introduce Latent Boost, a novel approach that integrates advanced distance metric learning into supervised classification tasks, enhancing both interpretability and training efficiency. Thus during training, the model is not only optimized for classification metrics of the discrete data points but also adheres to the rule that the collective representation zones of each class should be sharply clustered. By leveraging the rich structural insights of intermediate model layer latent representations, Latent Boost improves classification interpretability, as demonstrated by higher Silhouette scores, while accelerating training convergence. These performance and latent structural benefits are achieved with minimum additional cost, making it broadly applicable across various datasets without requiring data-specific adjustments. Furthermore, Latent Boost introduces a new paradigm for aligning classification performance with improved model transparency to address the challenges of black-box models.