 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Audio-Visual Consistency with Partial Supervision for Spatial Audio Generation
Paper and Code
May 03, 2021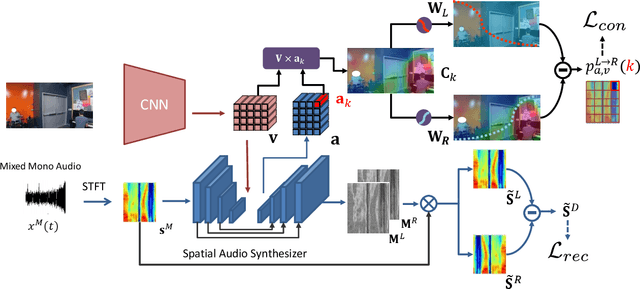
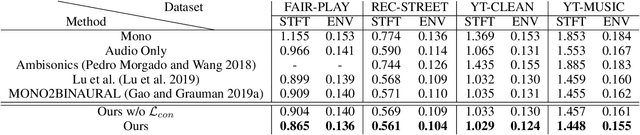


Human perceives rich auditory experience with distinct sound heard by ears. Videos recorded with binaural audio particular simulate how human receives ambient sound. However, a large number of videos are with monaural audio only, which would degrade the user experience due to the lack of ambient information. To address this issue, we propose an audio spatialization framework to convert a monaural video into a binaural one exploiting the relationship across audio and visual components. By preserving the left-right consistency in both audio and visual modalities, our learning strategy can be viewed as a self-supervised learning technique, and alleviates the dependency on a large amount of video data with ground truth binaural audio data during training. Experiments on benchmark datasets confirm the effectiveness of our proposed framework in both semi-supervised and fully supervised scenarios, with ablation studies and visualization further support the use of our model for audio spatialization.