 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2M-Zero: Zero-Pair Time-Aligned Video-to-Music Generation
Mar 11, 2026Generating music that temporally aligns with video events is challenging for existing text-to-music models, which lack fine-grained temporal control. We introduce V2M-Zero, a zero-pair video-to-music generation approach that outputs time-aligned music for video. Our method is motivated by a key observation: temporal synchronization requires matching when and how much change occurs, not what changes. While musical and visual events differ semantically, they exhibit shared temporal structure that can be captured independently within each modality. We capture this structure through event curves computed from intra-modal similarity using pretrained music and video encoders. By measuring temporal change within each modality independently, these curves provide comparable representations across modalities. This enables a simple training strategy: fine-tune a text-to-music model on music-event curves, then substitute video-event curves at inference without cross-modal training or paired data. Across OES-Pub, MovieGenBench-Music, and AIST++, V2M-Zero achieves substantial gains over paired-data baselines: 5-21% higher audio quality, 13-15% better semantic alignment, 21-52% improved temporal synchronization, and 28% higher beat alignment on dance videos. We find similar results via a large crowd-source subjective listening test. Overall, our results validate that temporal alignment through within-modality features, rather than paired cross-modal supervision, is effective for video-to-music generation. Results are available at https://genjib.github.io/v2m_zero/
SiLVR: A Simple Language-based Video Reasoning Framework
May 30, 2025Recent advances in test-time optimization have led to remarkable reasoning capabilities in Large Language Models (LLMs), enabling them to solve highly complex problems in math and coding. However, the reasoning capabilities of multimodal LLMs (MLLMs) still significantly lag, especially for complex video-language tasks. To address this issue, we present SiLVR, a Simple Language-based Video Reasoning framework that decomposes complex video understanding into two stages. In the first stage, SiLVR transforms raw video into language-based representations using multisensory inputs, such as short clip captions and audio/speech subtitles. In the second stage, language descriptions are fed into a powerful reasoning LLM to solve complex video-language understanding tasks. To handle long-context multisensory inputs, we use an adaptive token reduction scheme, which dynamically determines the temporal granularity with which to sample the tokens. Our simple, modular, and training-free video reasoning framework achieves the best-reported results on Video-MME (long), Video-MMMU (comprehension), Video-MMLU, CGBench, and EgoLife. Furthermore, our empirical study focused on video reasoning capabilities shows that, despite not being explicitly trained on video, strong reasoning LLMs can effectively aggregate multisensory input information from video, speech, and audio for complex temporal, causal, long-context, and knowledge acquisition reasoning tasks in video. Code is available at https://github.com/CeeZh/SILVR.
Zero-Shot Audio-Visual Editing via Cross-Modal Delta Denoising
Mar 26, 2025
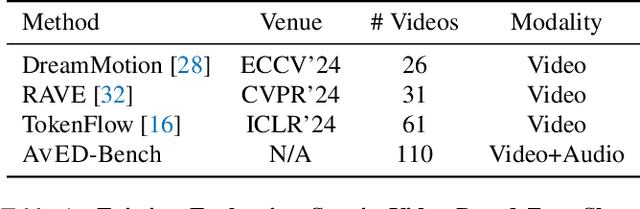
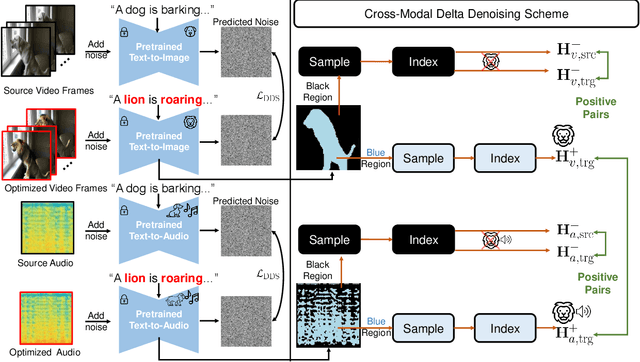
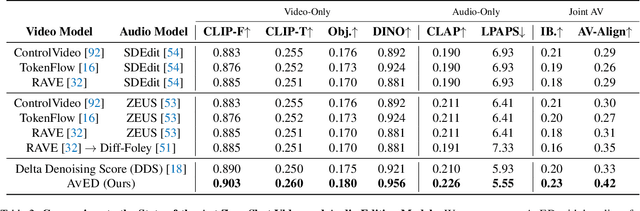
In this paper, we introduce zero-shot audio-video editing, a novel task that requires transforming original audio-visual content to align with a specified textual prompt without additional model training. To evaluate this task, we curate a benchmark dataset, AvED-Bench, designed explicitly for zero-shot audio-video editing. AvED-Bench includes 110 videos, each with a 10-second duration, spanning 11 categories from VGGSound. It offers diverse prompts and scenarios that require precise alignment between auditory and visual elements, enabling robust evaluation. We identify limitations in existing zero-shot audio and video editing methods, particularly in synchronization and coherence between modalities, which often result in inconsistent outcomes. To address these challenges, we propose AvED, a zero-shot cross-modal delta denoising framework that leverages audio-video interactions to achieve synchronized and coherent edits. AvED demonstrates superior results on both AvED-Bench and the recent OAVE dataset to validate its generalization capabilities. Results are available at https://genjib.github.io/project_page/AVED/index.html
