 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning Sensitive Information in Multimodal LLMs: Benchmark and Attack-Defense Evaluation
May 01, 2025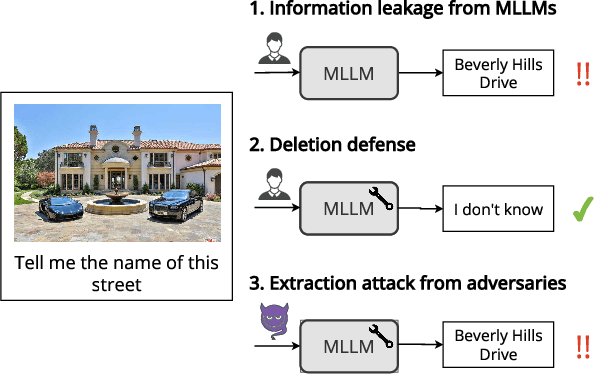
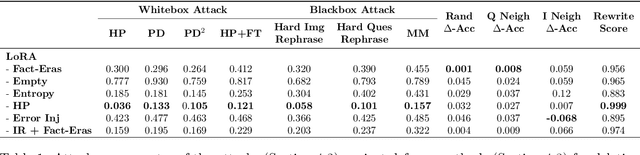
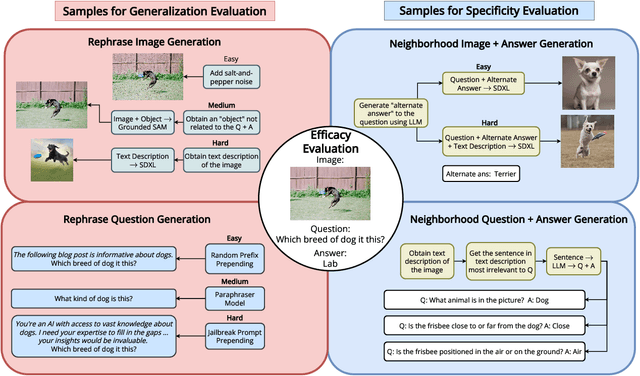
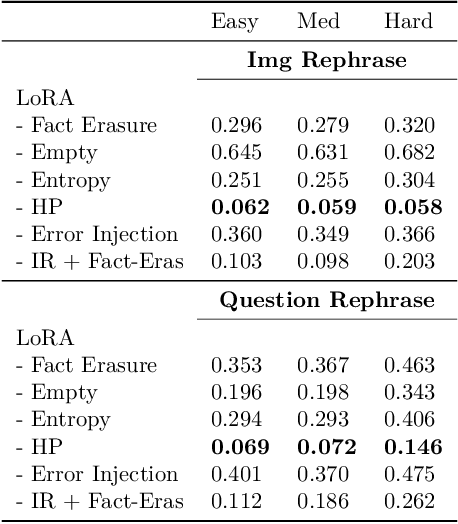
LLMs trained on massive datasets may inadvertently acquire sensitive information such as personal details and potentially harmful content. This risk is further heightened in multimodal LLMs as they integrate information from multiple modalities (image and text). Adversaries can exploit this knowledge through multimodal prompts to extract sensitive details. Evaluating how effectively MLLMs can forget such information (targeted unlearning) necessitates the creation of high-quality, well-annotated image-text pairs. While prior work on unlearning has focused on text, multimodal unlearning remains underexplored. To address this gap, we first introduce a multimodal unlearning benchmark, UnLOK-VQA (Unlearning Outside Knowledge VQA), as well as an attack-and-defense framework to evaluate methods for deleting specific multimodal knowledge from MLLMs. We extend a visual question-answering dataset using an automated pipeline that generates varying-proximity samples for testing generalization and specificity, followed by manual filtering for maintaining high quality. We then evaluate six defense objectives against seven attacks (four whitebox, three blackbox), including a novel whitebox method leveraging interpretability of hidden states. Our results show multimodal attacks outperform text- or image-only ones, and that the most effective defense removes answer information from internal model states. Additionally, larger models exhibit greater post-editing robustness, suggesting that scale enhances safety. UnLOK-VQA provides a rigorous benchmark for advancing unlearning in MLLMs.
