 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleTalker: One-shot Style-based Audio-driven Talking Head Video Generation
Aug 23, 2022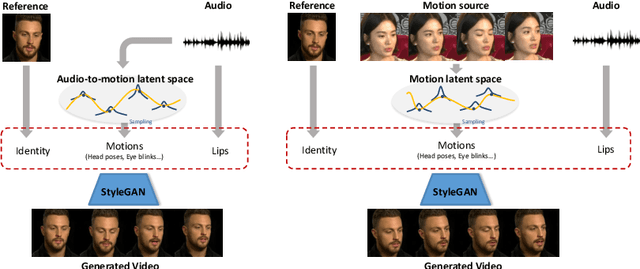

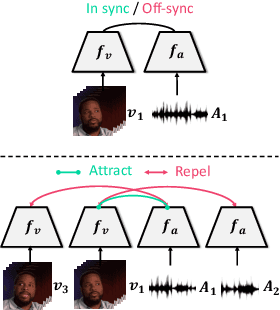

We propose StyleTalker, a novel audio-driven talking head generation model that can synthesize a video of a talking person from a single reference image with accurately audio-synced lip shapes, realistic head poses, and eye blinks. Specifically, by leveraging a pretrained image generator and an image encoder, we estimate the latent codes of the talking head video that faithfully reflects the given audio. This is made possible with several newly devised components: 1) A contrastive lip-sync discriminator for accurate lip synchronization, 2) A conditional sequential variational autoencoder that learns the latent motion space disentangled from the lip movements, such that we can independently manipulate the motions and lip movements while preserving the identity. 3) An auto-regressive prior augmented with normalizing flow to learn a complex audio-to-motion multi-modal latent space. Equipped with these components, StyleTalker can generate talking head videos not only in a motion-controllable way when another motion source video is given but also in a completely audio-driven manner by inferring realistic motions from the input audio. Through extensive experiments and user studies, we show that our model is able to synthesize talking head videos with impressive perceptual quality which are accurately lip-synced with the input audios, largely outperforming state-of-the-art baselines.
Rapid Structural Pruning of Neural Networks with Set-based Task-Adaptive Meta-Pruning
Jun 22, 2020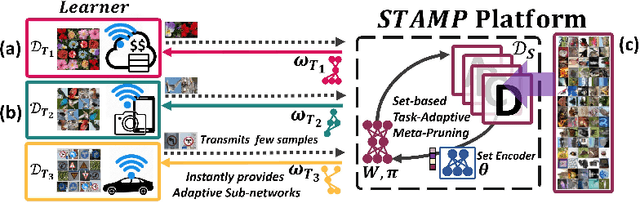
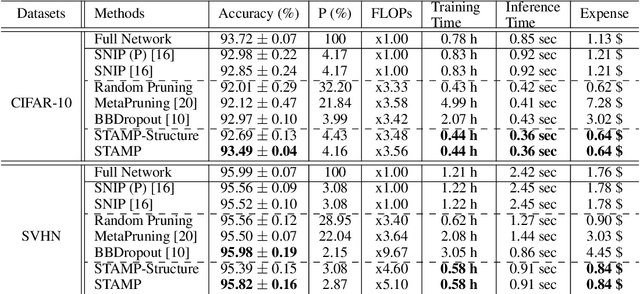


As deep neural networks are growing in size and being increasingly deployed to more resource-limited devices, there has been a recent surge of interest in network pruning methods, which aim to remove less important weights or activations of a given network. A common limitation of most existing pruning techniques, is that they require pre-training of the network at least once before pruning, and thus we can benefit from reduction in memory and computation only at the inference time. However, reducing the training cost of neural networks with rapid structural pruning may be beneficial either to minimize monetary cost with cloud computing or to enable on-device learning on a resource-limited device. Recently introduced random-weight pruning approaches can eliminate the needs of pretraining, but they often obtain suboptimal performance over conventional pruning techniques and also does not allow for faster training since they perform unstructured pruning. To overcome their limitations, we propose Set-based Task-Adaptive Meta Pruning (STAMP), which task-adaptively prunes a network pretrained on a large reference dataset by generating a pruning mask on it as a function of the target dataset. To ensure maximum performance improvements on the target task, we meta-learn the mask generator over different subsets of the reference dataset, such that it can generalize well to any unseen datasets within a few gradient steps of training. We validate STAMP against recent advanced pruning methods on benchmark datasets, on which it not only obtains significantly improved compression rates over the baselines at similar accuracy, but also orders of magnitude faster training speed.