 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinierHAR: Towards Ultra-Lightweight Deep Learning Models for Efficient Human Activity Recognition on Edge Devices
Jul 10, 2025Human Activity Recognition (HAR) on resource-constrained wearable devices demands inference models that harmonize accuracy with computational efficiency. This paper introduces TinierHAR, an ultra-lightweight deep learning architecture that synergizes residual depthwise separable convolutions, gated recurrent units (GRUs), and temporal aggregation to achieve SOTA efficiency without compromising performance. Evaluated across 14 public HAR datasets, TinierHAR reduces Parameters by 2.7x (vs. TinyHAR) and 43.3x (vs. DeepConvLSTM), and MACs by 6.4x and 58.6x, respectively, while maintaining the averaged F1-scores. Beyond quantitative gains, this work provides the first systematic ablation study dissecting the contributions of spatial-temporal components across proposed TinierHAR, prior SOTA TinyHAR, and the classical DeepConvLSTM, offering actionable insights for designing efficient HAR systems. We finally discussed the findings and suggested principled design guidelines for future efficient HAR. To catalyze edge-HAR research, we open-source all materials in this work for future benchmarking\footnote{https://github.com/zhaxidele/TinierHAR}
Human in the Latent Loop (HILL): Interactively Guiding Model Training Through Human Intuition
May 09, 2025Latent space representations are critical for understanding and improving the behavior of machine learning models, yet they often remain obscure and intricate. Understanding and exploring the latent space has the potential to contribute valuable human intuition and expertise about respective domains. In this work, we present HILL, an interactive framework allowing users to incorporate human intuition into the model training by interactively reshaping latent space representations. The modifications are infused into the model training loop via a novel approach inspired by knowledge distillation, treating the user's modifications as a teacher to guide the model in reshaping its intrinsic latent representation. The process allows the model to converge more effectively and overcome inefficiencies, as well as provide beneficial insights to the user. We evaluated HILL in a user study tasking participants to train an optimal model, closely observing the employed strategies. The results demonstrated that human-guided latent space modifications enhance model performance while maintaining generalization, yet also revealing the risks of including user biases. Our work introduces a novel human-AI interaction paradigm that infuses human intuition into model training and critically examines the impact of human intervention on training strategies and potential biases.
Beyond Confusion: A Fine-grained Dialectical Examination of Human Activity Recognition Benchmark Datasets
Dec 12, 2024



The research of machine learning (ML) algorithms for human activity recognition (HAR) has made significant progress with publicly available datasets. However, most research prioritizes statistical metrics over examining negative sample details. While recent models like transformers have been applied to HAR datasets with limited success from the benchmark metrics, their counterparts have effectively solved problems on similar levels with near 100% accuracy. This raises questions about the limitations of current approaches. This paper aims to address these open questions by conducting a fine-grained inspection of six popular HAR benchmark datasets. We identified for some parts of the data, none of the six chosen state-of-the-art ML methods can correctly classify, denoted as the intersect of false classifications (IFC). Analysis of the IFC reveals several underlying problems, including ambiguous annotations, irregularities during recording execution, and misaligned transition periods. We contribute to the field by quantifying and characterizing annotated data ambiguities, providing a trinary categorization mask for dataset patching, and stressing potential improvements for future data collections.
Enhancing Interpretability Through Loss-Defined Classification Objective in Structured Latent Spaces
Dec 11, 2024



Supervised machine learning often operates on the data-driven paradigm, wherein internal model parameters are autonomously optimized to converge predicted outputs with the ground truth, devoid of explicitly programming rules or a priori assumptions. Although data-driven methods have yielded notable successes across various benchmark datasets, they inherently treat models as opaque entities, thereby limiting their interpretability and yielding a lack of explanatory insights into their decision-making processes. In this work, we introduce Latent Boost, a novel approach that integrates advanced distance metric learning into supervised classification tasks, enhancing both interpretability and training efficiency. Thus during training, the model is not only optimized for classification metrics of the discrete data points but also adheres to the rule that the collective representation zones of each class should be sharply clustered. By leveraging the rich structural insights of intermediate model layer latent representations, Latent Boost improves classification interpretability, as demonstrated by higher Silhouette scores, while accelerating training convergence. These performance and latent structural benefits are achieved with minimum additional cost, making it broadly applicable across various datasets without requiring data-specific adjustments. Furthermore, Latent Boost introduces a new paradigm for aligning classification performance with improved model transparency to address the challenges of black-box models.
Spend More to Save More (SM2): An Energy-Aware Implementation of Successive Halving for Sustainable Hyperparameter Optimization
Dec 11, 2024