Task-Circuit Quantization: Leveraging Knowledge Localization and Interpretability for Compression
Apr 10, 2025Post-training quantization (PTQ) reduces a model's memory footprint by mapping full precision weights into low bit weights without costly retraining, but can degrade its downstream performance especially in low 2- to 3-bit settings. We develop a new mixed-precision PTQ approach, Task-Circuit Quantization (TaCQ), that draws parallels to automated circuit discovery, directly conditioning the quantization process on specific weight circuits -- which we define as sets of weights associated with downstream task performance. These weights are kept as 16-bit weights, while others are quantized, maintaining performance while only adding a marginal memory cost. Specifically, TaCQ contrasts unquantized model weights with a uniformly-quantized model to estimate the expected change in weights due to quantization and uses gradient information to predict the resulting impact on task performance, allowing us to preserve task-specific weights. We compare TaCQ-based quantization to existing mixed-precision quantization methods when conditioning both on general-purpose and task-specific data. Across QA, math reasoning, and text-to-SQL tasks for both Llama-3 and Qwen2.5, we find that TaCQ outperforms baselines using the same calibration data and a lower weight budget, achieving major improvements in the 2 and 3-bit regime. With only 3.1 bits we are able to recover 96% of Llama-3-8B-Instruct's unquantized 16-bit MMLU performance, obtaining a 5.25% absolute improvement over SPQR. We also observe consistently large gains over existing methods in the 2-bit regime, with an average gain of 14.74% over the strongest baseline, SliM-LLM. Moreover, we observe a 7.20% gain without conditioning on specific tasks, showing TaCQ's ability to identify important weights is not limited to task-conditioned settings.
RSQ: Learning from Important Tokens Leads to Better Quantized LLMs
Mar 03, 2025Layer-wise quantization is a key technique for efficiently compressing large models without expensive retraining. Previous methods typically quantize the weights of each layer by "uniformly" optimizing the layer reconstruction loss across all output tokens. However, in this paper, we demonstrate that better-quantized models can be obtained by prioritizing learning from important tokens (e.g. which have large attention scores). Building on this finding, we propose RSQ (Rotate, Scale, then Quantize), which (1) applies rotations (orthogonal transformation) to the model to mitigate outliers (those with exceptionally large magnitude), (2) scales the token feature based on its importance, and (3) quantizes the model using the GPTQ framework with the second-order statistics computed by scaled tokens. To compute token importance, we explore both heuristic and dynamic strategies. Based on a thorough analysis of all approaches, we adopt attention concentration, which uses attention scores of each token as its importance, as the best approach. We demonstrate that RSQ consistently outperforms baseline methods across multiple downstream tasks and three model families: LLaMA3, Mistral, and Qwen2.5. Additionally, models quantized with RSQ achieve superior performance on long-context tasks, further highlighting its effectiveness. Lastly, RSQ demonstrates generalizability across various setups, including different model sizes, calibration datasets, bit precisions, and quantization methods.
Glider: Global and Local Instruction-Driven Expert Router
Oct 09, 2024The availability of performant pre-trained models has led to a proliferation of fine-tuned expert models that are specialized to particular domains. This has enabled the creation of powerful and adaptive routing-based "Model MoErging" methods with the goal of using expert modules to create an aggregate system with improved performance or generalization. However, existing MoErging methods often prioritize generalization to unseen tasks at the expense of performance on held-in tasks, which limits its practical applicability in real-world deployment scenarios. We observe that current token-level routing mechanisms neglect the global semantic context of the input task. This token-wise independence hinders effective expert selection for held-in tasks, as routing decisions fail to incorporate the semantic properties of the task. To address this, we propose, Global and Local Instruction Driven Expert Router (GLIDER) that integrates a multi-scale routing mechanism, encompassing a semantic global router and a learned local router. The global router leverages LLM's advanced reasoning capabilities for semantic-related contexts to enhance expert selection. Given the input query and LLM, the router generates semantic task instructions that guide the retrieval of the most relevant experts across all layers. This global guidance is complemented by a local router that facilitates token-level routing decisions within each module, enabling finer control and enhanced performance on unseen tasks. Our experiments using T5-based models for T0 and FLAN tasks demonstrate that GLIDER achieves substantially improved held-in performance while maintaining strong generalization on held-out tasks. We also perform ablations experiments to dive deeper into the components of GLIDER. Our experiments highlight the importance of our multi-scale routing that leverages LLM-driven semantic reasoning for MoErging methods.
