 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards certifiable AI in aviation: landscape, challenges, and opportunities
Sep 13, 2024Artificial Intelligence (AI) methods are powerful tools for various domains, including critical fields such as avionics, where certification is required to achieve and maintain an acceptable level of safety. General solutions for safety-critical systems must address three main questions: Is it suitable? What drives the system's decisions? Is it robust to errors/attacks? This is more complex in AI than in traditional methods. In this context, this paper presents a comprehensive mind map of formal AI certification in avionics. It highlights the challenges of certifying AI development with an example to emphasize the need for qualification beyond performance metrics.
MuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
Jun 06, 2024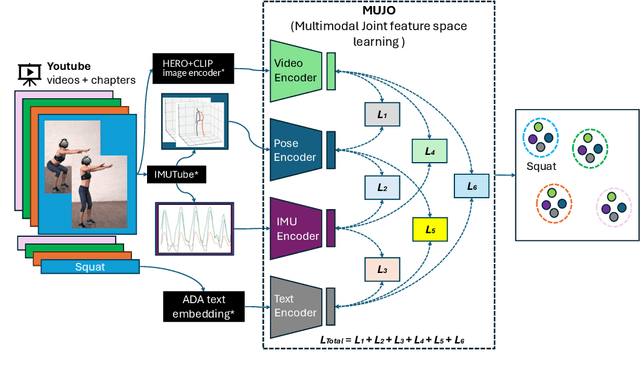
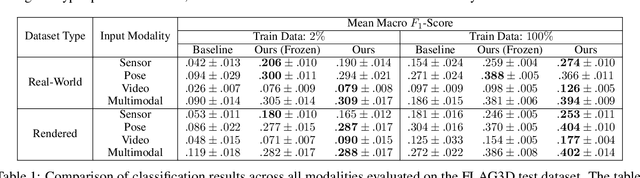
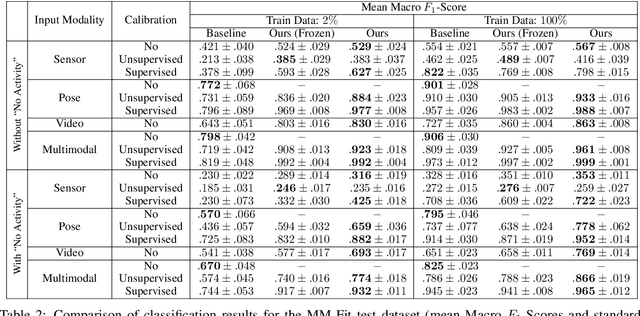
Human Activity Recognition is a longstanding problem in AI with applications in a broad range of areas: from healthcare, sports and fitness, security, and human computer interaction to robotics. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundational models (e.g., CLIP), can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g, in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. In this work, we show how we can improve HAR performance across different modalities using multimodal contrastive pretraining. Our approach MuJo (Multimodal Joint Feature Space Learning), learns a multimodal joint feature space with video, language, pose, and IMU sensor data. The proposed approach combines contrastive and multitask learning methods and analyzes different multitasking strategies for learning a compact shared representation. A large dataset with parallel video, language, pose, and sensor data points is also introduced to support the research, along with an analysis of the robustness of the multimodal joint space for modal-incomplete and low-resource data. On the MM-Fit dataset, our model achieves an impressive Macro F1-Score of up to 0.992 with only 2% of the train data and 0.999 when using all available training data for classification tasks. Moreover, in the scenario where the MM-Fit dataset is unseen, we demonstrate a generalization performance of up to 0.638.
CaptAinGlove: Capacitive and Inertial Fusion-Based Glove for Real-Time on Edge Hand Gesture Recognition for Drone Control
Jun 07, 2023We present CaptAinGlove, a textile-based, low-power (1.15Watts), privacy-conscious, real-time on-the-edge (RTE) glove-based solution with a tiny memory footprint (2MB), designed to recognize hand gestures used for drone control. We employ lightweight convolutional neural networks as the backbone models and a hierarchical multimodal fusion to reduce power consumption and improve accuracy. The system yields an F1-score of 80% for the offline evaluation of nine classes; eight hand gesture commands and null activity. For the RTE, we obtained an F1-score of 67% (one user).