VMAS: Video-to-Music Generation via Semantic Alignment in Web Music Videos
Sep 11, 2024We present a framework for learning to generate background music from video inputs. Unlike existing works that rely on symbolic musical annotations, which are limited in quantity and diversity, our method leverages large-scale web videos accompanied by background music. This enables our model to learn to generate realistic and diverse music. To accomplish this goal, we develop a generative video-music Transformer with a novel semantic video-music alignment scheme. Our model uses a joint autoregressive and contrastive learning objective, which encourages the generation of music aligned with high-level video content. We also introduce a novel video-beat alignment scheme to match the generated music beats with the low-level motions in the video. Lastly, to capture fine-grained visual cues in a video needed for realistic background music generation, we introduce a new temporal video encoder architecture, allowing us to efficiently process videos consisting of many densely sampled frames. We train our framework on our newly curated DISCO-MV dataset, consisting of 2.2M video-music samples, which is orders of magnitude larger than any prior datasets used for video music generation. Our method outperforms existing approaches on the DISCO-MV and MusicCaps datasets according to various music generation evaluation metrics, including human evaluation. Results are available at https://genjib.github.io/project_page/VMAs/index.html
Siamese Vision Transformers are Scalable Audio-visual Learners
Mar 28, 2024Traditional audio-visual methods rely on independent audio and visual backbones, which is costly and not scalable. In this work, we investigate using an audio-visual siamese network (AVSiam) for efficient and scalable audio-visual pretraining. Our framework uses a single shared vision transformer backbone to process audio and visual inputs, improving its parameter efficiency, reducing the GPU memory footprint, and allowing us to scale our method to larger datasets and model sizes. We pretrain our model using a contrastive audio-visual matching objective with a multi-ratio random masking scheme, which enables our model to process larger audio-visual instance batches, helpful for contrastive learning. Unlike prior audio-visual methods, our method can robustly handle audio, visual, and audio-visual inputs with a single shared ViT backbone. Furthermore, despite using the shared backbone for both modalities, AVSiam achieves competitive or even better results than prior methods on AudioSet and VGGSound for audio-visual classification and retrieval. Our code is available at https://github.com/GenjiB/AVSiam
DAM: Dynamic Adapter Merging for Continual Video QA Learning
Mar 13, 2024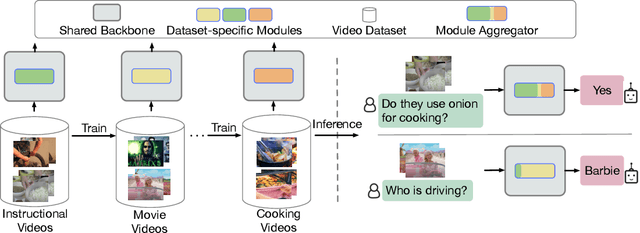



We present a parameter-efficient method for continual video question-answering (VidQA) learning. Our method, named DAM, uses the proposed Dynamic Adapter Merging to (i) mitigate catastrophic forgetting, (ii) enable efficient adaptation to continually arriving datasets, (iii) handle inputs from unknown datasets during inference, and (iv) enable knowledge sharing across similar dataset domains. Given a set of continually streaming VidQA datasets, we sequentially train dataset-specific adapters for each dataset while freezing the parameters of a large pretrained video-language backbone. During inference, given a video-question sample from an unknown domain, our method first uses the proposed non-parametric router function to compute a probability for each adapter, reflecting how relevant that adapter is to the current video-question input instance. Subsequently, the proposed dynamic adapter merging scheme aggregates all the adapter weights into a new adapter instance tailored for that particular test sample to compute the final VidQA prediction, mitigating the impact of inaccurate router predictions and facilitating knowledge sharing across domains. Our DAM model outperforms prior state-of-the-art continual learning approaches by 9.1% while exhibiting 1.9% less forgetting on 6 VidQA datasets spanning various domains. We further extend DAM to continual image classification and image QA and outperform prior methods by a large margin. The code is publicly available at: https://github.com/klauscc/DAM