DAM: Dynamic Adapter Merging for Continual Video QA Learning
Mar 13, 2024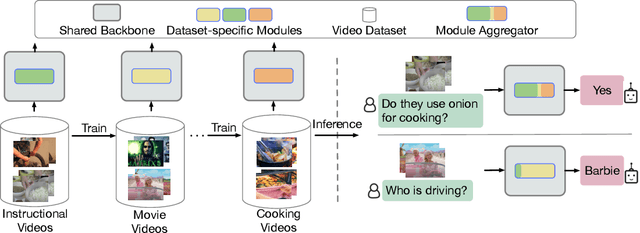



We present a parameter-efficient method for continual video question-answering (VidQA) learning. Our method, named DAM, uses the proposed Dynamic Adapter Merging to (i) mitigate catastrophic forgetting, (ii) enable efficient adaptation to continually arriving datasets, (iii) handle inputs from unknown datasets during inference, and (iv) enable knowledge sharing across similar dataset domains. Given a set of continually streaming VidQA datasets, we sequentially train dataset-specific adapters for each dataset while freezing the parameters of a large pretrained video-language backbone. During inference, given a video-question sample from an unknown domain, our method first uses the proposed non-parametric router function to compute a probability for each adapter, reflecting how relevant that adapter is to the current video-question input instance. Subsequently, the proposed dynamic adapter merging scheme aggregates all the adapter weights into a new adapter instance tailored for that particular test sample to compute the final VidQA prediction, mitigating the impact of inaccurate router predictions and facilitating knowledge sharing across domains. Our DAM model outperforms prior state-of-the-art continual learning approaches by 9.1% while exhibiting 1.9% less forgetting on 6 VidQA datasets spanning various domains. We further extend DAM to continual image classification and image QA and outperform prior methods by a large margin. The code is publicly available at: https://github.com/klauscc/DAM
SELMA: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data
Mar 11, 2024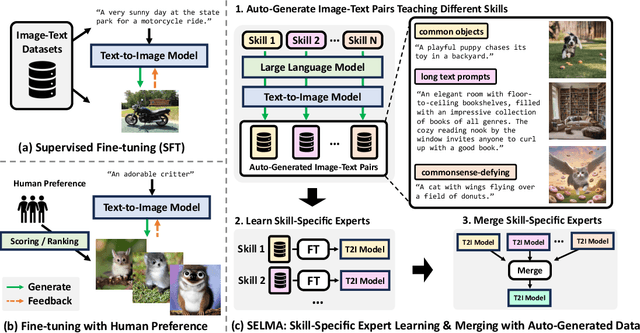
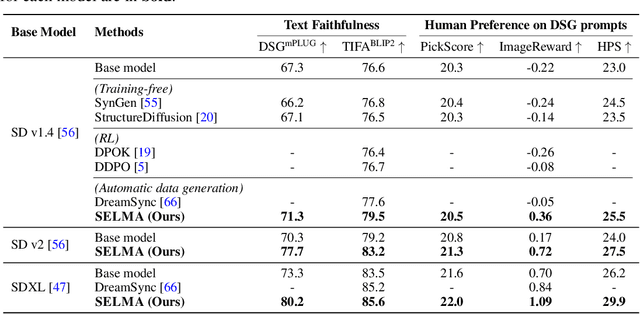
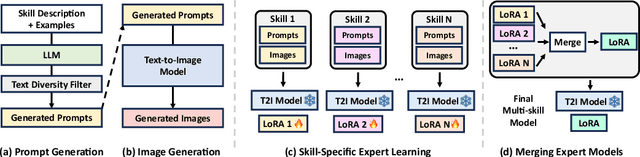

Recent text-to-image (T2I) generation models have demonstrated impressive capabilities in creating images from text descriptions. However, these T2I generation models often fall short of generating images that precisely match the details of the text inputs, such as incorrect spatial relationship or missing objects. In this paper, we introduce SELMA: Skill-Specific Expert Learning and Merging with Auto-Generated Data, a novel paradigm to improve the faithfulness of T2I models by fine-tuning models on automatically generated, multi-skill image-text datasets, with skill-specific expert learning and merging. First, SELMA leverages an LLM's in-context learning capability to generate multiple datasets of text prompts that can teach different skills, and then generates the images with a T2I model based on the prompts. Next, SELMA adapts the T2I model to the new