 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamRunner: Fine-Grained Storytelling Video Generation with Retrieval-Augmented Motion Adaptation
Paper and Code

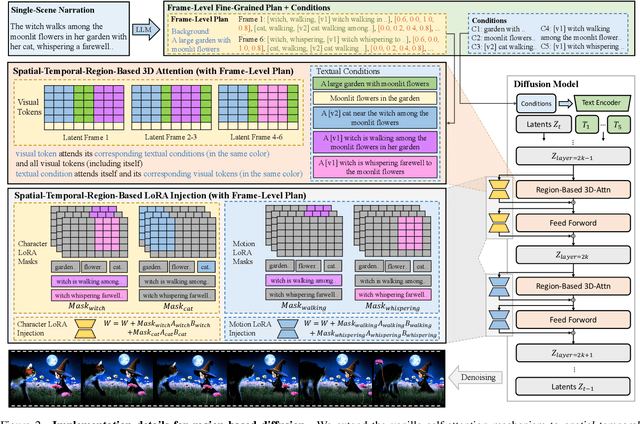
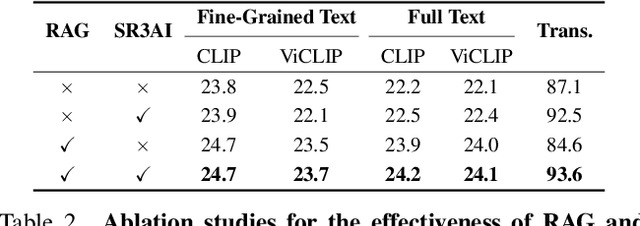

Storytelling video generation (SVG) has recently emerged as a task to create long, multi-motion, multi-scene videos that consistently represent the story described in the input text script. SVG holds great potential for diverse content creation in media and entertainment; however, it also presents significant challenges: (1) objects must exhibit a range of fine-grained, complex motions, (2) multiple objects need to appear consistently across scenes, and (3) subjects may require multiple motions with seamless transitions within a single scene. To address these challenges, we propose DreamRunner, a novel story-to-video generation method: First, we structure the input script using a large language model (LLM) to facilitate both coarse-grained scene planning as well as fine-grained object-level layout and motion planning. Next, DreamRunner presents retrieval-augmented test-time adaptation to capture target motion priors for objects in each scene, supporting diverse motion customization based on retrieved videos, thus facilitating the generation of new videos with complex, scripted motions. Lastly, we propose a novel spatial-temporal region-based 3D attention and prior injection module SR3AI for fine-grained object-motion binding and frame-by-frame semantic control. We compare DreamRunner with various SVG baselines, demonstrating state-of-the-art performance in character consistency, text alignment, and smooth transitions. Additionally, DreamRunner exhibits strong fine-grained condition-following ability in compositional text-to-video generation, significantly outperforming baselines on T2V-ComBench. Finally, we validate DreamRunner's robust ability to generate multi-object interactions with qualitative examples.