Vision Transformers are Parameter-Efficient Audio-Visual Learners
Dec 15, 2022



Vision transformers (ViTs) have achieved impressive results on various computer vision tasks in the last several years. In this work, we study the capability of frozen ViTs, pretrained only on visual data, to generalize to audio-visual data without finetuning any of its original parameters. To do so, we propose a latent audio-visual hybrid (LAVISH) adapter that adapts pretrained ViTs to audio-visual tasks by injecting a small number of trainable parameters into every layer of a frozen ViT. To efficiently fuse visual and audio cues, our LAVISH adapter uses a small set of latent tokens, which form an attention bottleneck, thus, eliminating the quadratic cost of standard cross-attention. Compared to the existing modality-specific audio-visual methods, our approach achieves competitive or even better performance on various audio-visual tasks while using fewer tunable parameters and without relying on costly audio pretraining or external audio encoders. Our code is available at https://genjib.github.io/project_page/LAVISH/
ECLIPSE: Efficient Long-range Video Retrieval using Sight and Sound
Apr 06, 2022

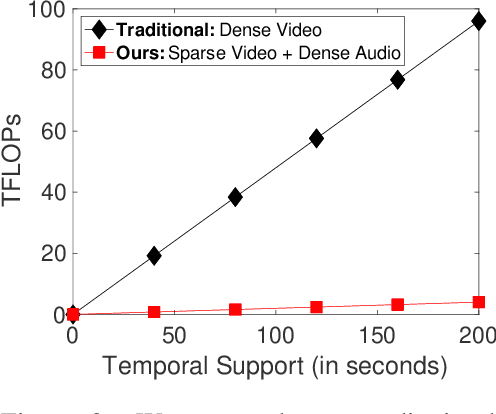
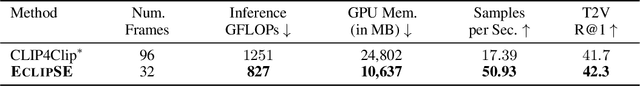
We introduce an audiovisual method for long-range text-to-video retrieval. Unlike previous approaches designed for short video retrieval (e.g., 5-15 seconds in duration), our approach aims to retrieve minute-long videos that capture complex human actions. One challenge of standard video-only approaches is the large computational cost associated with processing hundreds of densely extracted frames from such long videos. To address this issue, we propose to replace parts of the video with compact audio cues that succinctly summarize dynamic audio events and are cheap to process. Our method, named ECLIPSE (Efficient CLIP with Sound Encoding), adapts the popular CLIP model to an audiovisual video setting, by adding a unified audiovisual transformer block that captures complementary cues from the video and audio streams. In addition to being 2.92x faster and 2.34x memory-efficient than long-range video-only approaches, our method also achieves better text-to-video retrieval accuracy on several diverse long-range video datasets such as ActivityNet, QVHighlights, YouCook2, DiDeMo and Charades.
Exploiting Audio-Visual Consistency with Partial Supervision for Spatial Audio Generation
May 03, 2021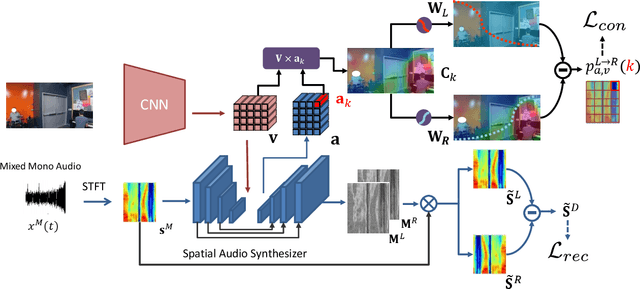
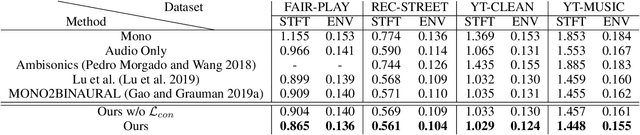


Human perceives rich auditory experience with distinct sound heard by ears. Videos recorded with binaural audio particular simulate how human receives ambient sound. However, a large number of videos are with monaural audio only, which would degrade the user experience due to the lack of ambient information. To address this issue, we propose an audio spatialization framework to convert a monaural video into a binaural one exploiting the relationship across audio and visual components. By preserving the left-right consistency in both audio and visual modalities, our learning strategy can be viewed as a self-supervised learning technique, and alleviates the dependency on a large amount of video data with ground truth binaural audio data during training. Experiments on benchmark datasets confirm the effectiveness of our proposed framework in both semi-supervised and fully supervised scenarios, with ablation studies and visualization further support the use of our model for audio spatialization.