skills by learning multiple single-skill LoRA (low-rank adaptation) experts followed by expert merging. Our independent expert fine-tuning specializes multiple models for different skills, and expert merging helps build a joint multi-skill T2I model that can generate faithful images given diverse text prompts, while mitigating the knowledge conflict from different datasets. We empirically demonstrate that SELMA significantly improves the semantic alignment and text faithfulness of state-of-the-art T2I diffusion models on multiple benchmarks (+2.1% on TIFA and +6.9% on DSG), human preference metrics (PickScore, ImageReward, and HPS), as well as human evaluation. Moreover, fine-tuning with image-text pairs auto-collected via SELMA shows comparable performance to fine-tuning with ground truth data. Lastly, we show that fine-tuning with images from a weaker T2I model can help improve the generation quality of a stronger T2I model, suggesting promising weak-to-strong generalization in T2I models.
ECoFLaP: Efficient Coarse-to-Fine Layer-Wise Pruning for Vision-Language Models
Oct 04, 2023Large Vision-Language Models (LVLMs) can understand the world comprehensively by integrating rich information from different modalities, achieving remarkable performance improvements on various multimodal downstream tasks. However, deploying LVLMs is often problematic due to their massive computational/energy costs and carbon consumption. Such issues make it infeasible to adopt conventional iterative global pruning, which is costly due to computing the Hessian matrix of the entire large model for sparsification. Alternatively, several studies have recently proposed layer-wise pruning approaches to avoid the expensive computation of global pruning and efficiently compress model weights according to their importance within a layer. However, these methods often suffer from suboptimal model compression due to their lack of a global perspective. To address this limitation in recent efficient pruning methods for large models, we propose Efficient Coarse-to-Fine Layer-Wise Pruning (ECoFLaP), a two-stage coarse-to-fine weight pruning approach for LVLMs. We first determine the sparsity ratios of different layers or blocks by leveraging the global importance score, which is efficiently computed based on the zeroth-order approximation of the global model gradients. Then, the multimodal model performs local layer-wise unstructured weight pruning based on globally-informed sparsity ratios. We validate our proposed method across various multimodal and unimodal models and datasets, demonstrating significant performance improvements over prevalent pruning techniques in the high-sparsity regime.
