 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Confusion: A Fine-grained Dialectical Examination of Human Activity Recognition Benchmark Datasets
Dec 12, 2024



The research of machine learning (ML) algorithms for human activity recognition (HAR) has made significant progress with publicly available datasets. However, most research prioritizes statistical metrics over examining negative sample details. While recent models like transformers have been applied to HAR datasets with limited success from the benchmark metrics, their counterparts have effectively solved problems on similar levels with near 100% accuracy. This raises questions about the limitations of current approaches. This paper aims to address these open questions by conducting a fine-grained inspection of six popular HAR benchmark datasets. We identified for some parts of the data, none of the six chosen state-of-the-art ML methods can correctly classify, denoted as the intersect of false classifications (IFC). Analysis of the IFC reveals several underlying problems, including ambiguous annotations, irregularities during recording execution, and misaligned transition periods. We contribute to the field by quantifying and characterizing annotated data ambiguities, providing a trinary categorization mask for dataset patching, and stressing potential improvements for future data collections.
Initial Investigation of Kolmogorov-Arnold Networks (KANs) as Feature Extractors for IMU Based Human Activity Recognition
Jun 16, 2024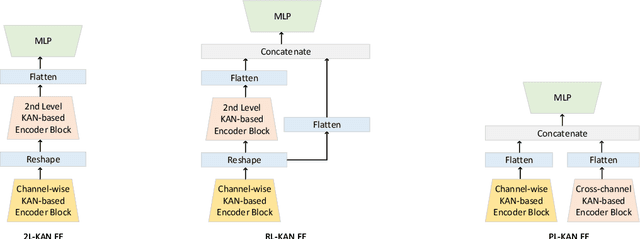
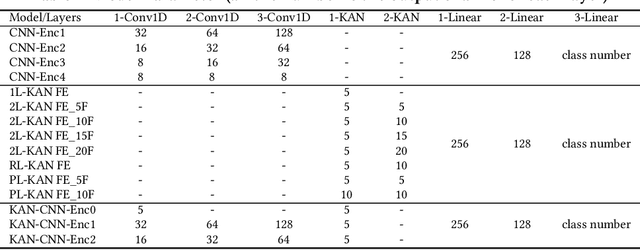
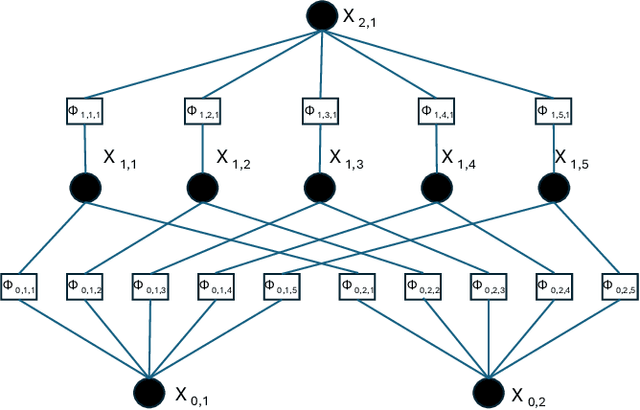
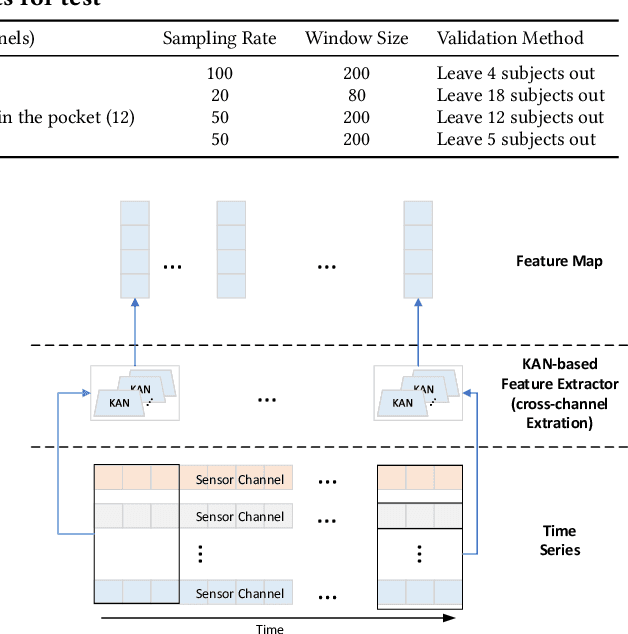
In this work, we explore the use of a novel neural network architecture, the Kolmogorov-Arnold Networks (KANs) as feature extractors for sensor-based (specifically IMU) Human Activity Recognition (HAR). Where conventional networks perform a parameterized weighted sum of the inputs at each node and then feed the result into a statically defined nonlinearity, KANs perform non-linear computations represented by B-SPLINES on the edges leading to each node and then just sum up the inputs at the node. Instead of learning weights, the system learns the spline parameters. In the original work, such networks have been shown to be able to more efficiently and exactly learn sophisticated real valued functions e.g. in regression or PDE solution. We hypothesize that such an ability is also advantageous for computing low-level features for IMU-based HAR. To this end, we have implemented KAN as the feature extraction architecture for IMU-based human activity recognition tasks, including four architecture variations. We present an initial performance investigation of the KAN feature extractor on four public HAR datasets. It shows that the KAN-based feature extractor outperforms CNN-based extractors on all datasets while being more parameter efficient.