Unsupervised Sound Localization via Iterative Contrastive Learning
Apr 01, 2021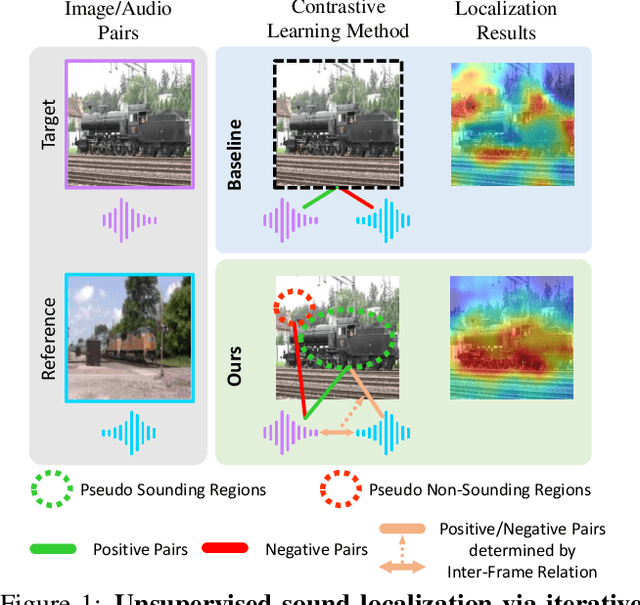
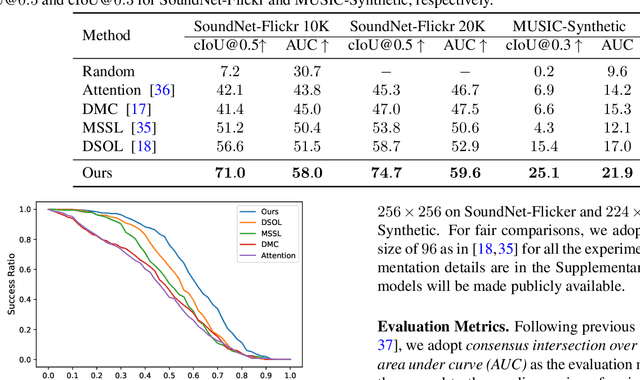

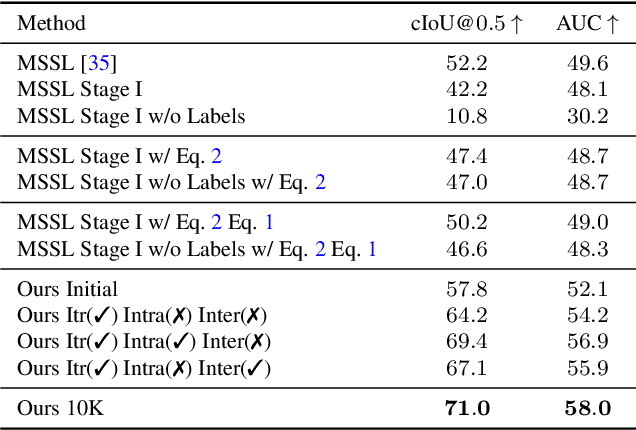
Sound localization aims to find the source of the audio signal in the visual scene. However, it is labor-intensive to annotate the correlations between the signals sampled from the audio and visual modalities, thus making it difficult to supervise the learning of a machine for this task. In this work, we propose an iterative contrastive learning framework that requires no data annotations. At each iteration, the proposed method takes the 1) localization results in images predicted in the previous iteration, and 2) semantic relationships inferred from the audio signals as the pseudo-labels. We then use the pseudo-labels to learn the correlation between the visual and audio signals sampled from the same video (intra-frame sampling) as well as the association between those extracted across videos (inter-frame relation). Our iterative strategy gradually encourages the localization of the sounding objects and reduces the correlation between the non-sounding regions and the reference audio. Quantitative and qualitative experimental results demonstrate that the proposed framework performs favorably against existing unsupervised and weakly-supervised methods on the sound localization task.