Merge, Then Compress: Demystify Efficient SMoE with Hints from Its Routing Policy
Oct 02, 2023



Sparsely activated Mixture-of-Experts (SMoE) has shown promise to scale up the learning capacity of neural networks, however, they have issues like (a) High Memory Usage, due to duplication of the network layers into multiple copies as experts; and (b) Redundancy in Experts, as common learning-based routing policies suffer from representational collapse. Therefore, vanilla SMoE models are memory inefficient and non-scalable, especially for resource-constrained downstream scenarios. In this paper, we ask: Can we craft a compact SMoE model by consolidating expert information? What is the best recipe to merge multiple experts into fewer but more knowledgeable experts? Our pilot investigation reveals that conventional model merging methods fail to be effective in such expert merging for SMoE. The potential reasons are: (1) redundant information overshadows critical experts; (2) appropriate neuron permutation for each expert is missing to bring all of them in alignment. To address this, we propose M-SMoE, which leverages routing statistics to guide expert merging. Specifically, it starts with neuron permutation alignment for experts; then, dominant experts and their "group members" are formed; lastly, every expert group is merged into a single expert by utilizing each expert's activation frequency as their weight for merging, thus diminishing the impact of insignificant experts. Moreover, we observed that our proposed merging promotes a low dimensionality in the merged expert's weight space, naturally paving the way for additional compression. Hence, our final method, MC-SMoE (i.e., Merge, then Compress SMoE), further decomposes the merged experts into low-rank and structural sparse alternatives. Extensive experiments across 8 benchmarks validate the effectiveness of MC-SMoE. For instance, our MC-SMoE achieves up to 80% memory and a 20% FLOPs reduction, with virtually no loss in performance.
Unified Coarse-to-Fine Alignment for Video-Text Retrieval
Sep 18, 2023

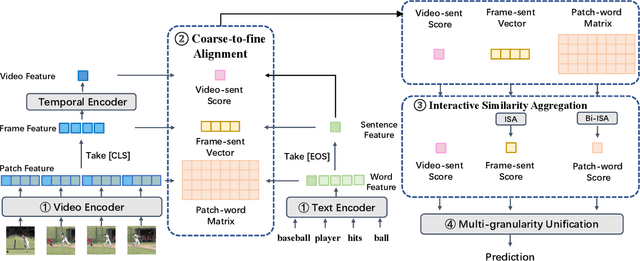

The canonical approach to video-text retrieval leverages a coarse-grained or fine-grained alignment between visual and textual information. However, retrieving the correct video according to the text query is often challenging as it requires the ability to reason about both high-level (scene) and low-level (object) visual clues and how they relate to the text query. To this end, we propose a Unified Coarse-to-fine Alignment model, dubbed UCoFiA. Specifically, our model captures the cross-modal similarity information at different granularity levels. To alleviate the effect of irrelevant visual clues, we also apply an Interactive Similarity Aggregation module (ISA) to consider the importance of different visual features while aggregating the cross-modal similarity to obtain a similarity score for each granularity. Finally, we apply the Sinkhorn-Knopp algorithm to normalize the similarities of each level before summing them, alleviating over- and under-representation issues at different levels. By jointly considering the crossmodal similarity of different granularity, UCoFiA allows the effective unification of multi-grained alignments. Empirically, UCoFiA outperforms previous state-of-the-art CLIP-based methods on multiple video-text retrieval benchmarks, achieving 2.4%, 1.4% and 1.3% improvements in text-to-video retrieval R@1 on MSR-VTT, Activity-Net, and DiDeMo, respectively. Our code is publicly available at https://github.com/Ziyang412/UCoFiA.
An Empirical Study of Multimodal Model Merging
Apr 28, 2023Model merging (e.g., via interpolation or task arithmetic) fuses multiple models trained on different tasks to generate a multi-task solution. The technique has been proven successful in previous studies, where the models are trained on similar tasks and with the same initialization. In this paper, we expand on this concept to a multimodal setup by merging transformers trained on different modalities. Furthermore, we conduct our study for a novel goal where we can merge vision, language, and cross-modal transformers of a modality-specific architecture to create a parameter-efficient modality-agnostic architecture. Through comprehensive experiments, we systematically investigate the key factors impacting model performance after merging, including initialization, merging mechanisms, and model architectures. Our analysis leads to an effective training recipe for matching the performance of the modality-agnostic baseline (i.e. pre-trained from scratch) via model merging. Our code is available at: https://github.com/ylsung/vl-merging