A fundamental step in the development of machine learning models commonly involves the tuning of hyperparameters, often leading to multiple model training runs to work out the best-performing configuration. As machine learning tasks and models grow in complexity, there is an escalating need for solutions that not only improve performance but also address sustainability concerns. Existing strategies predominantly focus on maximizing the performance of the model without considering energy efficiency. To bridge this gap, in this paper, we introduce Spend More to Save More (SM2), an energy-aware hyperparameter optimization implementation based on the widely adopted successive halving algorithm. Unlike conventional approaches including energy-intensive testing of individual hyperparameter configurations, SM2 employs exploratory pretraining to identify inefficient configurations with minimal energy expenditure. Incorporating hardware characteristics and real-time energy consumption tracking, SM2 identifies an optimal configuration that not only maximizes the performance of the model but also enables energy-efficient training. Experimental validations across various datasets, models, and hardware setups confirm the efficacy of SM2 to prevent the waste of energy during the training of hyperparameter configurations.
Leveraging Hybrid Intelligence Towards Sustainable and Energy-Efficient Machine Learning
Jul 15, 2024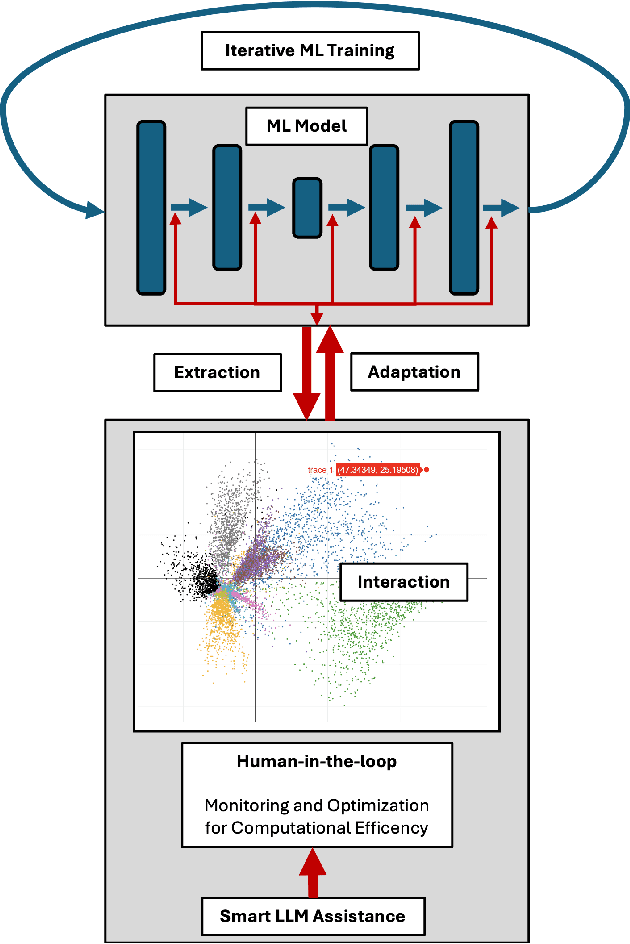

Hybrid intelligence aims to enhance decision-making, problem-solving, and overall system performance by combining the strengths of both, human cognitive abilities and artificial intelligence. With the rise of Large Language Models (LLM), progressively participating as smart agents to accelerate machine learning development, Hybrid Intelligence is becoming an increasingly important topic for effective interaction between humans and machines. This paper presents an approach to leverage Hybrid Intelligence towards sustainable and energy-aware machine learning. When developing machine learning models, final model performance commonly rules the optimization process while the efficiency of the process itself is often neglected. Moreover, in recent times, energy efficiency has become equally crucial due to the significant environmental impact of complex and large-scale computational processes. The contribution of this work covers the interactive inclusion of secondary knowledge sources through Human-in-the-loop (HITL) and LLM agents to stress out and further resolve inefficiencies in the machine learning development process.