Contrastive Left-Right Wearable Sensors (IMUs) Consistency Matching for HAR
Nov 21, 2023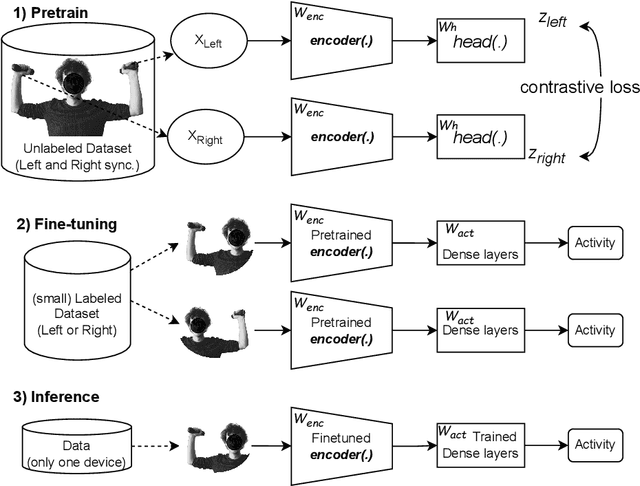
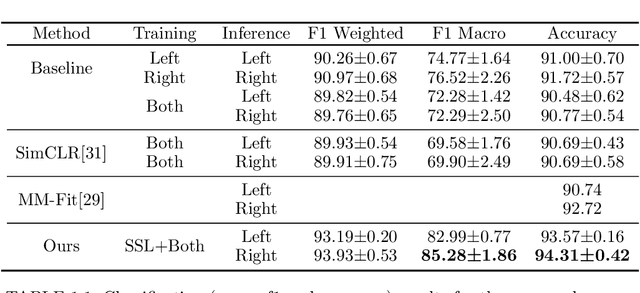
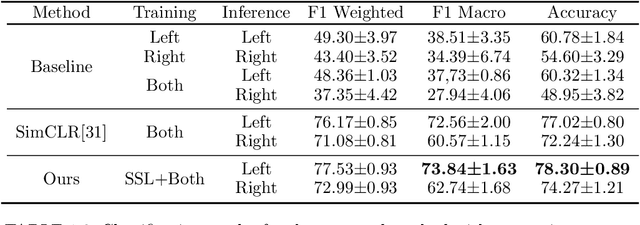
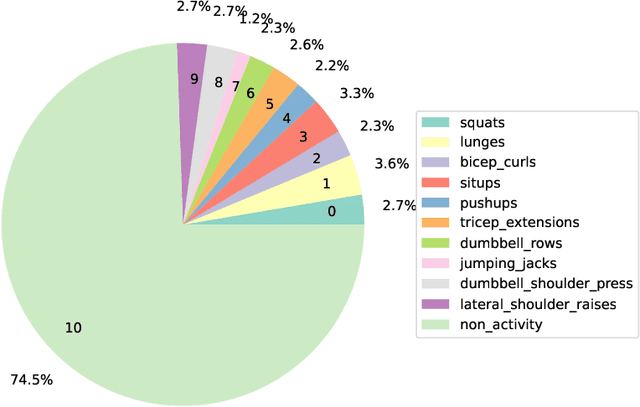
Machine learning algorithms are improving rapidly, but annotating training data remains a bottleneck for many applications. In this paper, we show how real data can be used for self-supervised learning without any transformations by taking advantage of the symmetry present in the activities. Our approach involves contrastive matching of two different sensors (left and right wrist or leg-worn IMUs) to make representations of co-occurring sensor data more similar and those of non-co-occurring sensor data more different. We test our approach on the Opportunity and MM-Fit datasets. In MM-Fit we show significant improvement over the baseline supervised and self-supervised method SimCLR, while for Opportunity there is significant improvement over the supervised baseline and slight improvement when compared to SimCLR. Moreover, our method improves supervised baselines even when using only a small amount of the data for training. Future work should explore under which conditions our method is beneficial for human activity recognition systems and other related applications.
Don't freeze: Finetune encoders for better Self-Supervised HAR
Jul 03, 2023Recently self-supervised learning has been proposed in the field of human activity recognition as a solution to the labelled data availability problem. The idea being that by using pretext tasks such as reconstruction or contrastive predictive coding, useful representations can be learned that then can be used for classification. Those approaches follow the pretrain, freeze and fine-tune procedure. In this paper we will show how a simple change - not freezing the representation - leads to substantial performance gains across pretext tasks. The improvement was found in all four investigated datasets and across all four pretext tasks and is inversely proportional to amount of labelled data. Moreover the effect is present whether the pretext task is carried on the Capture24 dataset or directly in unlabelled data of the target dataset.